Your test environment should be completely isolated from your production data. Testing on production is a recipe for disaster: you could delete real data, send test emails to real customers, or charge real credit cards. The solution is environment-specific configuration.
Using Environment Variables
Environment variables are the simplest and most secure way to manage different configs:
import os
# Read environment variable, use default if not set
DATABASE_HOST = os.getenv('DB_HOST', 'localhost')
DATABASE_PORT = int(os.getenv('DB_PORT', '5432'))
API_KEY = os.getenv('API_KEY') # No default - must be set
DEBUG_MODE = os.getenv('DEBUG', 'False').lower() == 'true'
print(f"Host: {DATABASE_HOST}")
print(f"Port: {DATABASE_PORT}")
print(f"Debug: {DEBUG_MODE}")
Output:
Host: localhost
Port: 5432
Debug: False
Using .env Files with python-dotenv
For development, load environment variables from a .env file:
A: Never! Add .env to .gitignore. Commit .env.example with dummy values so others know what variables are needed. This keeps secrets out of version control.
Q: Can I use environment variables for all settings?
A: Yes, but config files are often easier for complex setups. Use environment variables for secrets (API keys, passwords) and config files for regular settings.
Q: How do I test with a test database without affecting production?
A: Use an in-memory database or a separate test database for testing. Set ENV=testing to automatically use test configuration with no risk to production.
Q: What if I forget to set an environment variable?
A: Use defaults wisely. For critical values like DATABASE_URL, don’t provide defaults so the app fails loudly. For optional values, provide sensible defaults.
Q: How do I know which environment my code is running in?
A: Always have a way to check: print(os.getenv(‘ENV’)) or check your settings object. In Flask: app.config[‘DEBUG’] or app.config[‘ENV’]
Conclusion
Separating configuration by environment is a fundamental practice in professional software development. It protects your production data, makes testing safer, and allows different teams to work without stepping on each other’s toes. Use environment variables for secrets and configuration files for complex settings, and your code will be more flexible and secure.
One if-statement to rule them all: if os.getenv(‘ENV’) == ‘production’. Config switching, done.
The Pattern: Env Var Says Which Config to Load
The most reliable pattern across frameworks: read a single environment variable (APP_ENV or PYTHON_ENV) at startup, branch on it to load the right config file. Everything else flows from that one decision:
The trick: development and testing have safe defaults inline, but production REQUIRES the env var. os.environ["DATABASE_URL"] raises KeyError at startup if missing — fail-fast is exactly what you want in production.
Pydantic Settings — The Modern Approach
For real applications, hand-rolled config classes get unwieldy fast. pydantic-settings (the modern replacement for pydantic.BaseSettings) gives you type-checked config with automatic env-var loading, validation, and .env file support:
It loads from .env in dev, from real env vars in production, and the type annotations get validated at startup. secret_key with min_length=32 catches misconfigured staging where someone copy-pasted a short test value.
Secrets vs Config
Treat secrets (API keys, DB passwords, signing keys) differently from configuration (feature flags, timeouts, hostnames). Three rules:
Never commit secrets. Put them in .env (gitignored), in a secrets manager (AWS Secrets Manager, Vault, GCP Secret Manager), or in your platform’s encrypted-env-var feature.
Never log secrets. Add a __repr__ override that returns "" for any field marked as a secret. Pydantic v2 supports SecretStr for exactly this.
Rotate periodically. Secrets that never change are secrets that have been leaked. Build rotation into your config-loading code (multiple valid keys at once, with a deprecation window).
Common Pitfalls
Default-to-production.os.environ.get("APP_ENV", "production") is the opposite of what you want. Default to development so a forgotten env var in CI doesn’t accidentally point at the prod database.
Config drift between environments. A new feature flag added in dev but not staging means staging tests pass, prod breaks. Use a single Settings class with the same fields across envs; only the values differ.
Config loaded at module import time. If your settings = Settings() runs at import, you can’t override env vars in tests without re-importing the module. Wrap config in a function (get_settings()) and cache it lazily.
Reading env vars throughout the codebase. Scattered os.environ.get(...) calls make config hard to audit. Centralize all env-var access in one Settings class; the rest of the code imports from there.
No validation. A typo in a numeric setting (e.g., PORT="abc") shouldn’t fail when the first request arrives — it should fail at startup. Pydantic Settings gives you this for free.
FAQ
Q: .env file or real environment variables?
A: Both. .env for local development (never committed), real env vars in production via your platform’s secrets management. pydantic-settings reads from both transparently.
Q: How do I share config between Python and other services in my stack?
A: Use a portable format — env vars, JSON, or YAML — not a Python module. Then each service loads from the shared source. Resist the temptation to import config across language boundaries.
Q: What about feature flags?
A: Same Settings class can hold feature flags as booleans. For dynamic flags that change without redeployment, use a flag service like LaunchDarkly or Unleash — they’re worth it once you have more than 5-10 flags.
Q: How do I test config-dependent code?
A: Inject the config object rather than importing it. Tests pass a custom Settings instance with the values they need. pytest fixtures make this easy with autouse=True overrides.
Q: 12-factor app — do I have to do all twelve?
A: Config-in-environment is factor 3 and the one that matters most. The other eleven are great guidelines, but most teams gain 80% of the benefit just by getting config and secrets out of code.
Wrapping Up
Environment-driven config is one of those infrastructure habits that compounds: small now, life-saving when you’re trying to debug a production outage at 2 AM. Start with the APP_ENV pattern, move to pydantic-settings when the codebase grows, and never let secrets touch your git history. The setup cost is an hour; the lifetime cost of getting it wrong is incalculable.
How To Work With CSV Files in Python Using the csv Module and Pandas
Quick Example (TLDR)
Reading a CSV file with Python is simple. Here’s the fastest way using pandas:
# The quick way: pandas
import pandas as pd
# Read CSV file
df = pd.read_csv('data.csv')
# Access data
print(df.head())
print(df['column_name'].mean())
Output:
name age salary
0 Alice 28 65000
1 Bob 34 72000
2 Carol 29 68000
3 David 45 95000
4 Eve 31 71000
Understanding CSV Files
CSV stands for “Comma-Separated Values.” It’s the simplest way to store tabular data: each row is a line, columns are separated by commas. Here’s what a CSV file looks like inside:
Python’s built-in csv module is lightweight and doesn’t require external dependencies:
import csv
# Open and read CSV file
with open('employees.csv', 'r') as file:
# csv.reader returns an iterator over rows
csv_reader = csv.reader(file)
# Get the header row
headers = next(csv_reader)
print("Headers:", headers)
# Process each data row
for row in csv_reader:
print(f"Name: {row[0]}, Age: {row[1]}, Salary: {row[2]}")
DictReader automatically treats the first row as headers and returns dictionaries instead of lists:
import csv
# DictReader uses first row as keys
with open('employees.csv', 'r') as file:
dict_reader = csv.DictReader(file)
for row in dict_reader:
# Access by column name instead of index
print(f"{row['name']} earns $" + row['salary'] + " in " + row['department'])
Output:
Alice earns $65000 in Engineering
Bob earns $72000 in Sales
Carol earns $68000 in Engineering
David earns $95000 in Management
Writing CSV Files
Creating a CSV file is equally straightforward:
import csv
# Data to write
employees = [
{'name': 'Alice', 'age': 28, 'salary': 65000},
{'name': 'Bob', 'age': 34, 'salary': 72000},
{'name': 'Carol', 'age': 29, 'salary': 68000},
]
# Write to CSV
with open('new_employees.csv', 'w', newline='') as file:
fieldnames = ['name', 'age', 'salary']
writer = csv.DictWriter(file, fieldnames=fieldnames)
# Write header row
writer.writeheader()
# Write data rows
writer.writerows(employees)
print("File written successfully!")
Output:
File written successfully!
Working with Pandas for Advanced Operations
Pandas makes it much easier to filter, transform, and analyze data:
import pandas as pd
# Read CSV into DataFrame
df = pd.read_csv('employees.csv')
# Basic info about the data
print(f"Total rows: {len(df)}")
print(f"Average salary: ${df['salary'].mean():.2f}")
# Filter data: salaries above 70000
high_earners = df[df['salary'] > 70000]
print("
High earners:")
print(high_earners)
# Group by department
print("
Average salary by department:")
print(df.groupby('department')['salary'].mean())
Output:
Total rows: 4
Average salary: $75000.00
High earners:
name age salary department
1 Bob 34 72000 Sales
3 David 45 95000 Management
Average salary by department:
department
Engineering 66500.0
Management 95000.0
Sales 72000.0
Name: salary, dtype: float64
Handling Large CSV Files Efficiently
For massive files that don’t fit in memory, use chunking with pandas:
import pandas as pd
# Read large file in chunks
chunk_size = 10000
# Process file in batches
for chunk in pd.read_csv('huge_file.csv', chunksize=chunk_size):
# Process each chunk
print(f"Processing chunk with {len(chunk)} rows")
# Do something with the chunk
high_value = chunk[chunk['amount'] > 1000]
print(f"Found {len(high_value)} high-value transactions")
Output:
Processing chunk with 10000 rows
Found 2345 high-value transactions
Processing chunk with 10000 rows
Found 2412 high-value transactions
Processing chunk with 5234 rows
Found 1123 high-value transactions
Real-Life Example: Cleaning and Merging Sales Reports
Here’s a practical example of reading, cleaning, and merging sales data from multiple CSV files:
import pandas as pd
# Read sales data from multiple sources
sales_q1 = pd.read_csv('sales_q1.csv')
sales_q2 = pd.read_csv('sales_q2.csv')
# Combine the datasets
all_sales = pd.concat([sales_q1, sales_q2], ignore_index=True)
# Data cleaning: remove duplicates
all_sales = all_sales.drop_duplicates(subset=['order_id'])
print(f"After removing duplicates: {len(all_sales)} records")
# Clean: remove rows with missing values
all_sales = all_sales.dropna(subset=['customer_id', 'amount'])
print(f"After removing null values: {len(all_sales)} records")
# Transform: add new column for commission (5% of amount)
all_sales['commission'] = all_sales['amount'] * 0.05
# Filter: only successful orders (status='completed')
completed_sales = all_sales[all_sales['status'] == 'completed']
# Analysis: sales by region
print("
Sales by region:")
region_totals = completed_sales.groupby('region')['amount'].sum()
print(region_totals)
# Sort by amount and show top 10
top_sales = completed_sales.nlargest(5, 'amount')
print("
Top 5 sales:")
print(top_sales[['order_id', 'customer_name', 'amount', 'region']])
# Save cleaned data
all_sales.to_csv('cleaned_sales.csv', index=False)
print("
Cleaned data saved to cleaned_sales.csv")
Output:
After removing duplicates: 1997 records
After removing null values: 1985 records
Sales by region:
region
North 45230.50
South 38920.75
East 52340.25
West 41230.00
Name: amount, dtype: float64
Top 5 sales:
order_id customer_name amount region
5 ORD005 Acme Corp 8500.00 East
12 ORD012 TechStart 7200.50 North
18 ORD018 GlobalCo 6950.25 West
24 ORD024 InnovateLabs 6800.00 East
31 ORD031 CloudSys 6550.75 North
Cleaned data saved to cleaned_sales.csv
FAQ
Q: Should I use csv module or pandas?
A: Use csv for simple operations and to avoid dependencies. Use pandas when you need analysis, filtering, or complex transformations. Pandas makes data manipulation much easier and faster to code.
Q: How do I handle CSV files with different delimiters?
A: With csv module: csv.reader(file, delimiter=’;’) or with pandas: pd.read_csv(‘file.csv’, sep=’;’)
Q: What if my CSV has special characters or encoding issues?
A: Specify encoding: pd.read_csv(‘file.csv’, encoding=’utf-8′) or pd.read_csv(‘file.csv’, encoding=’latin-1′)
Q: Can I read CSV directly from a URL?
A: Yes! df = pd.read_csv(‘https://example.com/data.csv’) works directly with pandas.
Q: How do I export a pandas DataFrame to different formats?
A: DataFrame has methods for many formats: to_csv(), to_excel(), to_json(), to_html(), and more.
Conclusion
CSV files are everywhere in data work, and Python makes handling them simple. Start with the built-in csv module for basic needs, then graduate to pandas when you need real analysis power. The combination of these tools covers everything from simple data reading to complex transformations.
You have written a Python script that works perfectly when you run it with hardcoded values. But now you need to make it flexible — different filenames, different options, different modes — and you realize you cannot keep editing the source code every time. This is exactly the problem command line arguments solve, and every professional Python script uses them.
The good news is that Python gives you two built-in tools for handling command line arguments, and neither one requires installing anything extra. sys.argv gives you raw access to whatever the user typed after the script name, while argparse from the standard library builds a complete command line interface with help text, type validation, and error messages — all automatically.
In this tutorial, we will start with a quick working example, then cover how sys.argv works under the hood, build up to argparse for real-world CLI tools, and finish with a complete project that ties everything together. By the end, you will be able to turn any Python script into a proper command line tool that other people (and future you) can actually use without reading the source code.
Command Line Arguments in Python: Quick Example
Here is the fastest way to accept a command line argument in Python. Create this file and run it from your terminal:
# greet.py
import sys
if len(sys.argv) > 1:
name = sys.argv[1]
else:
name = "World"
print(f"Hello, {name}!")
sys.argv is a list where the first element (sys.argv[0]) is always the script name, and everything after that is what the user typed. We check if there is at least one extra argument with len(sys.argv) > 1, and if so, we use it as the name. If the user does not provide a name, we fall back to a default.
This works fine for simple scripts, but what if you need multiple arguments, optional flags, type checking, and help text? That is where argparse comes in — keep reading to see how it handles all of that automatically.
sys.argv[0] is always the script name. sys.argv[1] is where the fun begins.
What Are Command Line Arguments and Why Use Them?
Command line arguments are the extra words you type after a program name when you run it from a terminal. When you type python greet.py Alice, the string "Alice" is a command line argument. The operating system captures everything you typed, splits it by spaces, and hands the pieces to your program as a list of strings.
Think of it like ordering food at a restaurant. The script name is choosing the restaurant (you always need it), and the arguments are your specific order — what dish, how spicy, with or without sides. Without arguments, every customer gets the same default meal.
Here is how the two main approaches compare:
Feature
sys.argv
argparse
Import
import sys
import argparse
Type conversion
Manual (everything is a string)
Automatic (type=int)
Help text
You write it yourself
Generated automatically
Error handling
Manual checks and messages
Automatic with usage hints
Optional flags
Parse them yourself
Built-in (--verbose, -v)
Best for
Quick one-off scripts
Tools others will use
The rule of thumb is simple: use sys.argv when you are writing a script just for yourself and need one or two quick inputs. Switch to argparse the moment anyone else will run your script, or when you need more than two arguments. Let us start with sys.argv to understand the fundamentals.
How sys.argv Works in Python
sys.argv is a plain Python list that gets populated automatically when your script starts. Every element is a string, regardless of what the user typed. The first element is always the script name (or an empty string in interactive mode), and the rest are the arguments in the order they were typed.
# inspect_args.py
import sys
print(f"Script name: {sys.argv[0]}")
print(f"Number of arguments: {len(sys.argv) - 1}")
print(f"All arguments: {sys.argv[1:]}")
for i, arg in enumerate(sys.argv):
print(f" sys.argv[{i}] = {arg!r}")
Output:
$ python inspect_args.py hello 42 --verbose
Script name: inspect_args.py
Number of arguments: 3
All arguments: ['hello', '42', '--verbose']
sys.argv[0] = 'inspect_args.py'
sys.argv[1] = 'hello'
sys.argv[2] = '42'
sys.argv[3] = '--verbose'
Notice that 42 shows up as the string '42', not the integer 42. This is the most common gotcha with sys.argv — you must convert types yourself. If you try sys.argv[2] + 10 you will get a TypeError because Python will not automatically convert a string to a number.
Converting Argument Types Safely
Since every argument arrives as a string, you need to convert numbers, booleans, and other types explicitly. Always wrap conversions in a try/except block so your script does not crash with an ugly traceback when someone types the wrong thing:
# add_numbers.py
import sys
if len(sys.argv) != 3:
print("Usage: python add_numbers.py <num1> <num2>")
sys.exit(1)
try:
num1 = float(sys.argv[1])
num2 = float(sys.argv[2])
except ValueError:
print("Error: Both arguments must be numbers.")
sys.exit(1)
result = num1 + num2
print(f"{num1} + {num2} = {result}")
Output:
$ python add_numbers.py 3.5 2.1
3.5 + 2.1 = 5.6
$ python add_numbers.py three two
Error: Both arguments must be numbers.
$ python add_numbers.py 5
Usage: python add_numbers.py <num1> <num2>
The pattern here is important: check the argument count first, then try to convert types, and give the user a clear error message if anything goes wrong. sys.exit(1) tells the operating system that the script failed, which matters when your script is part of a larger automation pipeline.
Everything in sys.argv is a string. Type conversion is your job.
Getting Started with argparse
Once your script needs more than two arguments, or anyone besides you will run it, sys.argv becomes painful to maintain. You end up writing custom validation, usage messages, and flag parsing that argparse handles automatically. It is part of Python’s standard library, so there is nothing to install.
# greeter_v2.py
import argparse
parser = argparse.ArgumentParser(
description="Greet someone with a customizable message."
)
parser.add_argument("name", help="The name of the person to greet")
parser.add_argument(
"--greeting",
default="Hello",
help="The greeting to use (default: Hello)"
)
parser.add_argument(
"--shout",
action="store_true",
help="Print the greeting in uppercase"
)
args = parser.parse_args()
message = f"{args.greeting}, {args.name}!"
if args.shout:
message = message.upper()
print(message)
Output:
$ python greeter_v2.py Alice
Hello, Alice!
$ python greeter_v2.py Bob --greeting "Good morning" --shout
GOOD MORNING, BOB!
$ python greeter_v2.py --help
usage: greeter_v2.py [-h] [--greeting GREETING] [--shout] name
Greet someone with a customizable message.
positional arguments:
name The name of the person to greet
options:
-h, --help show this help message and exit
--greeting GREETING The greeting to use (default: Hello)
--shout Print the greeting in uppercase
With just a few lines of setup, you get automatic help text (--help), clear error messages for missing arguments, and a clean namespace object (args) instead of raw string parsing. The add_argument method handles positional arguments (required, no dashes), optional arguments (prefixed with --), and boolean flags (action="store_true").
Specifying Argument Types and Defaults
argparse can validate types automatically. Instead of manually wrapping everything in try/except, you tell the parser what type each argument should be and it handles the conversion and error messaging for you:
# power_calc.py
import argparse
parser = argparse.ArgumentParser(
description="Calculate base raised to a power."
)
parser.add_argument("base", type=float, help="The base number")
parser.add_argument("exponent", type=int, help="The exponent (integer)")
parser.add_argument(
"--precision",
type=int,
default=2,
help="Decimal places in output (default: 2)"
)
args = parser.parse_args()
result = args.base ** args.exponent
print(f"{args.base} ^ {args.exponent} = {result:.{args.precision}f}")
When you set type=float, argparse converts the string automatically and prints a helpful error if the conversion fails. You never have to write try/except for type validation again. The default parameter sets what value to use when the user does not provide an optional argument.
Limiting Choices and Adding Constraints
Sometimes you want the user to pick from a fixed set of options. The choices parameter restricts what values are accepted, and nargs controls how many values an argument takes:
# file_converter.py
import argparse
parser = argparse.ArgumentParser(
description="Convert files between formats."
)
parser.add_argument(
"files",
nargs="+",
help="One or more input files to convert"
)
parser.add_argument(
"--format",
choices=["csv", "json", "xml"],
default="json",
help="Output format (default: json)"
)
parser.add_argument(
"-v", "--verbose",
action="count",
default=0,
help="Increase output verbosity (-v, -vv, -vvv)"
)
args = parser.parse_args()
print(f"Converting {len(args.files)} file(s) to {args.format}")
print(f"Verbosity level: {args.verbose}")
for filename in args.files:
print(f" Processing: {filename}")
The nargs="+" means “one or more values” — the user can pass multiple filenames and they all get collected into a list. The choices parameter rejects anything not in the list. And action="count" lets users stack flags (-v, -vv, -vvv) for different verbosity levels, which is a common CLI pattern.
argparse turns your script into a proper control panel. –help is the user manual.
Building CLI Tools with Subcommands
Professional CLI tools like git, pip, and docker use subcommands — git commit, pip install, docker build. Each subcommand has its own set of arguments. argparse supports this pattern natively with subparsers:
# notes_cli.py
import argparse
import json
from pathlib import Path
NOTES_FILE = Path("notes.json")
def load_notes():
if NOTES_FILE.exists():
return json.loads(NOTES_FILE.read_text())
return []
def save_notes(notes):
NOTES_FILE.write_text(json.dumps(notes, indent=2))
def cmd_add(args):
notes = load_notes()
note = {"title": args.title, "body": args.body, "tag": args.tag}
notes.append(note)
save_notes(notes)
print(f"Added note: {args.title}")
def cmd_list(args):
notes = load_notes()
if args.tag:
notes = [n for n in notes if n.get("tag") == args.tag]
if not notes:
print("No notes found.")
return
for i, note in enumerate(notes, 1):
tag_str = f" [{note['tag']}]" if note.get("tag") else ""
print(f"{i}. {note['title']}{tag_str}")
def cmd_search(args):
notes = load_notes()
query = args.query.lower()
matches = [
n for n in notes
if query in n["title"].lower() or query in n["body"].lower()
]
print(f"Found {len(matches)} note(s) matching '{args.query}':")
for note in matches:
print(f" - {note['title']}")
# Build the argument parser
parser = argparse.ArgumentParser(
description="A simple command-line notes manager."
)
subparsers = parser.add_subparsers(dest="command", required=True)
# 'add' subcommand
add_parser = subparsers.add_parser("add", help="Add a new note")
add_parser.add_argument("title", help="Note title")
add_parser.add_argument("body", help="Note body text")
add_parser.add_argument("--tag", default="", help="Optional tag")
# 'list' subcommand
list_parser = subparsers.add_parser("list", help="List all notes")
list_parser.add_argument("--tag", help="Filter notes by tag")
# 'search' subcommand
search_parser = subparsers.add_parser("search", help="Search notes")
search_parser.add_argument("query", help="Search term")
args = parser.parse_args()
# Dispatch to the right function
commands = {"add": cmd_add, "list": cmd_list, "search": cmd_search}
commands[args.command](args)
Output:
$ python notes_cli.py add "Buy groceries" "Milk, eggs, bread" --tag shopping
Added note: Buy groceries
$ python notes_cli.py add "Fix login bug" "Users getting 403 on /dashboard" --tag work
Added note: Fix login bug
$ python notes_cli.py list
1. Buy groceries [shopping]
2. Fix login bug [work]
$ python notes_cli.py list --tag work
1. Fix login bug [work]
$ python notes_cli.py search groceries
Found 1 note(s) matching 'groceries':
- Buy groceries
$ python notes_cli.py --help
usage: notes_cli.py [-h] {add,list,search} ...
A simple command-line notes manager.
positional arguments:
{add,list,search}
add Add a new note
list List all notes
search Search notes
Each subcommand gets its own parser with its own arguments, and the dest="command" tells argparse to store which subcommand was chosen. The dispatch dictionary at the bottom routes to the right function. This is the same pattern that tools like pip and docker use internally.
One entry point, multiple subcommands. The CLI equivalent of a Swiss Army knife.
When to Use sys.argv vs argparse
Now that you have seen both approaches, here is a practical decision guide. The answer depends on who is running your script and how many arguments it needs:
Use sys.argv when: You are writing a quick personal script with 1-2 inputs, you want zero setup overhead, or you are doing something temporary like a one-time data migration script. It is also fine for scripts embedded in larger systems where the calling code always passes the right arguments.
Use argparse when: Anyone else will run your script, you need more than 2 arguments, you want --help to work automatically, you need type validation or choices, or your tool has subcommands. Once you have the pattern memorized, argparse adds maybe 10 extra lines of setup and saves you hours of debugging wrong inputs.
# decision_example.py
import sys
import argparse
# Quick sys.argv approach — fine for personal scripts
def quick_approach():
"""Simple: just grab the argument or use a default."""
filename = sys.argv[1] if len(sys.argv) > 1 else "data.txt"
print(f"Processing: {filename}")
# argparse approach — better for shared tools
def robust_approach():
"""Robust: automatic help, type checking, error messages."""
parser = argparse.ArgumentParser(
description="Process a data file with options."
)
parser.add_argument("filename", help="Path to the data file")
parser.add_argument(
"--limit", type=int, default=100,
help="Maximum rows to process (default: 100)"
)
args = parser.parse_args()
print(f"Processing: {args.filename} (limit: {args.limit} rows)")
# Uncomment the one you want to test:
# quick_approach()
robust_approach()
Both approaches work. The difference is what happens when something goes wrong — argparse gives the user a clear path forward, while raw sys.argv leaves them guessing.
Real-Life Example: Building a File Organizer CLI
Ten lines of argparse config replace a hundred lines of manual string parsing.
Let us build a practical tool that organizes files in a directory by their extension. This combines everything we have covered — positional arguments, optional flags, type validation, and real file system operations:
# organize_files.py
import argparse
import shutil
from pathlib import Path
from collections import defaultdict
# Map extensions to category folder names
CATEGORIES = {
".jpg": "Images", ".jpeg": "Images", ".png": "Images",
".gif": "Images", ".svg": "Images", ".webp": "Images",
".pdf": "Documents", ".doc": "Documents", ".docx": "Documents",
".txt": "Documents", ".xlsx": "Documents", ".csv": "Documents",
".py": "Code", ".js": "Code", ".html": "Code", ".css": "Code",
".zip": "Archives", ".tar": "Archives", ".gz": "Archives",
".mp4": "Videos", ".mov": "Videos", ".avi": "Videos",
".mp3": "Music", ".wav": "Music", ".flac": "Music",
}
def organize(directory, dry_run=False, verbose=False):
"""Move files into category subfolders based on extension."""
source = Path(directory)
if not source.is_dir():
print(f"Error: '{directory}' is not a valid directory.")
return
moved = defaultdict(list)
for filepath in source.iterdir():
if filepath.is_file():
ext = filepath.suffix.lower()
category = CATEGORIES.get(ext, "Other")
target_dir = source / category
if dry_run:
print(f" [DRY RUN] {filepath.name} -> {category}/")
moved[category].append(filepath.name)
else:
target_dir.mkdir(exist_ok=True)
destination = target_dir / filepath.name
shutil.move(str(filepath), str(destination))
moved[category].append(filepath.name)
if verbose:
print(f" Moved {filepath.name} -> {category}/")
# Print summary
total = sum(len(files) for files in moved.values())
print(f"\n{'[DRY RUN] ' if dry_run else ''}Organized {total} files:")
for category, files in sorted(moved.items()):
print(f" {category}: {len(files)} file(s)")
parser = argparse.ArgumentParser(
description="Organize files in a directory by type."
)
parser.add_argument(
"directory",
help="Path to the directory to organize"
)
parser.add_argument(
"--dry-run",
action="store_true",
help="Show what would happen without moving files"
)
parser.add_argument(
"-v", "--verbose",
action="store_true",
help="Print each file as it is moved"
)
args = parser.parse_args()
organize(args.directory, dry_run=args.dry_run, verbose=args.verbose)
This tool uses argparse for clean argument handling, pathlib for cross-platform file paths, and a dictionary-based category system that is easy to extend. The --dry-run flag is especially important — it lets the user preview what will happen before any files actually move. You can extend this by adding a --category flag to organize only specific types, or a --recursive flag to handle nested folders.
Frequently Asked Questions
What is the difference between argv and argc in Python?
In C, argv is the array of argument strings and argc is the count of arguments. Python combines both into sys.argv — it is a list, so you get the count with len(sys.argv). There is no separate argc variable in Python because lists already know their own length.
What does sys.argv[0] contain?
sys.argv[0] is always the script name or path, depending on how you ran it. If you run python myscript.py, it will be 'myscript.py'. If you run python /home/user/myscript.py, it will be '/home/user/myscript.py'. In an interactive Python session or with -c, it will be an empty string or '-c'.
How do I pass arguments that contain spaces?
Wrap the argument in quotes when calling the script: python script.py "hello world". The shell treats everything inside quotes as a single argument, so sys.argv[1] will be 'hello world' (one string, not two). This works with both single and double quotes on most systems.
How do I make an argparse argument required?
Positional arguments (no dashes) are required by default. For optional arguments (with --), add required=True to add_argument(): parser.add_argument("--config", required=True). However, if an argument is truly required, consider making it positional instead — that is the conventional approach for CLI tools.
How do I handle boolean flags with argparse?
Use action="store_true" for flags that default to False and become True when present: parser.add_argument("--verbose", action="store_true"). The user just types --verbose with no value. For the opposite pattern (default True, flag turns it off), use action="store_false" with a name like --no-color.
Can I make two arguments mutually exclusive?
Yes, use parser.add_mutually_exclusive_group(). Add the conflicting arguments to the group instead of directly to the parser. If the user passes both, argparse will print an error. This is useful for flags like --json vs --csv where only one output format should be active.
Conclusion
You now have two solid tools for handling command line arguments in Python. sys.argv gives you raw, immediate access for quick scripts — just remember that everything is a string and you need to handle errors yourself. argparse gives you a complete CLI framework with automatic help text, type validation, choices, subcommands, and clean error messages, all from the standard library.
Try extending the file organizer project with new features: add a --undo subcommand that moves files back to the parent directory, or a --config flag that loads custom category mappings from a JSON file. These are the kinds of incremental improvements that turn a tutorial exercise into a tool you actually use every day.
Environment variables keep sensitive data like API keys and database passwords out of your code. Python’s os.environ reads them, and python-dotenv loads them from a .env file.
#quick_example.py
import os
from dotenv import load_dotenv # pip install python-dotenv
load_dotenv() # reads .env file into environment variables
api_key = os.environ.get('API_KEY', 'not-set') # get with a fallback
db_host = os.environ.get('DB_HOST', 'localhost')
print(f"API Key: {api_key[:8]}...") # only show first 8 chars
print(f"DB Host: {db_host}")
Output:
API Key: sk-abc12...
DB Host: db.example.com
The load_dotenv() function reads key-value pairs from a .env file and makes them available through os.environ. Your secrets stay out of your codebase.
Why Environment Variables Matter for Python Developers
Hardcoding secrets into your source code is one of the most common security mistakes developers make. Push your code to GitHub with an API key embedded and bots will find it within minutes — that’s not an exaggeration. Environment variables solve this by keeping configuration separate from code. Different environments (dev, staging, production) can use different values without changing a single line of Python.
Using os.environ to Read Environment Variables in Python
Python’s built-in os module gives you direct access to environment variables through os.environ, which behaves like a dictionary.
#os_environ.py
import os
# Read an environment variable (raises KeyError if missing)
# home = os.environ['HOME']
# Safer: use .get() with a default value
home = os.environ.get('HOME', '/tmp')
user = os.environ.get('USER', 'unknown')
path = os.environ.get('PATH', '')
print(f"Home: {home}")
print(f"User: {user}")
print(f"PATH entries: {len(path.split(':'))}")
# Check if a variable exists
if 'API_KEY' in os.environ:
print("API_KEY is set")
else:
print("API_KEY is NOT set — using defaults")
Output:
Home: /home/user
User: user
PATH entries: 8
API_KEY is NOT set — using defaults
Always use .get() with a default value instead of direct dictionary access. If the variable doesn’t exist, os.environ['KEY'] throws a KeyError that will crash your script.
Creating a .env File for Your Python Project
A .env file is a simple text file with key-value pairs. Create it in your project root:
Note: Lines starting with # are comments. No quotes needed around values unless they contain spaces. No spaces around the = sign.
Installing and Using python-dotenv
pip install python-dotenv
Once installed, load_dotenv() reads your .env file and loads each variable into os.environ:
#using_dotenv.py
import os
from dotenv import load_dotenv
# Load .env file from the current directory (or specify a path)
load_dotenv() # looks for .env in current dir and parent dirs
# Now all .env variables are available via os.environ
db_config = {
'host': os.environ.get('DB_HOST'),
'port': int(os.environ.get('DB_PORT', 5432)),
'name': os.environ.get('DB_NAME'),
'user': os.environ.get('DB_USER'),
'password': os.environ.get('DB_PASSWORD'),
}
print(f"Connecting to {db_config['name']}@{db_config['host']}:{db_config['port']}")
print(f"Debug mode: {os.environ.get('DEBUG')}")
Output:
Connecting to myapp@db.example.com:5432
Debug mode: True
By default, load_dotenv() won’t overwrite existing environment variables. If you need to override them (for testing), pass override=True.
Keeping Secrets Out of Git With .gitignore
The whole point of using .env files is to keep secrets out of version control. Add .env to your .gitignore immediately:
Create a .env.example file that shows the required variables without actual values. Commit this to Git so other developers know what to set up:
# .env.example — copy to .env and fill in your values
DB_HOST=
DB_PORT=5432
DB_NAME=
DB_USER=
DB_PASSWORD=
API_KEY=
DEBUG=False
Validating Environment Variables at Startup
Don’t wait until your app crashes halfway through to discover a missing variable. Validate everything at startup.
#validate_env.py
import os
import sys
from dotenv import load_dotenv
load_dotenv()
REQUIRED_VARS = ['DB_HOST', 'DB_NAME', 'DB_USER', 'DB_PASSWORD', 'API_KEY']
missing = [var for var in REQUIRED_VARS if not os.environ.get(var)]
if missing:
print(f"ERROR: Missing required environment variables: {', '.join(missing)}")
print("Copy .env.example to .env and fill in the values")
sys.exit(1)
print("All required environment variables are set")
Output (when variables are missing):
ERROR: Missing required environment variables: API_KEY
Copy .env.example to .env and fill in the values
Real-Life Example: A Database Connection Manager
Here’s a practical example that combines everything — loading config from .env, validating required variables, and creating a reusable database configuration class.
#db_manager.py
import os
import sys
from dotenv import load_dotenv
from dataclasses import dataclass
load_dotenv()
@dataclass
class DatabaseConfig:
host: str
port: int
name: str
user: str
password: str
ssl: bool = True
@classmethod
def from_env(cls):
"""Create config from environment variables"""
required = ['DB_HOST', 'DB_NAME', 'DB_USER', 'DB_PASSWORD']
missing = [v for v in required if not os.environ.get(v)]
if missing:
print(f"Missing DB config: {', '.join(missing)}")
sys.exit(1)
return cls(
host=os.environ['DB_HOST'],
port=int(os.environ.get('DB_PORT', 5432)),
name=os.environ['DB_NAME'],
user=os.environ['DB_USER'],
password=os.environ['DB_PASSWORD'],
ssl=os.environ.get('DB_SSL', 'true').lower() == 'true'
)
@property
def connection_string(self):
ssl_param = '?sslmode=require' if self.ssl else ''
return f"postgresql://{self.user}:{self.password}@{self.host}:{self.port}/{self.name}{ssl_param}"
# Usage
config = DatabaseConfig.from_env()
print(f"Database: {config.name}")
print(f"Host: {config.host}:{config.port}")
print(f"SSL: {config.ssl}")
# In production, you'd pass config.connection_string to your ORM
print(f"Connection string ready (password hidden)")
This pattern gives you type-safe configuration, validation at startup, sensible defaults, and a clean connection string builder — all powered by a simple .env file.
load_dotenv() in dev, real env vars in prod. Same code, zero config changes.
Frequently Asked Questions
What is the difference between os.environ and os.getenv() in Python?
os.environ.get('KEY') and os.getenv('KEY') are functionally identical — both return None if the variable is missing. The only difference is os.environ['KEY'] (without .get) raises a KeyError, while os.getenv always returns the default.
Can I use .env files in production?
You can, but most production deployments set environment variables directly through the hosting platform (Heroku config vars, AWS Parameter Store, Docker environment). The .env file is primarily a development convenience.
Does python-dotenv work with Django and Flask?
Yes. Flask has built-in .env support with python-dotenv. For Django, call load_dotenv() at the top of your settings.py before referencing any os.environ calls.
Conclusion
Environment variables are the right way to manage configuration and secrets in Python. Use python-dotenv for local development, validate required variables at startup, never commit .env to Git, and provide a .env.example for your team. It takes five minutes to set up and saves you from a world of security headaches.
Python’s requests library makes calling REST APIs dead simple. Install it with pip install requests and you can make HTTP calls in one line.
#quick_example.py
import requests # pip install requests
# Make a GET request to a public API
response = requests.get('https://jsonplaceholder.typicode.com/posts/1')
data = response.json() # parse the JSON response into a dict
print(data['title']) # access specific fields
print(response.status_code) # check the HTTP status code
Output:
sunt aut facere repellat provident occaecati excepturi optio reprehenderit
200
The response.json() method converts the API’s JSON response directly into a Python dictionary. The status code 200 means everything went smoothly.
Auth tokens in headers. Never in URLs. Never in code.
What is a REST API and Why Should You Care
A REST API is how two programs talk to each other over the internet. When you check the weather on your phone, your app is calling a weather API behind the scenes. When you log into a website using Google, that’s an API call too. As a Python developer, knowing how to call APIs opens up a world of data — weather, stock prices, social media, payment processing, you name it.
Python’s requests library is the gold standard for making HTTP calls. It wraps all the complexity of HTTP into a clean, readable interface.
Installing the Requests Library
The requests library doesn’t come with Python — you need to install it:
pip install requests
Or if you’re on Linux/Mac and need sudo:
sudo pip3 install requests
Making GET Requests With Query Parameters
GET requests are for fetching data. Most APIs accept query parameters to filter or customize the response. You can pass them as a dictionary using the params argument instead of manually building the URL string.
#get_with_params.py
import requests
# Pass query parameters as a dictionary — much cleaner than building the URL
params = {
'userId': 1,
'completed': 'false'
}
response = requests.get(
'https://jsonplaceholder.typicode.com/todos',
params=params # requests builds the URL for you
)
todos = response.json() # list of todo items
print(f"Found {len(todos)} incomplete todos")
print(f"First todo: {todos[0]['title']}")
Output:
Found 11 incomplete todos
First todo: delectus aut autem
The params dictionary gets converted into a query string like ?userId=1&completed=false and appended to the URL automatically. This is safer and cleaner than string concatenation.
POST Requests With JSON Body in Python
POST requests send data to an API — creating new records, submitting forms, or triggering actions. Use the json parameter to send a Python dictionary as a JSON body.
#post_request.py
import requests
# Data to send — requests will serialize this to JSON automatically
new_post = {
'title': 'My API Post',
'body': 'This was created with Python requests',
'userId': 1
}
response = requests.post(
'https://jsonplaceholder.typicode.com/posts',
json=new_post # automatically sets Content-Type: application/json
)
print(f"Status: {response.status_code}") # 201 = created
print(f"New post ID: {response.json()['id']}")
Output:
Status: 201
New post ID: 101
Status code 201 means the resource was created successfully. The API returns the newly created object with its assigned ID.
Authentication Methods for Python API Calls
Most real-world APIs require authentication. Here are the three most common methods you’ll encounter.
API Key in Headers
#api_key_auth.py
import requests
headers = {
'X-API-Key': 'your_api_key_here' # some APIs use different header names
}
response = requests.get('https://api.example.com/data', headers=headers)
print(response.status_code)
#basic_auth.py
import requests
# requests has built-in support for Basic Auth
response = requests.get(
'https://api.example.com/account',
auth=('username', 'password') # tuple of (user, pass)
)
print(response.status_code)
Note: Never hardcode API keys or tokens directly in your code. Use environment variables or a .env file instead. Check out our article on managing environment variables with dotenv for the proper approach.
Bearer vs Basic vs OAuth. Pick one, document it.
Handling API Errors and Status Codes in Python
APIs don’t always return what you expect. Network issues, invalid data, rate limits — things go wrong. Proper error handling separates production code from tutorial code.
#error_handling.py
import requests
def safe_api_call(url):
try:
response = requests.get(url, timeout=10) # always set a timeout
response.raise_for_status() # raises exception for 4xx/5xx codes
return response.json()
except requests.exceptions.Timeout:
print("Request timed out — the server took too long to respond")
except requests.exceptions.HTTPError as e:
print(f"HTTP error: {e.response.status_code} - {e.response.reason}")
except requests.exceptions.ConnectionError:
print("Connection failed — check your internet or the URL")
except requests.exceptions.JSONDecodeError:
print("Response wasn't valid JSON")
return None
# Test with a valid URL
data = safe_api_call('https://jsonplaceholder.typicode.com/posts/1')
if data:
print(f"Got: {data['title'][:40]}...")
# Test with a URL that returns 404
data = safe_api_call('https://jsonplaceholder.typicode.com/posts/99999')
Output:
Got: sunt aut facere repellat provident MDash...
HTTP error: 404 - Not Found
The raise_for_status() method is your best friend. It throws an exception for any 4xx or 5xx status code, so you don’t accidentally process error responses as valid data.
Working With Response Headers and Pagination
Many APIs return data in pages. You need to check the response headers or body for pagination info and loop through all pages to get the complete dataset.
#pagination.py
import requests
def get_all_posts(base_url):
all_posts = []
page = 1
while True:
response = requests.get(base_url, params={'_page': page, '_limit': 10})
posts = response.json()
if not posts: # empty list means no more pages
break
all_posts.extend(posts)
print(f"Page {page}: got {len(posts)} posts")
page += 1
return all_posts
posts = get_all_posts('https://jsonplaceholder.typicode.com/posts')
print(f"\nTotal posts collected: {len(posts)}")
Real-Life Example: Building a Weather Dashboard Script
Let’s put it all together with a practical script that fetches weather data from the Open-Meteo API (free, no API key needed) and displays a simple dashboard.
#weather_dashboard.py
import requests
from datetime import datetime
def get_weather(city_lat, city_lon, city_name):
"""Fetch current weather for a location using Open-Meteo API"""
url = 'https://api.open-meteo.com/v1/forecast'
params = {
'latitude': city_lat,
'longitude': city_lon,
'current_weather': True, # get current conditions
'timezone': 'auto' # detect timezone from coordinates
}
try:
response = requests.get(url, params=params, timeout=10)
response.raise_for_status()
data = response.json()
weather = data['current_weather']
return {
'city': city_name,
'temp': weather['temperature'],
'wind': weather['windspeed'],
'time': weather['time']
}
except requests.exceptions.RequestException as e:
print(f"Failed to get weather for {city_name}: {e}")
return None
# Define cities with their coordinates
cities = [
(-33.87, 151.21, 'Sydney'),
(51.51, -0.13, 'London'),
(40.71, -74.01, 'New York'),
(35.68, 139.69, 'Tokyo'),
]
# Fetch and display weather for all cities
print("=" * 45)
print(" WEATHER DASHBOARD")
print("=" * 45)
for lat, lon, name in cities:
w = get_weather(lat, lon, name)
if w:
print(f" {w['city']:12s} | {w['temp']:5.1f} C | Wind: {w['wind']} km/h")
print("=" * 45)
print(f" Updated: {datetime.now().strftime('%Y-%m-%d %H:%M')}")
Output:
=============================================
WEATHER DASHBOARD
=============================================
Sydney | 22.3 C | Wind: 15.2 km/h
London | 8.1 C | Wind: 20.5 km/h
New York | 11.7 C | Wind: 12.8 km/h
Tokyo | 16.4 C | Wind: 8.3 km/h
=============================================
Updated: 2026-03-13 09:15
This script demonstrates GET requests with query parameters, response parsing, error handling with timeouts, and looping through multiple API calls. You could easily extend it with a scheduler to run every hour or save results to a CSV for tracking trends over time.
response.raise_for_status() — one line between you and a silent 404 ruining everything.
Frequently Asked Questions
What is the difference between requests.get() and requests.post() in Python?
GET fetches data from a server without changing anything. POST sends data to create or update a resource. Use GET when you’re reading, POST when you’re writing. Some APIs also use PUT for updates and DELETE for removals.
How do I send form data instead of JSON with Python requests?
Use the data parameter instead of json: requests.post(url, data={'key': 'value'}). This sends the data as application/x-www-form-urlencoded, which is what HTML forms use.
Should I use requests or urllib for API calls in Python?
requests is almost always the better choice. While urllib is built-in, its API is verbose and harder to use. The requests library handles cookies, sessions, redirects, and encoding automatically.
How do I handle API rate limits with Python requests?
Check the response headers for rate limit info (usually X-RateLimit-Remaining and Retry-After). If you get a 429 status code, wait the specified time before retrying. For robust solutions, use exponential backoff with the tenacity library.
Conclusion
The requests library gives you everything you need to interact with REST APIs in Python — from simple GET calls to authenticated POST requests with error handling. The key patterns to remember are: always set a timeout, use raise_for_status() for error detection, and never hardcode credentials. With these fundamentals, you can integrate almost any web service into your Python projects.
Building user authentication from scratch sounds like a good idea until you’re three weeks in, wrestling with password hashing edge cases, session management bugs, and the nagging realization that you’ve probably missed half the security best practices. Authentication is deceptively complex — you need to handle password resets, token expiration, email verification, brute-force protection, and compliance with frameworks like GDPR and SOC 2. Most Python developers who’ve built auth systems manually can tell you: it’s a massive rabbit hole that distracts from your actual product.
The good news? You don’t have to build it yourself anymore. A growing number of Python developers are abandoning custom authentication in favor of no-code authentication services — third-party platforms that handle all the heavy lifting. These services let you add enterprise-grade authentication to your Python web applications in minutes, not months, without writing a single line of password validation logic or worrying about whether your security implementation is bulletproof.
In this guide, we’ll explore why no-code authentication has become the default choice for modern Python developers, how it works, and which services actually deliver on their promises. By the end, you’ll understand when to use these services and when (if ever) rolling your own auth actually makes sense.
What is No-Code Authentication?
No-code authentication refers to third-party platforms that provide complete user authentication and identity management without requiring you to build the infrastructure yourself. Instead of storing passwords in your database, validating credentials, managing sessions, and implementing security protocols, you delegate all of this to a specialized service. Your application communicates with the authentication service via APIs or SDKs, and the service handles the heavy lifting.
These platforms operate on a simple principle: authentication is so critical to security that it deserves specialized infrastructure. They invest heavily in compliance certifications, security audits, penetration testing, and infrastructure redundancy — things that are expensive and time-consuming for individual developers to maintain. By using a dedicated service, you inherit that mature security posture immediately.
The flow is straightforward. A user visits your Python application and attempts to log in. Instead of your app checking a password hash against your database, your app redirects the user to the authentication service’s login page. The service handles the login, issues tokens or sessions, and redirects the user back to your app. Your app then trusts those tokens to grant access to protected resources. From your Python code’s perspective, you’re just validating tokens and reading user claims — the hard parts are gone.
Auth is hard. Letting someone else handle it is easy.
Quick Example: Flask + Auth0
Here’s a minimal Flask application using Auth0 for authentication:
That’s it. The service handles password validation, token management, multi-factor authentication, and all the compliance headaches. Your app just needs to validate the token and read the user’s claims.
Rolling Your Own Auth vs No-Code Services
Let’s be direct about the tradeoffs. Building authentication yourself gives you complete control and customization options. You can design the exact user experience you want, integrate with proprietary identity systems, and avoid third-party dependencies. But control comes at a cost.
Factor
Roll Your Own Auth
No-Code Auth Service
Development Time
4-8 weeks minimum
30 minutes to 1 week
Security Compliance
Your responsibility, risky
SOC 2, GDPR, HIPAA certified
Password Storage
You manage hashing, salts
Provider handles securely
Token Management
Session handling, expiration logic
Automatic token lifecycle
Multi-Factor Auth
Build from scratch
Included out of the box
Social Login
Integrate each provider separately
Pre-built integrations
Breach Monitoring
Not typically implemented
Included, active alerts
Customization
Complete flexibility
Templated, some limits
Maintenance Burden
Ongoing patches, security updates
Managed by provider
Cost
Developer time (expensive)
$0-500/month depending on scale
For most Python developers and teams, the comparison is clear. The cost of building and maintaining auth incorrectly far exceeds the cost of a third-party service.
Don’t roll your own crypto. Don’t roll your own auth either.
Top No-Code Authentication Services for Python
Auth0
Auth0 is the enterprise standard for no-code authentication. It provides comprehensive identity management, supports 30+ identity providers (Google, GitHub, Okta, Salesforce, etc.), and includes advanced features like passwordless authentication, risk-based access control, and detailed audit logs. For Python developers, Auth0 offers excellent SDK support via the authlib library and direct REST API access. The platform is SOC 2 certified and supports OAuth2, OpenID Connect, and SAML. Auth0’s pricing starts free for development and scales to $1,000+ per month for enterprise deployments.
Firebase Authentication
Firebase Auth is Google’s simplified authentication service, tightly integrated with the Firebase ecosystem. It’s lighter-weight than Auth0 and excels at rapid prototyping. Firebase supports email/password, phone authentication, and social login. For Python backends, you can verify Firebase tokens and manage users via their Admin SDK. The learning curve is shallow, and pricing is very reasonable — you pay for usage, typically under $100/month unless you’re at scale. Firebase Auth is ideal if you’re already invested in Google Cloud Platform or need quick, low-maintenance authentication.
Clerk
Clerk is a newer entrant focused on developer experience. It emphasizes pre-built authentication UI components and seamless session management. Clerk supports email, phone, OAuth (Google, GitHub, Apple), and passkeys. The platform includes organizational support out of the box, making it valuable for B2B applications. For Python backends, Clerk provides webhooks for user lifecycle events and middleware libraries for FastAPI and Flask. Clerk’s free tier is generous, and paid plans start around $99/month. It’s growing rapidly among startups and indie developers.
Supabase Auth
Supabase Auth is PostgreSQL-native and built on GoTrue (an open-source authentication service). If your Python application already uses Supabase for the database, adding auth is seamless — users are stored in a dedicated auth schema in your own database. Supabase supports email/password, OAuth, passwordless login, and magic links. For Python developers, Supabase provides the supabase-py SDK and REST API access. The major advantage is control — user data stays in your database, not a third-party silo. Pricing is based on usage and very affordable at scale.
Key Benefits for Python Developers
Security You Can’t Hack
Third-party auth services employ teams of security engineers, cryptographers, and compliance specialists. They undergo regular penetration testing, maintain bug bounty programs, and achieve certifications like SOC 2 and GDPR compliance. As an individual developer, achieving the same level of security would require thousands of hours and deep cryptographic expertise. When you use a no-code service, you’re inheriting a security posture that would cost your company hundreds of thousands of dollars to replicate.
Reclaim Weeks of Development Time
Authentication isn’t a differentiator for most applications. Your users don’t care if you built the login system yourself or outsourced it. What they care about is that it works reliably and securely. By using a no-code service, you redirect weeks of development effort toward features that actually move the needle — your product’s core value proposition. A typical auth implementation takes 4-8 weeks of developer time. A third-party service gets you to launch in hours.
Compliance Made Manageable
GDPR, HIPAA, SOC 2, CCPA — modern applications must meet increasingly complex compliance requirements. These standards demand careful handling of user data, audit trails, data retention policies, and security controls. Reputable auth services are already certified for these frameworks. Using them doesn’t eliminate your compliance responsibilities, but it dramatically simplifies them. You’re not starting from scratch trying to understand what GDPR requires of user authentication.
Automatic Scalability
Building auth at small scale is different from auth at large scale. At 1,000 users, a simple password database works fine. At 1 million users, you need distributed databases, caching layers, rate limiting, DDoS protection, and redundancy across regions. Third-party services handle this complexity invisibly. Your application scales from hobby project to enterprise system without changing how you call the auth API.
OAuth: a dance where four parties never trust each other.
When to Build Your Own Authentication
Despite the overwhelming advantages of no-code services, there are legitimate scenarios where building custom auth makes sense. Be honest with yourself: you probably don’t have one of these reasons.
Extreme Customization Needs: If your authentication flow requires unconventional user workflows (like a game with progression-based access gates or a specialized medical application with role-based biology), you might need custom logic. Even then, you can often layer custom logic on top of a third-party provider rather than replacing it entirely.
Regulatory Isolation Mandate: Some regulated industries require complete data sovereignty. A hospital system might be legally required to store patient authentication data exclusively within a private data center. In that case, running your own auth server (hardened and based on proven open-source code, not from scratch) is sometimes necessary.
Offline-First Application: If your Python application runs offline with intermittent connectivity (like a mobile app or field tool), a third-party auth service won’t help you validate users without internet. You’ll need to build local authentication with cached credentials. But even then, you can sync to third-party auth when connectivity returns.
Zero External Dependencies: Some organizations have architectural policies against third-party dependencies for security or liability reasons. If your company forbids external SaaS, you have no choice but to build your own. Understand that this decision extracts a real cost in engineering time and risk.
For everyone else? Use a third-party service and ship your product faster.
Real-Life Example: Django + Clerk
Let’s look at a more complete example using Django and Clerk, showing how to implement protected routes and user profile management:
import os
import requests
from functools import wraps
from django.shortcuts import redirect
from django.http import JsonResponse
from django.conf import settings
CLERK_API_KEY = os.getenv('CLERK_API_KEY')
CLERK_DOMAIN = os.getenv('CLERK_DOMAIN')
def require_clerk_auth(view_func):
@wraps(view_func)
def wrapped_view(request, *args, **kwargs):
auth_header = request.headers.get('Authorization', '')
if not auth_header.startswith('Bearer '):
return JsonResponse({'error': 'Unauthorized'}, status=401)
token = auth_header.split(' ')[1]
headers = {
'Authorization': f'Bearer {CLERK_API_KEY}',
'Content-Type': 'application/json'
}
response = requests.get(
f'{CLERK_DOMAIN}/api/v1/tokens/decode',
params={'token': token},
headers=headers
)
if response.status_code != 200:
return JsonResponse({'error': 'Invalid token'}, status=401)
request.clerk_user = response.json()
return view_func(request, *args, **kwargs)
return wrapped_view
# views.py
from django.http import JsonResponse
from django.views.decorators.http import require_http_methods
@require_http_methods(["GET"])
@require_clerk_auth
def get_profile(request):
user_id = request.clerk_user.get('sub')
return JsonResponse({
'user_id': user_id,
'email': request.clerk_user.get('email'),
'created_at': request.clerk_user.get('iat')
})
@require_http_methods(["POST"])
@require_clerk_auth
def update_profile(request):
user_id = request.clerk_user.get('sub')
data = request.POST
# Update user in your database
# (authenticate via Clerk token above)
return JsonResponse({'status': 'updated'})
This example uses Clerk’s token validation endpoint to secure Django views. The decorator extracts the token from the Authorization header, validates it with Clerk’s API, and attaches the decoded user information to the request. Your view then has access to authenticated user data without ever touching passwords or sessions.
Frequently Asked Questions
How much does no-code authentication cost?
Most services offer free tiers for development and small projects. Auth0 starts free with limited features, Firebase Auth charges per identity verification (typically $0.01-$0.05 per auth event), and Clerk offers a generous free tier up to 5,000 monthly active users. For production applications, expect $20-500/month depending on user volume and features. This is almost always cheaper than the developer time required to build your own system.
Am I locked into a vendor?
Switching auth providers is possible but requires refactoring code. Your application code is tightly integrated with your chosen provider’s SDK and API. However, the integration layer is usually concentrated in middleware or decorators, so switching is more like rewriting an adapter than rewriting the entire system. Consider this when choosing a provider, but don’t let lock-in fears paralyze you — using the wrong auth approach (building it yourself) has far worse lock-in consequences.
Where does my user data live?
Most no-code providers (Auth0, Clerk, Firebase) store user data in their infrastructure. Supabase is unique in storing auth data in your own PostgreSQL database. If data residency is critical, Supabase is your answer. If you’re in an industry with strict data privacy requirements, check the provider’s data center locations and compliance certifications. Most enterprise services offer data residency options (e.g., EU-only data storage).
Can I customize the login UI?
All major providers support white-label login pages. Auth0 and Clerk allow embedding authentication directly in your application using their UI libraries. Firebase offers pre-built UI components or headless APIs if you want complete control over the interface. Supabase provides the supabase-auth-ui for quick setup or raw API access for custom interfaces. The level of customization varies by provider, but all offer more flexibility than building from scratch.
What if I have legacy users from a custom auth system?
Most providers support user imports. You can bulk-import existing user records (with hashed passwords if you trust your hash algorithm) into Auth0, Clerk, or Firebase. The import process typically takes a few steps and a bit of data transformation. During the transition, you might temporarily support both old and new auth systems, gradually migrating users. This is a known problem with known solutions.
Can I use no-code auth for offline-first apps?
No-code services require internet connectivity to authenticate users initially. For offline-first applications, you’ll need to implement local authentication with cached credentials. Some services like Supabase provide offline SDKs that sync when connectivity returns. If offline operation is essential, plan for a hybrid approach: use third-party auth for online users and implement local fallback logic for offline scenarios.
No-code authentication has fundamentally changed how Python developers should approach user login and identity management. The era of building custom auth systems is over for most applications. The services available today — Auth0, Firebase Auth, Clerk, and Supabase Auth — offer security, compliance, and features that rival or exceed what you could build in a reasonable timeframe.
The practical decision is simple: unless you have a specific, documented reason to build your own auth system, use a third-party provider. Spend your engineering time on your product’s core value proposition. Let experts handle the complex, security-critical job of authentication.
Start with the quick example in this guide, pick a provider that matches your architecture, and add authentication to your Python application in an afternoon. Your future self will thank you when you’re not debugging password reset tokens at 2 AM.
Generating random numbers in Python is a fairly straightforward activity which can be done in a few lines. There maybe many variations which you need to do ranging from decimal places, random numbers between a start and end number, and many more. We’ll go through many useful examples in this article.
The most basic way to generate random numbers in python is with the random library:
import random
num = random.random()
print( f"Random number between 0.0 and 1.0 ={num}\n")
Output as follows:
You’ll see that each time it is run it has a new random number.
Generating the same random number each time and why this matters
Sometimes, you may want to generate some random numbers, but then be able to generate the same random numbers each time. Now this may sound counter intuitive as the whole point of getting random numbers is so that, well, they are random. One scenario where you would like to regenerate the same random numbers is during testing. You may find some unusual behaviour and this is where you may want to replicate that behaviour for which you’l l need the same input. This is where you’d want to generate the same random number and you can do that in python using the seed function from the random library.
The idea behind the seed function is that you can think of it as a specific key which can be used to generate a series of random numbers which stems from a given key. Use a different seed and you’ll generate a different set of random numbers.
See the following example code which generates a random number between 1 and 0:
import random
random.seed(1)
for i in range(1,5):
num = random.random()
print( f"Random number between 0.0 and 1.0 ={num}\n")
Output as follows:
No matter how many times it is run, since the seed is the same each time, it generates the same numbers.
Python Random Number Between 1 and 10
Now that we know how to generate random numbers, how do you do it between two numbers? This is easily done in with either randint() for whole numbers or with uniform() for decimal numbers.
import random
num_int = random.randint(1,10)
print( f"Random whole number between 1 and 10 ={num_int}\n")
num_uni = random.uniform(1,10)
print( f"Random decimal number between 1 and 10 ={num_uni}\n")
Python Generate Random Numbers From A Range
Suppose you needed to generate random numbers from a range of data whether that be numbers, names or even a pack of cards. This can be done through selecting the random element in an array by choosing the index randomly. For example, if you had an array of 5 items, then you can randomly chose and index from 0 to 4 (where 0 is the index of the first item).
There is another and shorter way in python which is to use the random.choice() function. If you pass it an array, it will then randomly return one of the elements.
Here’s an example to randomly select a name from a list with both using the index (to show you how it works), and the much most efficient random.choice() library function:
import random
###### Selecing numbers from a range
names_list = [ "Judy", "Harry", "Sarah", "Tom", "Gloria"]
rand_index = random.randint( 0, len(names_list)-1 )
print( f"Randomly selected person 1 is = { names_list[ rand_index] }\n")
print( f"Randomly selected person 2 is = { random.choice( names_list) }\n")
And the output is different each time:
Generate Random String Of Length n in Python
If you want to generate a specific length string (e.g. to generate a password), both the random and the string libraries can come in handy where you can use it to create an easy password generator as follows:
import random, string
###### Create a random password
def generate_password( pass_len=10):
password = ""
for i in range(1,pass_len+1):
password = password + random.choice( string.ascii_letters + string.punctuation )
return password
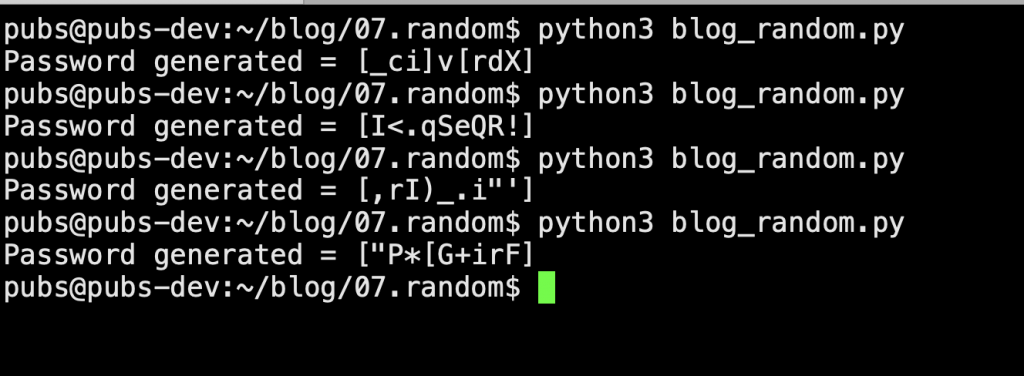
print( f"Password generated = [{ generate_password(10) }] ")
This will output a new password each time between square brackets:
If there are specific characters you want to include or exclude, you can simply replace the string.punctuation with your own list/array of specific characters to be included
Random Choice Without Replacement In Python
Suppose you wanted to randomly select items from a list without repeating any items. For example, you have a list of students and you have to select them in a random order to go first in a specific activity. In many programming languages you may need to generate a random list and remember the previously selected items to prevent any repeated selections. In the random library, there is a function called random.sample() that will do all that for you:
import random
#### Select unique random elements
students = ["John", "Tom", "Paul", "Sarah", "July", "Rachel"]
random_order = random.sample( students, 6)
print(random_order)
This will generate a unique list without repeating any selections:
[mfe_send_fox body=”
Sign up to the email list and get articles straight to your inbox. Plus get our free python one liner list!
In order to generate a date between two dates, this can be done by converting the dates into days first. This can be combined with the random.randint() in addition to the days of the date differences then adding back to the start date:
import random, datetime
#### Select a random date between two dates:
d1 = datetime.date( 2013, 2, 26 )
d2 = datetime.date( 2015, 12, 15 )
diff = d2 - d1
new_date_days = random.randint( 0, diff.days )
print( f"Random date is { d1 + datetime.timedelta( days=new_date_days ) }")
The output would be as follows:
Generate Random Temporary Filename in Python
A common need is to generate a random filename often for temporary storage. This might be for a log file, a cache file or some other scenario and can be easily done with the similar string generation as above. First a letter should be determined and then the remaining letters can be added with also numbers as well.
The random library has many uses from generating numbers to specific strings with a given length for password generation. Typically, these use cases sometimes have specialised libraries as there can be nuances (e.g for passwords, you may not want a repeating sequence which may be possible through random luck) which you can search for through pypi.org. However, many can be created with simple lines of code as demonstrated above. Send comments below or email me to ask further questions.
Subscribe
Not subscribed to our email list? Sign up now and get your next article in your inbox:
You ask an LLM to extract a user’s name, age, and email from a paragraph of text. Sometimes it returns clean JSON. Sometimes it returns JSON wrapped in markdown fences. Sometimes it returns a paragraph explaining why it extracted those fields. If you have ever built a pipeline that breaks because the model decided today was a good day to add “Sure! Here is the extracted data:” before the JSON, you already understand why instructor exists.
The instructor library patches the OpenAI client (and any OpenAI-compatible API) to force the model to return a fully validated Pydantic model — every time. When validation fails, it retries automatically. You define exactly what fields you need, with their types and constraints, and instructor handles the conversation with the model until the output matches your schema. You need Python 3.9+, an OpenAI API key (or compatible endpoint), and pip install instructor.
This article walks through everything you need to get structured LLM outputs in production: installing and patching the client, defining Pydantic schemas, extracting nested objects, handling lists, using validation hooks, working with non-OpenAI models via LiteLLM, and building a real extraction pipeline. By the end you will have a reusable pattern for reliable structured data from any LLM.
Structured LLM Output: Quick Example
The fastest way to see instructor in action is to extract a structured object from a single sentence. Install the library and try this:
# quick_instructor.py
import instructor
from openai import OpenAI
from pydantic import BaseModel
client = instructor.from_openai(OpenAI())
class Person(BaseModel):
name: str
age: int
city: str
person = client.chat.completions.create(
model="gpt-4o-mini",
response_model=Person,
messages=[{"role": "user", "content": "Alice is 32 years old and lives in Melbourne."}]
)
print(person.name) # Alice
print(person.age) # 32
print(person.city) # Melbourne
print(type(person)) # <class '__main__.Person'>
Output:
Alice
32
Melbourne
<class '__main__.Person'>
The key line is instructor.from_openai(OpenAI()) — this patches the standard OpenAI client. After that, you pass response_model=Person to any chat.completions.create call, and instructor automatically: sends the Pydantic schema to the model as a tool definition, parses the model’s tool-call response, validates it against your schema, and retries if validation fails. The return value is a fully typed Pydantic object, not a string or dict.
That example covers the simplest case. The sections below show how to handle nested models, lists, validation rules, retry configuration, and real-world pipelines.
response_model= and the chaos becomes a schema.
What Is instructor and Why Use It?
When you call an LLM without constraints, it returns free-form text. Parsing that text into structured data is fragile — you write regex, JSON parsers, and fallback handlers that break every time the model changes its wording. instructor solves this by using OpenAI’s function/tool calling feature under the hood: it converts your Pydantic model into a JSON Schema tool definition, forces the model to call that tool, and validates the returned arguments against your schema.
The result is LLM output that behaves like a typed function return value instead of a string you have to parse. If the model returns a field with the wrong type (for example, age as a string “thirty-two” instead of an integer), instructor sends the validation error back to the model and asks it to try again — up to a configurable number of retries.
Approach
Reliability
Type Safety
Auto-Retry
Parse raw LLM text
Fragile
None
Manual
Parse JSON from prompt
Moderate
Manual
Manual
OpenAI function calling
Good
Partial
None
instructor + Pydantic
High
Full
Built-in
The library supports multiple backends: instructor.from_openai, instructor.from_anthropic, instructor.from_gemini, and any OpenAI-compatible endpoint via base_url. This makes it the same interface regardless of which model you use.
Installation and Setup
Install instructor and the OpenAI SDK together. If you are using a different provider, you may also need their SDK:
# Terminal
pip install instructor openai pydantic
Set your API key as an environment variable so it never appears in your code:
# setup_env.py -- run once, or add to your shell profile
import os
# In practice, set this in your shell:
# export OPENAI_API_KEY="sk-..."
print("OPENAI_API_KEY set:", bool(os.environ.get("OPENAI_API_KEY")))
Output:
OPENAI_API_KEY set: True
Patch the client once at startup and reuse it for all calls. Creating a new patched client for every request is wasteful:
# client_setup.py
import instructor
from openai import OpenAI
# Patch once at startup
client = instructor.from_openai(OpenAI()) # reads OPENAI_API_KEY from env
# The client now has response_model support on all completion calls
print(type(client)) # <class 'instructor.client.Instructor'>
Output:
<class 'instructor.client.Instructor'>
One patch. Every completion call now speaks schema.
Defining Pydantic Schemas for Extraction
Your Pydantic model defines exactly what fields the LLM must return. Field descriptions improve accuracy significantly — the model uses them as instructions for what to put in each field. Use Field(description=...) to guide the extraction:
# schema_example.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import Optional
client = instructor.from_openai(OpenAI())
class JobPosting(BaseModel):
title: str = Field(description="The exact job title as written in the posting")
company: str = Field(description="Company name offering the position")
location: str = Field(description="City and country, or 'Remote'")
salary_min: Optional[int] = Field(None, description="Minimum annual salary in USD if mentioned")
salary_max: Optional[int] = Field(None, description="Maximum annual salary in USD if mentioned")
is_remote: bool = Field(description="True if the role allows remote work")
text = """
Senior Python Developer at DataFlow Inc. -- Remote (US timezones preferred).
Salary range: $140,000 - $175,000 per year. Must have 5+ years Python experience.
"""
job = client.chat.completions.create(
model="gpt-4o-mini",
response_model=JobPosting,
messages=[{"role": "user", "content": f"Extract the job details from: {text}"}]
)
print(f"Title: {job.title}")
print(f"Company: {job.company}")
print(f"Location: {job.location}")
print(f"Salary: ${job.salary_min:,} - ${job.salary_max:,}")
print(f"Remote: {job.is_remote}")
The Optional[int] type tells instructor (and the model) that salary fields may be absent. When the source text does not mention a salary, these fields will be None instead of hallucinated values. Always use Optional for fields that may not appear in the input — without it, the model will invent plausible-sounding values rather than leaving the field empty.
Extracting Nested and List Objects
Real-world extraction often requires nested structures — for example, an invoice with multiple line items, or a resume with a list of work experiences. instructor handles nested Pydantic models and List types natively:
# nested_extraction.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import List
client = instructor.from_openai(OpenAI())
class LineItem(BaseModel):
description: str
quantity: int
unit_price: float
class Invoice(BaseModel):
vendor: str
invoice_number: str
items: List[LineItem]
total: float
invoice_text = """
Invoice #INV-2024-0891 from CloudHost Solutions
- 3x Server instances @ $45.00 each
- 1x SSL Certificate @ $12.00
- 2x Domain registrations @ $15.00 each
Total: $222.00
"""
result = client.chat.completions.create(
model="gpt-4o-mini",
response_model=Invoice,
messages=[{"role": "user", "content": f"Extract invoice data: {invoice_text}"}]
)
print(f"Vendor: {result.vendor}")
print(f"Invoice #: {result.invoice_number}")
for item in result.items:
print(f" {item.quantity}x {item.description} @ ${item.unit_price:.2f}")
print(f"Total: ${result.total:.2f}")
Nested models work because instructor converts the entire schema — including nested classes — into a JSON Schema definition that the model understands. The model fills in every field of every nested object, and Pydantic validates the whole structure recursively. If the items list is missing or a line item has an invalid type, instructor retries the extraction with the validation error as feedback.
Nested Pydantic models: recursion that actually works.
Adding Custom Validation Rules
Pydantic’s field_validator lets you add business logic on top of type checking. instructor automatically feeds validation errors back to the model, so the model gets a second (or third) chance to return values that satisfy your rules:
# custom_validation.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field, field_validator
from typing import List
client = instructor.from_openai(OpenAI())
class ProductReview(BaseModel):
product_name: str
rating: int = Field(description="Rating from 1 to 5")
pros: List[str] = Field(description="List of positive aspects, at least one")
cons: List[str] = Field(description="List of negative aspects, can be empty")
summary: str = Field(description="One-sentence summary under 150 characters")
@field_validator("rating")
@classmethod
def rating_in_range(cls, v: int) -> int:
if not 1 <= v <= 5:
raise ValueError(f"Rating must be between 1 and 5, got {v}")
return v
@field_validator("pros")
@classmethod
def at_least_one_pro(cls, v: List[str]) -> List[str]:
if not v:
raise ValueError("Must include at least one positive aspect")
return v
@field_validator("summary")
@classmethod
def summary_length(cls, v: str) -> str:
if len(v) > 150:
raise ValueError(f"Summary too long: {len(v)} chars (max 150)")
return v
text = """
The new Python IDE is pretty solid. Boot time is fast, autocomplete works well.
The memory usage is high and the plugin store is still sparse. Overall a decent
choice for Python development. I'd give it 4 out of 5.
"""
review = client.chat.completions.create(
model="gpt-4o-mini",
response_model=ProductReview,
messages=[{"role": "user", "content": f"Extract review details: {text}"}]
)
print(f"Product: {review.product_name}")
print(f"Rating: {review.rating}/5")
print(f"Pros: {review.pros}")
print(f"Cons: {review.cons}")
print(f"Summary: {review.summary}")
Output:
Product: Python IDE
Rating: 4/5
Pros: ['Fast boot time', 'Good autocomplete']
Cons: ['High memory usage', 'Sparse plugin store']
Summary: A solid Python IDE with fast performance but limited plugins and high memory usage.
When a validator raises ValueError, instructor captures the error message and sends it back to the model in a follow-up message: “Validation failed: Rating must be between 1 and 5, got 6. Please fix and try again.” The model then self-corrects. By default, instructor retries up to 3 times before raising an exception. You can configure this with max_retries=N on the completion call.
Configuring Retries and Modes
instructor supports several extraction modes depending on what your model supports. The default mode uses OpenAI’s tool calling, but you can switch to JSON mode or other strategies:
# retry_config.py
import instructor
from instructor import Mode
from openai import OpenAI
from pydantic import BaseModel
# Default: tool calling (most reliable for OpenAI models)
client_tools = instructor.from_openai(OpenAI())
# JSON mode: model returns raw JSON instead of a tool call
client_json = instructor.from_openai(OpenAI(), mode=Mode.JSON)
# MD_JSON mode: model wraps JSON in markdown fences (useful for some fine-tunes)
client_md = instructor.from_openai(OpenAI(), mode=Mode.MD_JSON)
class City(BaseModel):
name: str
country: str
population: int
# Control retries per-call
city = client_tools.chat.completions.create(
model="gpt-4o-mini",
response_model=City,
max_retries=5, # retry up to 5 times on validation failure
messages=[{"role": "user", "content": "Tell me about Tokyo"}]
)
print(f"{city.name}, {city.country}: pop {city.population:,}")
Output:
Tokyo, Japan: pop 13,960,000
For most OpenAI models, the default tool-calling mode is most reliable. Use Mode.JSON for models that support JSON mode but not tool calling — for example, some fine-tuned models or older GPT versions. The max_retries parameter controls how many times instructor will re-prompt the model when validation fails. For production pipelines where data quality matters more than cost, set this to 3-5.
Three retries and a Pydantic error. That’s the whole self-correction system.
Using instructor with Non-OpenAI Models
If you are using Anthropic’s Claude, Google Gemini, or a local model via Ollama, instructor has provider-specific patches. For OpenAI-compatible endpoints (like local LLMs with an OpenAI-compatible API), you can pass a custom base_url:
# multi_provider.py
import instructor
from anthropic import Anthropic
from pydantic import BaseModel
# Anthropic Claude -- uses a different client class
anthropic_client = instructor.from_anthropic(Anthropic())
class Sentiment(BaseModel):
label: str # "positive", "negative", or "neutral"
score: float # confidence from 0.0 to 1.0
reason: str # one-sentence explanation
result = anthropic_client.messages.create(
model="claude-3-haiku-20240307",
max_tokens=256,
response_model=Sentiment,
messages=[{
"role": "user",
"content": "This new Python library is fantastic, saves me hours every week!"
}]
)
print(f"Sentiment: {result.label} ({result.score:.0%})")
print(f"Reason: {result.reason}")
Output:
Sentiment: positive (96%)
Reason: The user expresses strong enthusiasm and quantifies time savings, indicating genuine satisfaction.
For local models via Ollama (which provides an OpenAI-compatible API on localhost:11434), create the client with a custom base URL:
# ollama_instructor.py
import instructor
from openai import OpenAI
from pydantic import BaseModel
# Ollama runs an OpenAI-compatible server locally
ollama_client = instructor.from_openai(
OpenAI(base_url="http://localhost:11434/v1", api_key="ollama"),
mode=instructor.Mode.JSON # use JSON mode for local models
)
class Summary(BaseModel):
headline: str
key_points: list[str]
# Works the same as OpenAI -- just a different backend
# summary = ollama_client.chat.completions.create(
# model="llama3.2",
# response_model=Summary,
# messages=[{"role": "user", "content": "Summarize Python's async/await model"}]
# )
print("Local model client ready -- uncomment to use with Ollama running")
Output:
Local model client ready -- uncomment to use with Ollama running
Here is a complete pipeline that reads job postings from a list of texts, extracts structured data, filters by criteria, and exports to CSV — the kind of task that comes up in recruiting tools, market research, and job aggregators:
Structured extraction at scale: parsing 50 job posts is just a for loop.
# job_extraction_pipeline.py
import instructor
import csv
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import Optional, List
client = instructor.from_openai(OpenAI())
class JobPosting(BaseModel):
title: str = Field(description="Job title exactly as written")
company: str
location: str = Field(description="City/country or 'Remote'")
salary_min: Optional[int] = Field(None, description="Min annual salary USD")
salary_max: Optional[int] = Field(None, description="Max annual salary USD")
required_years: Optional[int] = Field(None, description="Years of experience required")
technologies: List[str] = Field(description="List of technologies mentioned")
is_remote: bool
# Sample job postings to process
JOB_TEXTS = [
"""Senior Python Engineer at Nexaflow -- Remote-first.
$150k-$190k. 5+ years Python, FastAPI, PostgreSQL, AWS required.""",
"""Junior Data Scientist at BioMetrics Ltd (London, UK).
GBP 45,000-55,000. 0-2 years exp, pandas, scikit-learn, matplotlib.""",
"""Staff ML Engineer at Quantra -- San Francisco CA.
$220,000 - $280,000/yr. 8+ years, PyTorch, CUDA, distributed training.""",
]
def extract_jobs(texts: List[str]) -> List[JobPosting]:
"""Extract structured job data from raw posting texts."""
jobs = []
for i, text in enumerate(texts, 1):
job = client.chat.completions.create(
model="gpt-4o-mini",
response_model=JobPosting,
max_retries=3,
messages=[{"role": "user", "content": f"Extract job details:\n\n{text}"}]
)
jobs.append(job)
print(f"[{i}/{len(texts)}] Extracted: {job.title} at {job.company}")
return jobs
def filter_remote(jobs: List[JobPosting]) -> List[JobPosting]:
return [j for j in jobs if j.is_remote]
def export_csv(jobs: List[JobPosting], path: str) -> None:
with open(path, "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(["Title", "Company", "Location", "Salary Min", "Salary Max",
"Yrs Required", "Technologies", "Remote"])
for j in jobs:
writer.writerow([
j.title, j.company, j.location,
j.salary_min or "", j.salary_max or "",
j.required_years or "",
", ".join(j.technologies),
j.is_remote
])
if __name__ == "__main__":
print("Extracting job postings...")
jobs = extract_jobs(JOB_TEXTS)
remote_jobs = filter_remote(jobs)
print(f"\nTotal extracted: {len(jobs)}, Remote: {len(remote_jobs)}")
export_csv(jobs, "jobs_extracted.csv")
print("Saved to jobs_extracted.csv")
Output:
Extracting job postings...
[1/3] Extracted: Senior Python Engineer at Nexaflow
[2/3] Extracted: Junior Data Scientist at BioMetrics Ltd
[3/3] Extracted: Staff ML Engineer at Quantra
Total extracted: 3, Remote: 1
Saved to jobs_extracted.csv
This pipeline is easy to extend: add a database write step, connect it to a web scraper that feeds real job pages, or add more validation rules to the JobPosting model. The core pattern — extract once, validate automatically, retry on failure — stays the same regardless of the scale. You can process thousands of postings by replacing JOB_TEXTS with a generator that reads from a queue or database, keeping the extraction logic identical.
Frequently Asked Questions
Does instructor increase API costs because of retries?
Yes, each retry is an additional API call, so failed extractions cost more. In practice, with well-designed schemas and clear field descriptions, validation failures are rare — under 5% for most extraction tasks. The cost increase is usually worth the reliability gain. If cost is a concern, use max_retries=1 and handle exceptions in your code rather than retrying automatically.
Does instructor support streaming responses?
Yes. Use response_model=Iterable[YourModel] for streaming lists, or Partial[YourModel] for streaming partial updates to a single model. Streaming is useful for large extractions where you want to process results as they arrive rather than waiting for the full response. See the instructor documentation for the streaming API details.
What happens when the model cannot extract a field?
If the field is typed as Optional[X], the model will return None for missing information. If the field is required (non-Optional), the model will either hallucinate a value or fail validation, triggering a retry. For fields that may legitimately be absent in the source text, always use Optional with a None default. This is the most common mistake new users make.
Can I extract data from large documents?
Yes, but be aware of token limits. For documents larger than a few thousand words, split them into chunks and extract from each chunk separately. Use a List[YourModel] return type if a single document contains multiple items to extract (like a list of transactions in a bank statement). For very large documents, consider summarizing first with a regular completion call, then extracting from the summary.
How is this different from just prompting for JSON output?
Prompting for JSON works until it does not — the model adds markdown fences, writes a preamble sentence, or omits fields. instructor uses tool calling (not prompting) to enforce the schema, so the model cannot deviate from the structure. It also runs Pydantic validation on the result and retries if types or constraints are violated. The difference in reliability for production use is significant — JSON prompting is fine for experiments, but instructor is the right tool for pipelines where data quality matters.
Is my data sent to OpenAI when I use instructor?
instructor is a thin wrapper around the OpenAI SDK — your data goes to whatever API endpoint you configure, subject to that provider’s data policy. If you are processing sensitive data, use a self-hosted model via Ollama or another local inference server, and point instructor at your local endpoint with a custom base_url. The library itself does not send data anywhere — it only wraps the client you provide.
Conclusion
The instructor library solves one of the most persistent frustrations in LLM application development: getting the model to return data in the shape your code expects, every time. We covered patching the OpenAI client, defining Pydantic schemas with field descriptions, extracting nested and list objects, adding custom validation rules, configuring retries and modes, and using instructor with non-OpenAI providers. The job extraction pipeline demonstrated how these pieces combine into a production-ready pattern.
The next step is to extend the real-life example: add a web scraper to pull live job postings, or connect the extracted data to a database. With instructor handling the model-to-schema translation, you can focus entirely on the business logic of what to extract and what to do with it.
Full documentation and more examples are at python.useinstructor.com. The library’s GitHub has a large collection of real-world examples including classification, knowledge graph extraction, and citation-backed answers.
Use random.randint(a, b) for integers or random.random() for a float between 0 and 1. Example: import random; num = random.randint(1, 100).
What is the difference between random and secrets?
The random module is for simulations and games but NOT for security. The secrets module provides cryptographically secure randomness for passwords, tokens, and security-sensitive applications.
How do I generate a random list of numbers?
Use [random.randint(1, 100) for _ in range(10)] for random integers. For unique numbers, use random.sample(range(1, 101), 10). For float arrays, use numpy.random.rand(10).
How do I set a random seed?
Call random.seed(42) before generating numbers. The same seed always produces the same sequence, useful for testing and reproducible experiments.
Can I generate numbers following a specific distribution?
Yes. Use random.gauss() for normal, random.uniform() for uniform. NumPy offers numpy.random.normal(), poisson(), binomial(), and many more.
For some of your web apps you develop in python, you will want to run them on the cloud so that your script can run 24/7. For some of your smaller applications, you may want to find the right free python hosting service so you don’t have to worry about the per month charges. These web applications might be a website written in flask, or using another web framework, it might be other types of python apps that runs in the background and runs your automation. This is where you can consider some of the hosting services that have a free plan and are still very easy to setup.
To find the right hosting platforms that fits your needs, you want to consider a few things:
Ease of access to upload projects
What type of support they provide
What specifications that virtual server environment has to offer
One such new platform is called deta.sh. Deta is a free hosting service that can be used to provide web hosting for deploying python web applications or other types of python applications that run in the background.
The deta service, as of mid-2022, is still in the development stage and is expected to have a permanent free python hosting service so that online python applications can be setup and deployed quickly and easily. Deta is a relatively new service but is a service that is intended to compete with pythonanywhere, heroku, and similar services to run python on web servers. The service lets you host python script online without fuss directly from a command line, much like how you can check in code to github. Although it is new, it has the potential to be one of the best free python hosting there is in order to get your python online.
The platform provides you mini virtual environments (called ‘micros’) where you can host your python scripts. These can be separated into workspaces called ‘projects’ so that you can also more easily manage your environments. The way you can access/upload your code is with the command line through a password Access Token.
We will go through step by step how to run your python online. For this article, we will guide you on using deta to host a simple flask based web page so that you can have python as a webserver.
Signing up for Deta.sh
Deta.sh is effectively a cloud python hosting service which sits on top of AWS and allows you to deploy your python code into a virtual machine (called a deta micro), store files (called data drive) and also store data (called deta base). Unlike AWS or other hosting services, you can quickly host and run your script without going through the hassle of setting up server, security configurations etc.
The Deta.sh team offers the service for free in order to allow developers to monetize the solutions where deta.sh will be able to share some of that revenue. To date, there are no paid Deta.sh hosting plans for python hosting and no intention. So you can continue to run python code online forever.
To begin with, head over to the website https://deta.sh to first create an account.
Enter a unique username, password and email. The Email must be real in order to activate your account
Once you have submitted, go to your email and click on the verify link.
You will be taken to this “verification success” page. Here you can sign in, but also join the “Discord” channel. You can get any help very quickly from the community that’s there.
After you click on sign-in, enter the same username and password, and you will be taken to the default page where you will have the ability to “See My Key”
Click on the “See My Key” to see your secret password. You will only be able to see it once and will not be able to see it ever again.
This is what they project key will look like:
You need both the key and the project id.
Think of the key like a password and the “Project ID” as a password. When you want to access your deta.sh to upload programs, make changes, you will need to use your project key to access your space.
If you lose your project id/key, you will not be able to recover it. However, you can create a new one with Settings->Create Key option.
Create a new project key with Settings -> Create Key (this key you see on the screen has already been deleted!)
One thing I’d like to call out is the Project ID. This is the ID of this particular s[ace
If you have multiple programs which access deta.sh, it is best to have separate project keys. The reason is that if one of your keys are compromised, then you can simply just change that key and not have all your applications be affected.
Setting Up Your Remote Access For Deta.sh
We will first setup deta.sh in the command line interface so that you can communicate to your deta.sh space on the cloud.
You can do this with either one of:
Mac / Linux:
curl -fsSL https://get.deta.dev/cli.sh | sh
Windows:
iwr https://get.deta.dev/cli.ps1 -useb | iex
Once that’s done, what will happen is that there will be a hidden folder called $HOME/.deta that is created (specifically in the case of Mac / Linux). It’s in this directory that the deta command line application will be found.
You can type deta --help to check that the command line tool was installed correctly
Next, you will need to create an access token so that you can connect to your deta.sh account. For this you will need to create an access token. Go to your deta.sh home page (e.g. https://web.deta.sh/) and then go back to the main projects page.
Next, click on the Create Access token under settings
Once you create token, this will create an Access Token so that you don’t need to login each time.
Copy this Access Token and then, create a file called tokens in the $HOME/.deta/ directory. Steps for Mac/Linux are:
cd $HOME/.deta
nano tokens
You can then add the following json inside the tokens file:
{
"deta_access_token": "<your access token created above>"
}
Finally, you can install the python library that will be used to access the deta components with the deta library.
pip install deta
Have a Free Python Hosting Flask on Deta.sh
To create an environment to host your python code and have python web hosting, you need to create something called a “micro“. This is almost like a mini virtual server with 128mb of memory but will not be running all the time. They will wake up, execute your code, and then go back to sleep. Deta.sh is not designed for long running applications with heavy computations (use one of the public cloud providers for that!). Also, each micro has its own python online cloud private access.
To begin with, you can use the command deta new --python <micro name>. The <micro name> is the name to label the mini-virtual name.
The above command will create a directory called flask_test with a python script called main.py
The default code in the main.py is:
def app(event):
return "Hello, world!"
At the same time, this code will be uploaded to deta.sh. If you go to the dashboard page https://web.deta.sh/ you will see a sub-menu under the Micro menu. You may need to refresh your browser if you had it open.
You will notice that there’s also a URL for this deta micro which is the end point where your application output can be accessed. Think of this simply as the console output.
If you encountered any errors, in the command line, you can type deta logs to get an output of any errors from the logs.
To make a more useful application, we can create a flask application to show a more functional webpage. In order to do this, you will need to dell deta.sh to install the flask library. You cannot use pip install unfortunately, but instead you need to use the requirements.txt instead.
First, add flask into a requirements.txt file in your local directory. So your file should simply look like this:
#requirements.txt
flask
Then in your main.py code file, you add the following, again this is in your local directory
In order to now upload the changes to your micro, you will need to run the command deta deploy. This will upload the files requirements.txt and updates to main.py into your micro.
deta deploy
When executed, this should upload the code and install the libraries:
Managing Flask Forms On Free Python Hosting
Now that we have a simple static web page, we can create a more complex example where there’s a form that can be submitted. Using the weather API from openweathermap API, we can show the weather for a given location.
To get the weather data, we need to install two libraries pyowm and datetime. Hence, this will need to be added to requirements.txt.
#requirements.txt
flask
pyowm
datetime
Then for the code, the following can be updated in the main.py:
When the form is submitted from the / url, then the function def get_weather() is called to process the form. The variable that was passed, can be access through request.form['location'].
The above code works by first providing a form through the function def get_location() which generates a very simple form through HTML:
When the submit button is pressed, the form calls the /weather URL with the field location. Once called, then the python function def get_weather() is called upon which a call to OpenWeatherMap.org is made to get the weather data for the given location.
Conclusion
This is just a tip of the iceberg of what you can do with deta. You can also run scheduled jobs, run a NoSQL database, and have file storage as well. Contact us if you’d like us to cover these areas too.
You ask an LLM to extract a user’s name, age, and email from a paragraph of text. Sometimes it returns clean JSON. Sometimes it returns JSON wrapped in markdown fences. Sometimes it returns a paragraph explaining why it extracted those fields. If you have ever built a pipeline that breaks because the model decided today was a good day to add “Sure! Here is the extracted data:” before the JSON, you already understand why instructor exists.
The instructor library patches the OpenAI client (and any OpenAI-compatible API) to force the model to return a fully validated Pydantic model — every time. When validation fails, it retries automatically. You define exactly what fields you need, with their types and constraints, and instructor handles the conversation with the model until the output matches your schema. You need Python 3.9+, an OpenAI API key (or compatible endpoint), and pip install instructor.
This article walks through everything you need to get structured LLM outputs in production: installing and patching the client, defining Pydantic schemas, extracting nested objects, handling lists, using validation hooks, working with non-OpenAI models via LiteLLM, and building a real extraction pipeline. By the end you will have a reusable pattern for reliable structured data from any LLM.
Structured LLM Output: Quick Example
The fastest way to see instructor in action is to extract a structured object from a single sentence. Install the library and try this:
# quick_instructor.py
import instructor
from openai import OpenAI
from pydantic import BaseModel
client = instructor.from_openai(OpenAI())
class Person(BaseModel):
name: str
age: int
city: str
person = client.chat.completions.create(
model="gpt-4o-mini",
response_model=Person,
messages=[{"role": "user", "content": "Alice is 32 years old and lives in Melbourne."}]
)
print(person.name) # Alice
print(person.age) # 32
print(person.city) # Melbourne
print(type(person)) # <class '__main__.Person'>
Output:
Alice
32
Melbourne
<class '__main__.Person'>
The key line is instructor.from_openai(OpenAI()) — this patches the standard OpenAI client. After that, you pass response_model=Person to any chat.completions.create call, and instructor automatically: sends the Pydantic schema to the model as a tool definition, parses the model’s tool-call response, validates it against your schema, and retries if validation fails. The return value is a fully typed Pydantic object, not a string or dict.
That example covers the simplest case. The sections below show how to handle nested models, lists, validation rules, retry configuration, and real-world pipelines.
response_model= and the chaos becomes a schema.
What Is instructor and Why Use It?
When you call an LLM without constraints, it returns free-form text. Parsing that text into structured data is fragile — you write regex, JSON parsers, and fallback handlers that break every time the model changes its wording. instructor solves this by using OpenAI’s function/tool calling feature under the hood: it converts your Pydantic model into a JSON Schema tool definition, forces the model to call that tool, and validates the returned arguments against your schema.
The result is LLM output that behaves like a typed function return value instead of a string you have to parse. If the model returns a field with the wrong type (for example, age as a string “thirty-two” instead of an integer), instructor sends the validation error back to the model and asks it to try again — up to a configurable number of retries.
Approach
Reliability
Type Safety
Auto-Retry
Parse raw LLM text
Fragile
None
Manual
Parse JSON from prompt
Moderate
Manual
Manual
OpenAI function calling
Good
Partial
None
instructor + Pydantic
High
Full
Built-in
The library supports multiple backends: instructor.from_openai, instructor.from_anthropic, instructor.from_gemini, and any OpenAI-compatible endpoint via base_url. This makes it the same interface regardless of which model you use.
Installation and Setup
Install instructor and the OpenAI SDK together. If you are using a different provider, you may also need their SDK:
# Terminal
pip install instructor openai pydantic
Set your API key as an environment variable so it never appears in your code:
# setup_env.py -- run once, or add to your shell profile
import os
# In practice, set this in your shell:
# export OPENAI_API_KEY="sk-..."
print("OPENAI_API_KEY set:", bool(os.environ.get("OPENAI_API_KEY")))
Output:
OPENAI_API_KEY set: True
Patch the client once at startup and reuse it for all calls. Creating a new patched client for every request is wasteful:
# client_setup.py
import instructor
from openai import OpenAI
# Patch once at startup
client = instructor.from_openai(OpenAI()) # reads OPENAI_API_KEY from env
# The client now has response_model support on all completion calls
print(type(client)) # <class 'instructor.client.Instructor'>
Output:
<class 'instructor.client.Instructor'>
One patch. Every completion call now speaks schema.
Defining Pydantic Schemas for Extraction
Your Pydantic model defines exactly what fields the LLM must return. Field descriptions improve accuracy significantly — the model uses them as instructions for what to put in each field. Use Field(description=...) to guide the extraction:
# schema_example.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import Optional
client = instructor.from_openai(OpenAI())
class JobPosting(BaseModel):
title: str = Field(description="The exact job title as written in the posting")
company: str = Field(description="Company name offering the position")
location: str = Field(description="City and country, or 'Remote'")
salary_min: Optional[int] = Field(None, description="Minimum annual salary in USD if mentioned")
salary_max: Optional[int] = Field(None, description="Maximum annual salary in USD if mentioned")
is_remote: bool = Field(description="True if the role allows remote work")
text = """
Senior Python Developer at DataFlow Inc. -- Remote (US timezones preferred).
Salary range: $140,000 - $175,000 per year. Must have 5+ years Python experience.
"""
job = client.chat.completions.create(
model="gpt-4o-mini",
response_model=JobPosting,
messages=[{"role": "user", "content": f"Extract the job details from: {text}"}]
)
print(f"Title: {job.title}")
print(f"Company: {job.company}")
print(f"Location: {job.location}")
print(f"Salary: ${job.salary_min:,} - ${job.salary_max:,}")
print(f"Remote: {job.is_remote}")
The Optional[int] type tells instructor (and the model) that salary fields may be absent. When the source text does not mention a salary, these fields will be None instead of hallucinated values. Always use Optional for fields that may not appear in the input — without it, the model will invent plausible-sounding values rather than leaving the field empty.
Extracting Nested and List Objects
Real-world extraction often requires nested structures — for example, an invoice with multiple line items, or a resume with a list of work experiences. instructor handles nested Pydantic models and List types natively:
# nested_extraction.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import List
client = instructor.from_openai(OpenAI())
class LineItem(BaseModel):
description: str
quantity: int
unit_price: float
class Invoice(BaseModel):
vendor: str
invoice_number: str
items: List[LineItem]
total: float
invoice_text = """
Invoice #INV-2024-0891 from CloudHost Solutions
- 3x Server instances @ $45.00 each
- 1x SSL Certificate @ $12.00
- 2x Domain registrations @ $15.00 each
Total: $222.00
"""
result = client.chat.completions.create(
model="gpt-4o-mini",
response_model=Invoice,
messages=[{"role": "user", "content": f"Extract invoice data: {invoice_text}"}]
)
print(f"Vendor: {result.vendor}")
print(f"Invoice #: {result.invoice_number}")
for item in result.items:
print(f" {item.quantity}x {item.description} @ ${item.unit_price:.2f}")
print(f"Total: ${result.total:.2f}")
Nested models work because instructor converts the entire schema — including nested classes — into a JSON Schema definition that the model understands. The model fills in every field of every nested object, and Pydantic validates the whole structure recursively. If the items list is missing or a line item has an invalid type, instructor retries the extraction with the validation error as feedback.
Nested Pydantic models: recursion that actually works.
Adding Custom Validation Rules
Pydantic’s field_validator lets you add business logic on top of type checking. instructor automatically feeds validation errors back to the model, so the model gets a second (or third) chance to return values that satisfy your rules:
# custom_validation.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field, field_validator
from typing import List
client = instructor.from_openai(OpenAI())
class ProductReview(BaseModel):
product_name: str
rating: int = Field(description="Rating from 1 to 5")
pros: List[str] = Field(description="List of positive aspects, at least one")
cons: List[str] = Field(description="List of negative aspects, can be empty")
summary: str = Field(description="One-sentence summary under 150 characters")
@field_validator("rating")
@classmethod
def rating_in_range(cls, v: int) -> int:
if not 1 <= v <= 5:
raise ValueError(f"Rating must be between 1 and 5, got {v}")
return v
@field_validator("pros")
@classmethod
def at_least_one_pro(cls, v: List[str]) -> List[str]:
if not v:
raise ValueError("Must include at least one positive aspect")
return v
@field_validator("summary")
@classmethod
def summary_length(cls, v: str) -> str:
if len(v) > 150:
raise ValueError(f"Summary too long: {len(v)} chars (max 150)")
return v
text = """
The new Python IDE is pretty solid. Boot time is fast, autocomplete works well.
The memory usage is high and the plugin store is still sparse. Overall a decent
choice for Python development. I'd give it 4 out of 5.
"""
review = client.chat.completions.create(
model="gpt-4o-mini",
response_model=ProductReview,
messages=[{"role": "user", "content": f"Extract review details: {text}"}]
)
print(f"Product: {review.product_name}")
print(f"Rating: {review.rating}/5")
print(f"Pros: {review.pros}")
print(f"Cons: {review.cons}")
print(f"Summary: {review.summary}")
Output:
Product: Python IDE
Rating: 4/5
Pros: ['Fast boot time', 'Good autocomplete']
Cons: ['High memory usage', 'Sparse plugin store']
Summary: A solid Python IDE with fast performance but limited plugins and high memory usage.
When a validator raises ValueError, instructor captures the error message and sends it back to the model in a follow-up message: “Validation failed: Rating must be between 1 and 5, got 6. Please fix and try again.” The model then self-corrects. By default, instructor retries up to 3 times before raising an exception. You can configure this with max_retries=N on the completion call.
Configuring Retries and Modes
instructor supports several extraction modes depending on what your model supports. The default mode uses OpenAI’s tool calling, but you can switch to JSON mode or other strategies:
# retry_config.py
import instructor
from instructor import Mode
from openai import OpenAI
from pydantic import BaseModel
# Default: tool calling (most reliable for OpenAI models)
client_tools = instructor.from_openai(OpenAI())
# JSON mode: model returns raw JSON instead of a tool call
client_json = instructor.from_openai(OpenAI(), mode=Mode.JSON)
# MD_JSON mode: model wraps JSON in markdown fences (useful for some fine-tunes)
client_md = instructor.from_openai(OpenAI(), mode=Mode.MD_JSON)
class City(BaseModel):
name: str
country: str
population: int
# Control retries per-call
city = client_tools.chat.completions.create(
model="gpt-4o-mini",
response_model=City,
max_retries=5, # retry up to 5 times on validation failure
messages=[{"role": "user", "content": "Tell me about Tokyo"}]
)
print(f"{city.name}, {city.country}: pop {city.population:,}")
Output:
Tokyo, Japan: pop 13,960,000
For most OpenAI models, the default tool-calling mode is most reliable. Use Mode.JSON for models that support JSON mode but not tool calling — for example, some fine-tuned models or older GPT versions. The max_retries parameter controls how many times instructor will re-prompt the model when validation fails. For production pipelines where data quality matters more than cost, set this to 3-5.
Three retries and a Pydantic error. That’s the whole self-correction system.
Using instructor with Non-OpenAI Models
If you are using Anthropic’s Claude, Google Gemini, or a local model via Ollama, instructor has provider-specific patches. For OpenAI-compatible endpoints (like local LLMs with an OpenAI-compatible API), you can pass a custom base_url:
# multi_provider.py
import instructor
from anthropic import Anthropic
from pydantic import BaseModel
# Anthropic Claude -- uses a different client class
anthropic_client = instructor.from_anthropic(Anthropic())
class Sentiment(BaseModel):
label: str # "positive", "negative", or "neutral"
score: float # confidence from 0.0 to 1.0
reason: str # one-sentence explanation
result = anthropic_client.messages.create(
model="claude-3-haiku-20240307",
max_tokens=256,
response_model=Sentiment,
messages=[{
"role": "user",
"content": "This new Python library is fantastic, saves me hours every week!"
}]
)
print(f"Sentiment: {result.label} ({result.score:.0%})")
print(f"Reason: {result.reason}")
Output:
Sentiment: positive (96%)
Reason: The user expresses strong enthusiasm and quantifies time savings, indicating genuine satisfaction.
For local models via Ollama (which provides an OpenAI-compatible API on localhost:11434), create the client with a custom base URL:
# ollama_instructor.py
import instructor
from openai import OpenAI
from pydantic import BaseModel
# Ollama runs an OpenAI-compatible server locally
ollama_client = instructor.from_openai(
OpenAI(base_url="http://localhost:11434/v1", api_key="ollama"),
mode=instructor.Mode.JSON # use JSON mode for local models
)
class Summary(BaseModel):
headline: str
key_points: list[str]
# Works the same as OpenAI -- just a different backend
# summary = ollama_client.chat.completions.create(
# model="llama3.2",
# response_model=Summary,
# messages=[{"role": "user", "content": "Summarize Python's async/await model"}]
# )
print("Local model client ready -- uncomment to use with Ollama running")
Output:
Local model client ready -- uncomment to use with Ollama running
Here is a complete pipeline that reads job postings from a list of texts, extracts structured data, filters by criteria, and exports to CSV — the kind of task that comes up in recruiting tools, market research, and job aggregators:
Structured extraction at scale: parsing 50 job posts is just a for loop.
# job_extraction_pipeline.py
import instructor
import csv
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import Optional, List
client = instructor.from_openai(OpenAI())
class JobPosting(BaseModel):
title: str = Field(description="Job title exactly as written")
company: str
location: str = Field(description="City/country or 'Remote'")
salary_min: Optional[int] = Field(None, description="Min annual salary USD")
salary_max: Optional[int] = Field(None, description="Max annual salary USD")
required_years: Optional[int] = Field(None, description="Years of experience required")
technologies: List[str] = Field(description="List of technologies mentioned")
is_remote: bool
# Sample job postings to process
JOB_TEXTS = [
"""Senior Python Engineer at Nexaflow -- Remote-first.
$150k-$190k. 5+ years Python, FastAPI, PostgreSQL, AWS required.""",
"""Junior Data Scientist at BioMetrics Ltd (London, UK).
GBP 45,000-55,000. 0-2 years exp, pandas, scikit-learn, matplotlib.""",
"""Staff ML Engineer at Quantra -- San Francisco CA.
$220,000 - $280,000/yr. 8+ years, PyTorch, CUDA, distributed training.""",
]
def extract_jobs(texts: List[str]) -> List[JobPosting]:
"""Extract structured job data from raw posting texts."""
jobs = []
for i, text in enumerate(texts, 1):
job = client.chat.completions.create(
model="gpt-4o-mini",
response_model=JobPosting,
max_retries=3,
messages=[{"role": "user", "content": f"Extract job details:\n\n{text}"}]
)
jobs.append(job)
print(f"[{i}/{len(texts)}] Extracted: {job.title} at {job.company}")
return jobs
def filter_remote(jobs: List[JobPosting]) -> List[JobPosting]:
return [j for j in jobs if j.is_remote]
def export_csv(jobs: List[JobPosting], path: str) -> None:
with open(path, "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(["Title", "Company", "Location", "Salary Min", "Salary Max",
"Yrs Required", "Technologies", "Remote"])
for j in jobs:
writer.writerow([
j.title, j.company, j.location,
j.salary_min or "", j.salary_max or "",
j.required_years or "",
", ".join(j.technologies),
j.is_remote
])
if __name__ == "__main__":
print("Extracting job postings...")
jobs = extract_jobs(JOB_TEXTS)
remote_jobs = filter_remote(jobs)
print(f"\nTotal extracted: {len(jobs)}, Remote: {len(remote_jobs)}")
export_csv(jobs, "jobs_extracted.csv")
print("Saved to jobs_extracted.csv")
Output:
Extracting job postings...
[1/3] Extracted: Senior Python Engineer at Nexaflow
[2/3] Extracted: Junior Data Scientist at BioMetrics Ltd
[3/3] Extracted: Staff ML Engineer at Quantra
Total extracted: 3, Remote: 1
Saved to jobs_extracted.csv
This pipeline is easy to extend: add a database write step, connect it to a web scraper that feeds real job pages, or add more validation rules to the JobPosting model. The core pattern — extract once, validate automatically, retry on failure — stays the same regardless of the scale. You can process thousands of postings by replacing JOB_TEXTS with a generator that reads from a queue or database, keeping the extraction logic identical.
Frequently Asked Questions
Does instructor increase API costs because of retries?
Yes, each retry is an additional API call, so failed extractions cost more. In practice, with well-designed schemas and clear field descriptions, validation failures are rare — under 5% for most extraction tasks. The cost increase is usually worth the reliability gain. If cost is a concern, use max_retries=1 and handle exceptions in your code rather than retrying automatically.
Does instructor support streaming responses?
Yes. Use response_model=Iterable[YourModel] for streaming lists, or Partial[YourModel] for streaming partial updates to a single model. Streaming is useful for large extractions where you want to process results as they arrive rather than waiting for the full response. See the instructor documentation for the streaming API details.
What happens when the model cannot extract a field?
If the field is typed as Optional[X], the model will return None for missing information. If the field is required (non-Optional), the model will either hallucinate a value or fail validation, triggering a retry. For fields that may legitimately be absent in the source text, always use Optional with a None default. This is the most common mistake new users make.
Can I extract data from large documents?
Yes, but be aware of token limits. For documents larger than a few thousand words, split them into chunks and extract from each chunk separately. Use a List[YourModel] return type if a single document contains multiple items to extract (like a list of transactions in a bank statement). For very large documents, consider summarizing first with a regular completion call, then extracting from the summary.
How is this different from just prompting for JSON output?
Prompting for JSON works until it does not — the model adds markdown fences, writes a preamble sentence, or omits fields. instructor uses tool calling (not prompting) to enforce the schema, so the model cannot deviate from the structure. It also runs Pydantic validation on the result and retries if types or constraints are violated. The difference in reliability for production use is significant — JSON prompting is fine for experiments, but instructor is the right tool for pipelines where data quality matters.
Is my data sent to OpenAI when I use instructor?
instructor is a thin wrapper around the OpenAI SDK — your data goes to whatever API endpoint you configure, subject to that provider’s data policy. If you are processing sensitive data, use a self-hosted model via Ollama or another local inference server, and point instructor at your local endpoint with a custom base_url. The library itself does not send data anywhere — it only wraps the client you provide.
Conclusion
The instructor library solves one of the most persistent frustrations in LLM application development: getting the model to return data in the shape your code expects, every time. We covered patching the OpenAI client, defining Pydantic schemas with field descriptions, extracting nested and list objects, adding custom validation rules, configuring retries and modes, and using instructor with non-OpenAI providers. The job extraction pipeline demonstrated how these pieces combine into a production-ready pattern.
The next step is to extend the real-life example: add a web scraper to pull live job postings, or connect the extracted data to a database. With instructor handling the model-to-schema translation, you can focus entirely on the business logic of what to extract and what to do with it.
Full documentation and more examples are at python.useinstructor.com. The library’s GitHub has a large collection of real-world examples including classification, knowledge graph extraction, and citation-backed answers.
Deta Space offers a free tier for personal use. The original Deta.sh Micros service has evolved. For free Python hosting alternatives, consider Railway, Render, PythonAnywhere, or Google Cloud Run’s free tier.
What are the best free Python hosting alternatives?
PythonAnywhere offers a free tier for web apps. Render provides free static sites and web services. Railway has a free trial. Google Cloud Run and AWS Lambda have generous free tiers for serverless deployments.
How do I deploy a Python Flask app for free?
Use Render (connect GitHub repo), PythonAnywhere (upload directly), or Railway (deploy from GitHub). Each provides different advantages for hobby and small-scale projects.
What should I consider when choosing Python hosting?
Consider free tier limits, sleep/cold-start behavior, database availability, custom domain support, deployment method, Python version support, and scaling options.
Can I host a Python bot or script for free?
Yes. PythonAnywhere allows always-on tasks. Google Cloud Functions and AWS Lambda handle event-driven scripts. For Discord/Telegram bots, Railway and Render offer free tiers suitable for small bots.
The python await and async is one of the more advanced features to help run your programs faster by making sure the CPU is spending as little time as possible waiting and instead as much time as possible working. If ever you see a capable chef, you’ll know what I mean. The chef is not just following a recipe step by step (i.e. working synchronously), the chef is boiling water to cook the pasta , measuring the amount of pasta, chopping tomatoes for the pasta sauce until the water boils etc (i.e. the chef is working asynchronously). The chef is minimizing the time they are waiting idle and always working on a task. That’s the same idea with async and await.
For this tutorial, we will focus on python 3.7 as it has some of the more modern features of await and async. We will call out some of the differences for python 3.4 – 3.6.
What is async await in Python?
The async await keywords help to define in your program which parts need to run sequentially, and which parts may take sometime but other parts of the program can execute while this step completes. A modern example of this is that if you’re downloading a web page it may take a few seconds, while the download is happening you can execute other parts of your program.
How does async await work in Python?
Sometimes the best way to explain something is to show how you would achieve the same thing without the feature.
Continuing with the restaurant theme, suppose you are running a hamburger stall (you’re the waiter and the chef) and it is almost instant to collect payment for a customer and serve the final hamburger, but the most time consuming task is to cooking the beef patty which takes 2 seconds (one could only wish!).
See the below diagram:
Figure 1: Sequentially serving customers at a hamburger stall
In the above diagram:
Step 1: you would first get the order and collect the money from Customer 1
Step 2: you would then put a beef patty on the cook top and then wait for 2 seconds for the beef patty to cook. At the same time, Customer 1 is also waiting for 2 seconds.
Step 3: when the beef patty is cooked, you can then plate this onto a hamburger bun
Step 4: pass the final hamburger to Customer 1
Step 5: You would then start to serve Customer 2 (who has already been waiting 2 seconds for you to serve Customer 1). You can then repeat steps 2-4
With the above approach, Customer 1 would have their burger in about 2 seconds, Customer 2 approx 4 seconds, and then Customer 3 approx 6 seconds.
The equivalent code would be as follows:
import time, datetime, timeit
customer_queue = [ "C1", "C2", "C3" ]
def get_next_customer():
return customer_queue.pop(0) #Get the first customer from list
def cook_hamburger(customer):
start_customer_timer = timeit.default_timer()
print( f"[{customer}]: Start cooking hamberger for customer")
time.sleep(2) # It takes 2 seconds to cook the hamburger
end_customer_timer = timeit.default_timer()
print( f"[{customer}]: Finish cooking hamberger for customer. Total {end_customer_timer-start_customer_timer} seconds\n")
def run_shop():
while customer_queue:
curr_customer = get_next_customer()
cook_hamburger(curr_customer)
def main():
print('Hamburger Shop')
start = timeit.default_timer()
run_shop()
stop = timeit.default_timer()
print(f"** Total runtime: {stop-start} seconds ***")
if __name__ == '__main__':
main()
The code above is fairly straightforward. We have a list of customers that are queuing in the list customer_queue which are being looped under the def run_shop(). For each customer (get_next_customer()), we call cook_hamburger() to cook the hamburger for 2 seconds and wait for it to complete.
Running this code you would get the following output:
As expected, the total runtime for 3 customers is 6 seconds since each customer is served sequentially.
Cooking Hamburgers Asynchronously and coding the event loop manually
Instead of serving the customer and cooking the hamburger for each customer, you can obviously do some of the tasks asynchronously, meaning you can start the task but you don’t have to sit and wait, you can do something else. See the following diagram where the chef/waiter is serving multiple customers and cooking at the same time. It’s not explicitly shown here, but the chef/waiter is constantly checking on the status of the next task and if a task doesn’t require his/her attention they’ll move on to the next task. This process of always looking for something to do is the equivalent of the “event loop”. The Event Loop is a programming construct where the logic is to always look for a task to execute and if there’s a task which will take some time it can release control to the next task in the loop.
Figure 2: Example of how the event loop works in a real life example – the chef/waiter is always busy!
In the above example, the following is happening:
Step 1: you would first get the order and collect the money from Customer 1
Step 2: you would then put a beef patty on the cook top and then let it cook, then immediately move on to the next customer while the patty is cooking.
Step 3: you would first get the order and collect the money from Customer 2. You would also check if the first beef patty has completed cooking yet.
Step 4: you would then put another beef patty on the cook top and then let it cook, then immediately move on to the next customer while the patty is cooking.
…
Step 5: When any of the beef patties are done, you would plate it
Step 6: Pass the plated hamburger to the respective customer. Note, in the above example we’ve assumed it to be Customer 1, but it could be any customer depending on which beef patty cooked fully first.
Step 7: When any of the beef patties are done, you would plate it, and server
This is the equivalent of the event loop. The chef/waiter is constantly checking if it needs to serve the customer or check on the hamburgers which are cooking. When there’s a hamburger is placed on the stove and we need to wait 2 seconds, the chef/waiter moves to the next task and does not wait for the 2 seconds to complete. When the hamburger is done, it is then served to the customer.
How can this be done programatically? Glad you asked:
import time ,datetime, timeit
customer_queue = [ "C1", "C2", "C3" ]
hamburger_queue = []
def get_next_customer():
if customer_queue: return customer_queue.pop(0) #Get the first customer from list
return None
def start_cooking_hamburger(customer):
print( f"[{customer}]: Start cooking hamberger for customer")
hamburger = { "customer":customer, "start_cooking_time": timeit.default_timer(), "cooked":False}
hamburger_queue.append( hamburger )
def check_hamburger_status():
curr_timer = timeit.default_timer()
#Check if it's cooking, but release control
for index, hamburger in enumerate(hamburger_queue):
elapsed_time = curr_timer-hamburger['start_cooking_time']
if elapsed_time > 2: #2 second has passed for hamrburger to cook
print( f"[{hamburger['customer']}]: Finish cooking hamberger for customer. Total {elapsed_time} seconds\n")
del hamburger_queue[ index]. #delete from list to mark as done
def run_shop():
while customer_queue or hamburger_queue: #Event loop
curr_customer = get_next_customer()
if curr_customer: start_cooking_hamburger(curr_customer)
check_hamburger_status()
def main():
print('Hamburger Shop')
start = timeit.default_timer()
run_shop()
stop = timeit.default_timer()
print(f"** Total runtime: {stop-start} seconds ***")
if __name__ == '__main__':
main()
The output of the code is as follows:
Output running asynchronously – notice the runtime of 2 seconds compared to the 6 seconds in the synchronsous method.
So there’s a few things happening here:
There’s a new list called hamburger_queue[] which is keeping track of each hamburger that is being cooked
The event loop is the while customer_queue or hamburger_queue within the run_shop() function
We have a new function called start_cooking_hamburger() which helps to keep track of the task to cooking starting. Why is this needed? Well in the past we would simply wait for a given task. Now, since we are doing something else while we wait, we need to remember a few things to come back to the task
We also have a new function called check_hamburger_status() which checks the status of each hamburger being cooked (i.e. item in hamburger_queue[]), and if it is cooked (i.e. 2 seconds have passed), then it is considered complete
You may notice in the output that Customer 3 was in fact served before Customer 2. This is because that the execution order is not guarantee.
You ask an LLM to extract a user’s name, age, and email from a paragraph of text. Sometimes it returns clean JSON. Sometimes it returns JSON wrapped in markdown fences. Sometimes it returns a paragraph explaining why it extracted those fields. If you have ever built a pipeline that breaks because the model decided today was a good day to add “Sure! Here is the extracted data:” before the JSON, you already understand why instructor exists.
The instructor library patches the OpenAI client (and any OpenAI-compatible API) to force the model to return a fully validated Pydantic model — every time. When validation fails, it retries automatically. You define exactly what fields you need, with their types and constraints, and instructor handles the conversation with the model until the output matches your schema. You need Python 3.9+, an OpenAI API key (or compatible endpoint), and pip install instructor.
This article walks through everything you need to get structured LLM outputs in production: installing and patching the client, defining Pydantic schemas, extracting nested objects, handling lists, using validation hooks, working with non-OpenAI models via LiteLLM, and building a real extraction pipeline. By the end you will have a reusable pattern for reliable structured data from any LLM.
Structured LLM Output: Quick Example
The fastest way to see instructor in action is to extract a structured object from a single sentence. Install the library and try this:
# quick_instructor.py
import instructor
from openai import OpenAI
from pydantic import BaseModel
client = instructor.from_openai(OpenAI())
class Person(BaseModel):
name: str
age: int
city: str
person = client.chat.completions.create(
model="gpt-4o-mini",
response_model=Person,
messages=[{"role": "user", "content": "Alice is 32 years old and lives in Melbourne."}]
)
print(person.name) # Alice
print(person.age) # 32
print(person.city) # Melbourne
print(type(person)) # <class '__main__.Person'>
Output:
Alice
32
Melbourne
<class '__main__.Person'>
The key line is instructor.from_openai(OpenAI()) — this patches the standard OpenAI client. After that, you pass response_model=Person to any chat.completions.create call, and instructor automatically: sends the Pydantic schema to the model as a tool definition, parses the model’s tool-call response, validates it against your schema, and retries if validation fails. The return value is a fully typed Pydantic object, not a string or dict.
That example covers the simplest case. The sections below show how to handle nested models, lists, validation rules, retry configuration, and real-world pipelines.
response_model= and the chaos becomes a schema.
What Is instructor and Why Use It?
When you call an LLM without constraints, it returns free-form text. Parsing that text into structured data is fragile — you write regex, JSON parsers, and fallback handlers that break every time the model changes its wording. instructor solves this by using OpenAI’s function/tool calling feature under the hood: it converts your Pydantic model into a JSON Schema tool definition, forces the model to call that tool, and validates the returned arguments against your schema.
The result is LLM output that behaves like a typed function return value instead of a string you have to parse. If the model returns a field with the wrong type (for example, age as a string “thirty-two” instead of an integer), instructor sends the validation error back to the model and asks it to try again — up to a configurable number of retries.
Approach
Reliability
Type Safety
Auto-Retry
Parse raw LLM text
Fragile
None
Manual
Parse JSON from prompt
Moderate
Manual
Manual
OpenAI function calling
Good
Partial
None
instructor + Pydantic
High
Full
Built-in
The library supports multiple backends: instructor.from_openai, instructor.from_anthropic, instructor.from_gemini, and any OpenAI-compatible endpoint via base_url. This makes it the same interface regardless of which model you use.
Installation and Setup
Install instructor and the OpenAI SDK together. If you are using a different provider, you may also need their SDK:
# Terminal
pip install instructor openai pydantic
Set your API key as an environment variable so it never appears in your code:
# setup_env.py -- run once, or add to your shell profile
import os
# In practice, set this in your shell:
# export OPENAI_API_KEY="sk-..."
print("OPENAI_API_KEY set:", bool(os.environ.get("OPENAI_API_KEY")))
Output:
OPENAI_API_KEY set: True
Patch the client once at startup and reuse it for all calls. Creating a new patched client for every request is wasteful:
# client_setup.py
import instructor
from openai import OpenAI
# Patch once at startup
client = instructor.from_openai(OpenAI()) # reads OPENAI_API_KEY from env
# The client now has response_model support on all completion calls
print(type(client)) # <class 'instructor.client.Instructor'>
Output:
<class 'instructor.client.Instructor'>
One patch. Every completion call now speaks schema.
Defining Pydantic Schemas for Extraction
Your Pydantic model defines exactly what fields the LLM must return. Field descriptions improve accuracy significantly — the model uses them as instructions for what to put in each field. Use Field(description=...) to guide the extraction:
# schema_example.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import Optional
client = instructor.from_openai(OpenAI())
class JobPosting(BaseModel):
title: str = Field(description="The exact job title as written in the posting")
company: str = Field(description="Company name offering the position")
location: str = Field(description="City and country, or 'Remote'")
salary_min: Optional[int] = Field(None, description="Minimum annual salary in USD if mentioned")
salary_max: Optional[int] = Field(None, description="Maximum annual salary in USD if mentioned")
is_remote: bool = Field(description="True if the role allows remote work")
text = """
Senior Python Developer at DataFlow Inc. -- Remote (US timezones preferred).
Salary range: $140,000 - $175,000 per year. Must have 5+ years Python experience.
"""
job = client.chat.completions.create(
model="gpt-4o-mini",
response_model=JobPosting,
messages=[{"role": "user", "content": f"Extract the job details from: {text}"}]
)
print(f"Title: {job.title}")
print(f"Company: {job.company}")
print(f"Location: {job.location}")
print(f"Salary: ${job.salary_min:,} - ${job.salary_max:,}")
print(f"Remote: {job.is_remote}")
The Optional[int] type tells instructor (and the model) that salary fields may be absent. When the source text does not mention a salary, these fields will be None instead of hallucinated values. Always use Optional for fields that may not appear in the input — without it, the model will invent plausible-sounding values rather than leaving the field empty.
Extracting Nested and List Objects
Real-world extraction often requires nested structures — for example, an invoice with multiple line items, or a resume with a list of work experiences. instructor handles nested Pydantic models and List types natively:
# nested_extraction.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import List
client = instructor.from_openai(OpenAI())
class LineItem(BaseModel):
description: str
quantity: int
unit_price: float
class Invoice(BaseModel):
vendor: str
invoice_number: str
items: List[LineItem]
total: float
invoice_text = """
Invoice #INV-2024-0891 from CloudHost Solutions
- 3x Server instances @ $45.00 each
- 1x SSL Certificate @ $12.00
- 2x Domain registrations @ $15.00 each
Total: $222.00
"""
result = client.chat.completions.create(
model="gpt-4o-mini",
response_model=Invoice,
messages=[{"role": "user", "content": f"Extract invoice data: {invoice_text}"}]
)
print(f"Vendor: {result.vendor}")
print(f"Invoice #: {result.invoice_number}")
for item in result.items:
print(f" {item.quantity}x {item.description} @ ${item.unit_price:.2f}")
print(f"Total: ${result.total:.2f}")
Nested models work because instructor converts the entire schema — including nested classes — into a JSON Schema definition that the model understands. The model fills in every field of every nested object, and Pydantic validates the whole structure recursively. If the items list is missing or a line item has an invalid type, instructor retries the extraction with the validation error as feedback.
Nested Pydantic models: recursion that actually works.
Adding Custom Validation Rules
Pydantic’s field_validator lets you add business logic on top of type checking. instructor automatically feeds validation errors back to the model, so the model gets a second (or third) chance to return values that satisfy your rules:
# custom_validation.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field, field_validator
from typing import List
client = instructor.from_openai(OpenAI())
class ProductReview(BaseModel):
product_name: str
rating: int = Field(description="Rating from 1 to 5")
pros: List[str] = Field(description="List of positive aspects, at least one")
cons: List[str] = Field(description="List of negative aspects, can be empty")
summary: str = Field(description="One-sentence summary under 150 characters")
@field_validator("rating")
@classmethod
def rating_in_range(cls, v: int) -> int:
if not 1 <= v <= 5:
raise ValueError(f"Rating must be between 1 and 5, got {v}")
return v
@field_validator("pros")
@classmethod
def at_least_one_pro(cls, v: List[str]) -> List[str]:
if not v:
raise ValueError("Must include at least one positive aspect")
return v
@field_validator("summary")
@classmethod
def summary_length(cls, v: str) -> str:
if len(v) > 150:
raise ValueError(f"Summary too long: {len(v)} chars (max 150)")
return v
text = """
The new Python IDE is pretty solid. Boot time is fast, autocomplete works well.
The memory usage is high and the plugin store is still sparse. Overall a decent
choice for Python development. I'd give it 4 out of 5.
"""
review = client.chat.completions.create(
model="gpt-4o-mini",
response_model=ProductReview,
messages=[{"role": "user", "content": f"Extract review details: {text}"}]
)
print(f"Product: {review.product_name}")
print(f"Rating: {review.rating}/5")
print(f"Pros: {review.pros}")
print(f"Cons: {review.cons}")
print(f"Summary: {review.summary}")
Output:
Product: Python IDE
Rating: 4/5
Pros: ['Fast boot time', 'Good autocomplete']
Cons: ['High memory usage', 'Sparse plugin store']
Summary: A solid Python IDE with fast performance but limited plugins and high memory usage.
When a validator raises ValueError, instructor captures the error message and sends it back to the model in a follow-up message: “Validation failed: Rating must be between 1 and 5, got 6. Please fix and try again.” The model then self-corrects. By default, instructor retries up to 3 times before raising an exception. You can configure this with max_retries=N on the completion call.
Configuring Retries and Modes
instructor supports several extraction modes depending on what your model supports. The default mode uses OpenAI’s tool calling, but you can switch to JSON mode or other strategies:
# retry_config.py
import instructor
from instructor import Mode
from openai import OpenAI
from pydantic import BaseModel
# Default: tool calling (most reliable for OpenAI models)
client_tools = instructor.from_openai(OpenAI())
# JSON mode: model returns raw JSON instead of a tool call
client_json = instructor.from_openai(OpenAI(), mode=Mode.JSON)
# MD_JSON mode: model wraps JSON in markdown fences (useful for some fine-tunes)
client_md = instructor.from_openai(OpenAI(), mode=Mode.MD_JSON)
class City(BaseModel):
name: str
country: str
population: int
# Control retries per-call
city = client_tools.chat.completions.create(
model="gpt-4o-mini",
response_model=City,
max_retries=5, # retry up to 5 times on validation failure
messages=[{"role": "user", "content": "Tell me about Tokyo"}]
)
print(f"{city.name}, {city.country}: pop {city.population:,}")
Output:
Tokyo, Japan: pop 13,960,000
For most OpenAI models, the default tool-calling mode is most reliable. Use Mode.JSON for models that support JSON mode but not tool calling — for example, some fine-tuned models or older GPT versions. The max_retries parameter controls how many times instructor will re-prompt the model when validation fails. For production pipelines where data quality matters more than cost, set this to 3-5.
Three retries and a Pydantic error. That’s the whole self-correction system.
Using instructor with Non-OpenAI Models
If you are using Anthropic’s Claude, Google Gemini, or a local model via Ollama, instructor has provider-specific patches. For OpenAI-compatible endpoints (like local LLMs with an OpenAI-compatible API), you can pass a custom base_url:
# multi_provider.py
import instructor
from anthropic import Anthropic
from pydantic import BaseModel
# Anthropic Claude -- uses a different client class
anthropic_client = instructor.from_anthropic(Anthropic())
class Sentiment(BaseModel):
label: str # "positive", "negative", or "neutral"
score: float # confidence from 0.0 to 1.0
reason: str # one-sentence explanation
result = anthropic_client.messages.create(
model="claude-3-haiku-20240307",
max_tokens=256,
response_model=Sentiment,
messages=[{
"role": "user",
"content": "This new Python library is fantastic, saves me hours every week!"
}]
)
print(f"Sentiment: {result.label} ({result.score:.0%})")
print(f"Reason: {result.reason}")
Output:
Sentiment: positive (96%)
Reason: The user expresses strong enthusiasm and quantifies time savings, indicating genuine satisfaction.
For local models via Ollama (which provides an OpenAI-compatible API on localhost:11434), create the client with a custom base URL:
# ollama_instructor.py
import instructor
from openai import OpenAI
from pydantic import BaseModel
# Ollama runs an OpenAI-compatible server locally
ollama_client = instructor.from_openai(
OpenAI(base_url="http://localhost:11434/v1", api_key="ollama"),
mode=instructor.Mode.JSON # use JSON mode for local models
)
class Summary(BaseModel):
headline: str
key_points: list[str]
# Works the same as OpenAI -- just a different backend
# summary = ollama_client.chat.completions.create(
# model="llama3.2",
# response_model=Summary,
# messages=[{"role": "user", "content": "Summarize Python's async/await model"}]
# )
print("Local model client ready -- uncomment to use with Ollama running")
Output:
Local model client ready -- uncomment to use with Ollama running
Here is a complete pipeline that reads job postings from a list of texts, extracts structured data, filters by criteria, and exports to CSV — the kind of task that comes up in recruiting tools, market research, and job aggregators:
Structured extraction at scale: parsing 50 job posts is just a for loop.
# job_extraction_pipeline.py
import instructor
import csv
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import Optional, List
client = instructor.from_openai(OpenAI())
class JobPosting(BaseModel):
title: str = Field(description="Job title exactly as written")
company: str
location: str = Field(description="City/country or 'Remote'")
salary_min: Optional[int] = Field(None, description="Min annual salary USD")
salary_max: Optional[int] = Field(None, description="Max annual salary USD")
required_years: Optional[int] = Field(None, description="Years of experience required")
technologies: List[str] = Field(description="List of technologies mentioned")
is_remote: bool
# Sample job postings to process
JOB_TEXTS = [
"""Senior Python Engineer at Nexaflow -- Remote-first.
$150k-$190k. 5+ years Python, FastAPI, PostgreSQL, AWS required.""",
"""Junior Data Scientist at BioMetrics Ltd (London, UK).
GBP 45,000-55,000. 0-2 years exp, pandas, scikit-learn, matplotlib.""",
"""Staff ML Engineer at Quantra -- San Francisco CA.
$220,000 - $280,000/yr. 8+ years, PyTorch, CUDA, distributed training.""",
]
def extract_jobs(texts: List[str]) -> List[JobPosting]:
"""Extract structured job data from raw posting texts."""
jobs = []
for i, text in enumerate(texts, 1):
job = client.chat.completions.create(
model="gpt-4o-mini",
response_model=JobPosting,
max_retries=3,
messages=[{"role": "user", "content": f"Extract job details:\n\n{text}"}]
)
jobs.append(job)
print(f"[{i}/{len(texts)}] Extracted: {job.title} at {job.company}")
return jobs
def filter_remote(jobs: List[JobPosting]) -> List[JobPosting]:
return [j for j in jobs if j.is_remote]
def export_csv(jobs: List[JobPosting], path: str) -> None:
with open(path, "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(["Title", "Company", "Location", "Salary Min", "Salary Max",
"Yrs Required", "Technologies", "Remote"])
for j in jobs:
writer.writerow([
j.title, j.company, j.location,
j.salary_min or "", j.salary_max or "",
j.required_years or "",
", ".join(j.technologies),
j.is_remote
])
if __name__ == "__main__":
print("Extracting job postings...")
jobs = extract_jobs(JOB_TEXTS)
remote_jobs = filter_remote(jobs)
print(f"\nTotal extracted: {len(jobs)}, Remote: {len(remote_jobs)}")
export_csv(jobs, "jobs_extracted.csv")
print("Saved to jobs_extracted.csv")
Output:
Extracting job postings...
[1/3] Extracted: Senior Python Engineer at Nexaflow
[2/3] Extracted: Junior Data Scientist at BioMetrics Ltd
[3/3] Extracted: Staff ML Engineer at Quantra
Total extracted: 3, Remote: 1
Saved to jobs_extracted.csv
This pipeline is easy to extend: add a database write step, connect it to a web scraper that feeds real job pages, or add more validation rules to the JobPosting model. The core pattern — extract once, validate automatically, retry on failure — stays the same regardless of the scale. You can process thousands of postings by replacing JOB_TEXTS with a generator that reads from a queue or database, keeping the extraction logic identical.
Frequently Asked Questions
Does instructor increase API costs because of retries?
Yes, each retry is an additional API call, so failed extractions cost more. In practice, with well-designed schemas and clear field descriptions, validation failures are rare — under 5% for most extraction tasks. The cost increase is usually worth the reliability gain. If cost is a concern, use max_retries=1 and handle exceptions in your code rather than retrying automatically.
Does instructor support streaming responses?
Yes. Use response_model=Iterable[YourModel] for streaming lists, or Partial[YourModel] for streaming partial updates to a single model. Streaming is useful for large extractions where you want to process results as they arrive rather than waiting for the full response. See the instructor documentation for the streaming API details.
What happens when the model cannot extract a field?
If the field is typed as Optional[X], the model will return None for missing information. If the field is required (non-Optional), the model will either hallucinate a value or fail validation, triggering a retry. For fields that may legitimately be absent in the source text, always use Optional with a None default. This is the most common mistake new users make.
Can I extract data from large documents?
Yes, but be aware of token limits. For documents larger than a few thousand words, split them into chunks and extract from each chunk separately. Use a List[YourModel] return type if a single document contains multiple items to extract (like a list of transactions in a bank statement). For very large documents, consider summarizing first with a regular completion call, then extracting from the summary.
How is this different from just prompting for JSON output?
Prompting for JSON works until it does not — the model adds markdown fences, writes a preamble sentence, or omits fields. instructor uses tool calling (not prompting) to enforce the schema, so the model cannot deviate from the structure. It also runs Pydantic validation on the result and retries if types or constraints are violated. The difference in reliability for production use is significant — JSON prompting is fine for experiments, but instructor is the right tool for pipelines where data quality matters.
Is my data sent to OpenAI when I use instructor?
instructor is a thin wrapper around the OpenAI SDK — your data goes to whatever API endpoint you configure, subject to that provider’s data policy. If you are processing sensitive data, use a self-hosted model via Ollama or another local inference server, and point instructor at your local endpoint with a custom base_url. The library itself does not send data anywhere — it only wraps the client you provide.
Conclusion
The instructor library solves one of the most persistent frustrations in LLM application development: getting the model to return data in the shape your code expects, every time. We covered patching the OpenAI client, defining Pydantic schemas with field descriptions, extracting nested and list objects, adding custom validation rules, configuring retries and modes, and using instructor with non-OpenAI providers. The job extraction pipeline demonstrated how these pieces combine into a production-ready pattern.
The next step is to extend the real-life example: add a web scraper to pull live job postings, or connect the extracted data to a database. With instructor handling the model-to-schema translation, you can focus entirely on the business logic of what to extract and what to do with it.
Full documentation and more examples are at python.useinstructor.com. The library’s GitHub has a large collection of real-world examples including classification, knowledge graph extraction, and citation-backed answers.
In the previous section we created an asynchronous version manually. Here’s the same outcome but written with the async await syntax. As you’ll notice it is very similar to the original synchronous version:
import time, datetime, time
import asyncio
import time, datetime, timeit
customer_queue = [ "C1", "C2", "C3" ]
def get_next_customer():
return customer_queue.pop(0) #Get the first customer from list
async def cook_hamburger(customer):
start_customer_timer = timeit.default_timer()
print( f"[{customer}]: Start cooking hamberger for customer")
await asyncio.sleep(2) # Sleep but release control
end_customer_timer = timeit.default_timer()
print( f"[{customer}]: Finish cooking hamberger for customer. Total {end_customer_timer-start_customer_timer} seconds\n")
async def run_shop():
cooking_queue = []
while customer_queue:
curr_customer = get_next_customer()
cooking_queue.append( cook_hamburger(curr_customer) ) #this returns a task only
#cooking_queue[] has all the async tasks
await asyncio.gather( *cooking_queue ) #Run all in parallel
def main():
print('Hamburger Shop')
start = timeit.default_timer()
asyncio.run( run_shop() ) #Start the event loop
stop = timeit.default_timer()
print(f"** Total runtime: {stop-start} seconds ***")
if __name__ == '__main__':
main()
Output as follows:
Let’s walk through the code:
Firstly, the async await is available from the library asyncio hence the import asyncio
There’s funny set of async keywords which precede the def run_shop() and the def cook_hamburger(customer) functions. In addition the run_shop() is no longer called directly, instead it is called with a asyncio.run( run_shop() ) function call. So here’s what is happening:
The asyncio.run() function is the trigger for the so-called event loop. It continues to run forever until all the tasks given to it are completed. You must pass it a function with the async def... prefix hence why run_shop() has the async prefix
In the async def run_shop() function call, the code iterates while there are customers in the queue to process, and then there’s a call to cook_hamburger(curr_customer) for each customer. A direct call to the customer does not actually call the function but instead creates a task to execute this. That is what the async tells the compiler – that when called directly, return a task.
At the end of the function code in def run_shop() there’s a call to function await asyncio.gather( *cooking_queue). There’s a few things going on here:
The await keywords indicates that you need wait for the work to complete but python can do something else in the meantime
The call to gather() actually executes all the tasks given to it as a parameter collectively as a group and then returns the results sequentially (please note that the order of the tasks being executed may be random)
The *customer_queue simply expands the list into a list of parameter items. So for example if customer_queue[] == [ '1', '2', '3'] then the gather( *customer_queue) would be the same as gather( '1', '2', '3').
When the await asyncio.gather( *customer_queue ) is called, the await keyword releases control to any activities that are pending and one of them would be to the calls to function cook_hamburger() which was added to the customer_queue list. Hence calls to cook_hamburger() would be triggered.
Within cook_hamburger() there is also an await asyncio.sleep(2). This simply waits for 2 seconds, however, it does not force the program to wait for the 2 seconds to complete, instead the await keyword releases python to do something else in the meantime. This is similar to step 3 in Figure 2 where the chef/waiter puts the hamburger on the grill, but then doesn’t wait for the 2 second but instead does something else (i.e. serve the next customer)
The asyncio.run() are new keywords as part of python 3.7. In older versions of python you may see the following but it is the same as simply running asyncio.run( run_shop() ) :
loop = asyncio.get_event_loop()
loop.run_until_complete(run_shop())
loop.close()
As you will notice, this is very similar to the synchronous code that covers Figure 1 above. This is the beauty of async/await
So remember, whenever there’s an await then that means python pauses at that point for that task to complete but then also releases python to do something else. That’s how the performance improvement occurs. In this example, the runtime of this is 2 seconds instead of the sequential 6 seconds!
Async Asynchronous Calling Another Async Function Code Example
Suppose you want t also call another async function once your first async function is completed – how do you go about this? Remember the rule, if you want to run something asynchronously, you have to use the await keyword, and that the function you’re calling has to be defined with async def ...
To continue with the restaurant theme, suppose that after the hamburger is cooked you ask an assistant to put the hamburger into a takeaway bag which takes 1 second. This is also another task that you need not ‘block’ and wait for it to complete. Hence, this action can be put into a function which is defined as an async. Here’s what the code can look like:
import time, datetime, time
import asyncio
customer_queue = [ "C1", "C2", "C3" ]
def get_next_customer():
return customer_queue.pop(0) #Get the first customer from list
async def cook_hamburger(customer):
start_customer_timer = timeit.default_timer()
print( f"[{customer}]: Start cooking hamberger for customer")
await asyncio.sleep(2) # Sleep but release control
end_customer_timer = timeit.default_timer()
print( f"[{customer}]: Finish cooking hamberger for customer. Total {end_customer_timer-start_customer_timer} seconds")
await put_hamburger_in_takeaway_bag( customer )
async def put_hamburger_in_takeaway_bag( customer):
start_customer_timer = timeit.default_timer()
print( f"[{customer}]: Start packing hamberger")
await asyncio.sleep(1) # It takes 2 seconds to cook the hamburger
end_customer_timer = timeit.default_timer()
print( f"[{customer}]: Finish packing hamberger. Total {end_customer_timer-start_customer_timer} seconds\n")
async def run_shop():
cooking_queue = []
while customer_queue:
curr_customer = get_next_customer()
cooking_queue.append( cook_hamburger(curr_customer) ) #Get each of the event loops
await asyncio.gather( *cooking_queue ) #Run all in parallel
def main():
print('Hamburger Shop')
start = timeit.default_timer()
asyncio.run( run_shop() ) #Start the event loop
stop = timeit.default_timer()
print(f"** Total runtime: {stop-start} seconds ***")
if __name__ == '__main__':
main()
The output would be:
See how once the hamburger is cooked (e.g. [C1]: Finish cooking hamburger for customer. Total 2.000924572115764 seconds), then immediately afterwards you have the [C1]: Start packing hamburger step but also gets called asynchronously.
Async Await Real World Example With Web Crawler in Python
One difficulty in learning Async / Await is that many examples provided simply provide the asyncio.sleep() as an example which is helpful to understand the concept, but not very helpful when you want to make something more useful. Let’s try a more complex example where you want to get some stock data from finance.yahoo.com and then, for that same stock, you also get the first 3 newspaper articles from news.google.com in the last 24 hours.
Now one thing you will realise is that await only works with functions that are defined as async. So you cannot call any function with await. Why? Well recall that when you call await you are expecting a function to return a task and not actually call the function, hence that function needs to be defined as async in order to tell python that it returns a task to be executed at the next available time.
Let’s see the synchronous version of the code:
import asyncio, requests, timeit
from bs4 import BeautifulSoup
from pygooglenews import GoogleNews
stock_list = [ "TSLA", "AAPL"]
def get_stock_price_data(stock):
print(f"-- getting stock data for {stock}")
data = {"stock":stock, "price_open":0, "price_close":0 }
stock_page = requests.get( 'https://finance.yahoo.com/quote/' + stock, headers={'Cache-Control': 'no-cache', "Pragma": "no-cache"})
soup = BeautifulSoup(stock_page.text, 'html.parser')
#<fin-streamer active="" class="Fw(b) Fz(36px) Mb(-4px) D(ib)" data-field="regularMarketPrice" data-pricehint="2" data-symbol="TSLA" data-test="qsp-price" data-trend="none" value="759.63">759.63</fin-streamer>
data['price_close'] = soup.find('fin-streamer', attrs={"data-symbol":stock, "data-field":"regularMarketPrice"} ).text
#<td class="Ta(end) Fw(600) Lh(14px)" data-test="OPEN-value">723.25</td>
data['price_open'] = soup.find( attrs={"data-test":"OPEN-value"}).text
return data
def get_recent_news(stock):
print(f"-- getting news data for {stock}")
gn = GoogleNews()
search = gn.search(f"stocks {stock}", when = '24h')
news = search['entries'][0:3]
return news
def print_stock_update(stock, data, news):
print(f"Stock:{ stock }")
price_change = 0
if int(float(data['price_open'])) != 0: price_change = round( 100 * ( float( data['price_close'])/float(data['price_open'])-1), 2)
print(f"Open Price:{data['price_open']} Close Price:{data['price_close']} Change:{price_change}% ")
print("Latest News:")
for news_item in news:
print( f"{news_item.published}:{news_item.source.title} - {news_item.title}" )
print("\n")
def process_stocks():
for stock in stock_list:
data = get_stock_price_data( stock )
news=[]
news = get_recent_news( stock )
print_stock_update(stock, data, news)
if __name__ == '__main__':
start_timer = timeit.default_timer()
process_stocks()
end_timer = timeit.default_timer()
print(f"** Total runtime: {end_timer-start_timer} seconds ***")
Output as follows:
So what’s happening here. Well, you are looping through two stocks TSLA and AAPL, and for each stock the following happens sequentially:
A call to data = get_stock_price_data( stock ) occurs in order to make a call to requests.get( 'https://finance.yahoo.com/quote/' + stock) to get the HTML page for the TSLA stock. Effectively, this page: https://finance.yahoo.com/quote/TSLA
Next we use BeautifulSoup() in order to find the HTML snippet that contains the stock price data for the opening price and the closing price:
After the call to yahoo is complete, then there’s a call to news = get_recent_news( stock ) which uses the module pygooglenews to get the latest google news. In fact we have used this function in our previous Twitter Botarticle.
Once this is all done, that output is printed out with the call to print_stock_update(stock, data, news)
Clearly this could be called asynchronously as we are looping each time for each stock, and then also the call to get the stock data is independent to getting the news data. However, one thing has to happen sequentially is the print_stock_update(stock, data, news) which has to wait for both the async calls to complete.
One wait to try is to simply call the website download with:
The reason is, as you may have guessed, is that the requests.get() is not created with the async def... construct and hence cannot be called asynchronously.
What you can do however is to use another ‘get’ web page module called httpx. This function is defined with async def... and can be called similar to requests. That same line would be re-written as:
Ok, that works well. However, but what about the GoogleNews() code. There is no such async version of this function, so how can this be called asynchronously? Well for this, you can actually wrap it around a new thread. A ‘thread’ is way to run a piece of code under the same CPU process but in a parallel. It warrants a whole separate article but for now you can think of it as finding a separate space to execute this independent of the current execution path. However, to execute this in a separate thread, there’s a bit more involved.
The code looks like the following:
### Original Version
def get_recent_news(stock):
print(f"-- stock news:getting stock data for {stock}")
gn = GoogleNews()
search = gn.search(f"stocks {stock}", '24h') #Slow code to run asynchronously
news = search['entries'][0:3]
print(f"-- stock news:done {stock}")
return news
### Asynchronous Version
async def get_recent_news(stock):
print(f"-- stock news:getting stock data for {stock}")
gn = GoogleNews()
search = await asyncio.get_event_loop().run_in_executor( None, gn.search, f"stocks {stock}", '24h')
news = search['entries'][0:3]
print(f"-- stock news:done {stock}")
return news
Here what’s happening is that firstly we are using the await keyword to call the gn.search() function which is now being called through this asyncio.get_event_loop().run_in_executor( .. ) function call. What’s happening here is that we are asking the asyncio module to get access to the event loop (that piece of code that continuously checks for tasks to be done) and then to run in a separate thread. The way it is called is that the parameters must be passed in separate to the function call and hence why the parameters are to be passed in after the function name itself. You will also notice that the whole function can now be defined as async def get_recent_news(stock)
How To Mix Asynchronous And Synchronous Code With Await Async in Python
Now the final problem to be solved is how do we call the two functions of get_stock_price_data( stock ) and get_recent_news(stock) to be run asynchronously, but then wait for both to finish, and THEN run the print. This is where these steps should all be grouped under one function. This is the trick to mix asynchronous and synchronous code.
In order to run a group of tasks in parallel as a group you use asyncio.gather(). However, if you want to execute a synchronous function when ALL tasks that were given to asyncio.gather() is complete, then you should wrap it in another asyncio.gather()
What is encouraging with this code, is that even though the call to get_web_data_A() and get_web_data_B() both sleep for 1 second, since they were doing that asynchronously, then the total runtime is still just a little over 1 second. This can be shown by the Calculate [0]... output. However, the problem is that the code still iterates each index sequentially, meaning, that index 0 is processed completely first, and once that’s done, then index 1 is processed. What we want instead is to run all the slow get_web_data_A() and get_web_data_B() first, and then run the code to calculate afterwards. This is where you need to first create the tasks for ALL the iterations, and then call gather() on all the tasks. See the following code:
Here, in the function async def run_all_2() when we loop, we do not call the blocking code await asyncio.gather... inside the for loop. Instead, we are adding all the tasks to call process(..) into a list called task_queue[], and then at the end of the for loop we are calling await asyncio.gather( *task_queue ) on all tasks in one go. Hence, the output is as follows:
You’ll notice that ALL the get_web_data_A() and get_web_data_B() are being called asynchronously, and then the calculate function is called on all the available data. Hence, the elapsed time for all the iterations is only 1 second, compared to the previous 2 seconds.
So what does this mean for our real world example for getting stock data from Yahoo and then calling Google News asynchronously, and then only printing the data once both are done? Well, the same principle applies. The code is as follows:
The key bit of code is in the async def process_stocks() which now iterates over each of the stocks, creates tasks, and then calls await asyncio.gather( *run_stock_list ) on all the stocks in one go, and then in the function process_stock_batch(stock) we have the asynchronous call to (data, news) = await asyncio.gather( get_stock_price_data( stock ), and then the synchronous call to print_stock_update(stock, data, news) once both web data is complete.
Conclusion
The await and async function is an incredibly useful feature of python which takes a bit of getting used to in order to understand the concept, but once you’ve got the hang of it, it can be incredibly useful to get an improve of the performance of your code by leveraging idle time where you are waiting for a task to complete. Remember to be sure about the sequencing and being mindful of whether you care to have a follow-up activity once that task is completed, or you can simply continue to execute.
This not easy to grasp as a beginner, but follow the example code above, and if you get stuck feel free to reach out through our email list below.
You ask an LLM to extract a user’s name, age, and email from a paragraph of text. Sometimes it returns clean JSON. Sometimes it returns JSON wrapped in markdown fences. Sometimes it returns a paragraph explaining why it extracted those fields. If you have ever built a pipeline that breaks because the model decided today was a good day to add “Sure! Here is the extracted data:” before the JSON, you already understand why instructor exists.
The instructor library patches the OpenAI client (and any OpenAI-compatible API) to force the model to return a fully validated Pydantic model — every time. When validation fails, it retries automatically. You define exactly what fields you need, with their types and constraints, and instructor handles the conversation with the model until the output matches your schema. You need Python 3.9+, an OpenAI API key (or compatible endpoint), and pip install instructor.
This article walks through everything you need to get structured LLM outputs in production: installing and patching the client, defining Pydantic schemas, extracting nested objects, handling lists, using validation hooks, working with non-OpenAI models via LiteLLM, and building a real extraction pipeline. By the end you will have a reusable pattern for reliable structured data from any LLM.
Structured LLM Output: Quick Example
The fastest way to see instructor in action is to extract a structured object from a single sentence. Install the library and try this:
# quick_instructor.py
import instructor
from openai import OpenAI
from pydantic import BaseModel
client = instructor.from_openai(OpenAI())
class Person(BaseModel):
name: str
age: int
city: str
person = client.chat.completions.create(
model="gpt-4o-mini",
response_model=Person,
messages=[{"role": "user", "content": "Alice is 32 years old and lives in Melbourne."}]
)
print(person.name) # Alice
print(person.age) # 32
print(person.city) # Melbourne
print(type(person)) # <class '__main__.Person'>
Output:
Alice
32
Melbourne
<class '__main__.Person'>
The key line is instructor.from_openai(OpenAI()) — this patches the standard OpenAI client. After that, you pass response_model=Person to any chat.completions.create call, and instructor automatically: sends the Pydantic schema to the model as a tool definition, parses the model’s tool-call response, validates it against your schema, and retries if validation fails. The return value is a fully typed Pydantic object, not a string or dict.
That example covers the simplest case. The sections below show how to handle nested models, lists, validation rules, retry configuration, and real-world pipelines.
response_model= and the chaos becomes a schema.
What Is instructor and Why Use It?
When you call an LLM without constraints, it returns free-form text. Parsing that text into structured data is fragile — you write regex, JSON parsers, and fallback handlers that break every time the model changes its wording. instructor solves this by using OpenAI’s function/tool calling feature under the hood: it converts your Pydantic model into a JSON Schema tool definition, forces the model to call that tool, and validates the returned arguments against your schema.
The result is LLM output that behaves like a typed function return value instead of a string you have to parse. If the model returns a field with the wrong type (for example, age as a string “thirty-two” instead of an integer), instructor sends the validation error back to the model and asks it to try again — up to a configurable number of retries.
Approach
Reliability
Type Safety
Auto-Retry
Parse raw LLM text
Fragile
None
Manual
Parse JSON from prompt
Moderate
Manual
Manual
OpenAI function calling
Good
Partial
None
instructor + Pydantic
High
Full
Built-in
The library supports multiple backends: instructor.from_openai, instructor.from_anthropic, instructor.from_gemini, and any OpenAI-compatible endpoint via base_url. This makes it the same interface regardless of which model you use.
Installation and Setup
Install instructor and the OpenAI SDK together. If you are using a different provider, you may also need their SDK:
# Terminal
pip install instructor openai pydantic
Set your API key as an environment variable so it never appears in your code:
# setup_env.py -- run once, or add to your shell profile
import os
# In practice, set this in your shell:
# export OPENAI_API_KEY="sk-..."
print("OPENAI_API_KEY set:", bool(os.environ.get("OPENAI_API_KEY")))
Output:
OPENAI_API_KEY set: True
Patch the client once at startup and reuse it for all calls. Creating a new patched client for every request is wasteful:
# client_setup.py
import instructor
from openai import OpenAI
# Patch once at startup
client = instructor.from_openai(OpenAI()) # reads OPENAI_API_KEY from env
# The client now has response_model support on all completion calls
print(type(client)) # <class 'instructor.client.Instructor'>
Output:
<class 'instructor.client.Instructor'>
One patch. Every completion call now speaks schema.
Defining Pydantic Schemas for Extraction
Your Pydantic model defines exactly what fields the LLM must return. Field descriptions improve accuracy significantly — the model uses them as instructions for what to put in each field. Use Field(description=...) to guide the extraction:
# schema_example.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import Optional
client = instructor.from_openai(OpenAI())
class JobPosting(BaseModel):
title: str = Field(description="The exact job title as written in the posting")
company: str = Field(description="Company name offering the position")
location: str = Field(description="City and country, or 'Remote'")
salary_min: Optional[int] = Field(None, description="Minimum annual salary in USD if mentioned")
salary_max: Optional[int] = Field(None, description="Maximum annual salary in USD if mentioned")
is_remote: bool = Field(description="True if the role allows remote work")
text = """
Senior Python Developer at DataFlow Inc. -- Remote (US timezones preferred).
Salary range: $140,000 - $175,000 per year. Must have 5+ years Python experience.
"""
job = client.chat.completions.create(
model="gpt-4o-mini",
response_model=JobPosting,
messages=[{"role": "user", "content": f"Extract the job details from: {text}"}]
)
print(f"Title: {job.title}")
print(f"Company: {job.company}")
print(f"Location: {job.location}")
print(f"Salary: ${job.salary_min:,} - ${job.salary_max:,}")
print(f"Remote: {job.is_remote}")
The Optional[int] type tells instructor (and the model) that salary fields may be absent. When the source text does not mention a salary, these fields will be None instead of hallucinated values. Always use Optional for fields that may not appear in the input — without it, the model will invent plausible-sounding values rather than leaving the field empty.
Extracting Nested and List Objects
Real-world extraction often requires nested structures — for example, an invoice with multiple line items, or a resume with a list of work experiences. instructor handles nested Pydantic models and List types natively:
# nested_extraction.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import List
client = instructor.from_openai(OpenAI())
class LineItem(BaseModel):
description: str
quantity: int
unit_price: float
class Invoice(BaseModel):
vendor: str
invoice_number: str
items: List[LineItem]
total: float
invoice_text = """
Invoice #INV-2024-0891 from CloudHost Solutions
- 3x Server instances @ $45.00 each
- 1x SSL Certificate @ $12.00
- 2x Domain registrations @ $15.00 each
Total: $222.00
"""
result = client.chat.completions.create(
model="gpt-4o-mini",
response_model=Invoice,
messages=[{"role": "user", "content": f"Extract invoice data: {invoice_text}"}]
)
print(f"Vendor: {result.vendor}")
print(f"Invoice #: {result.invoice_number}")
for item in result.items:
print(f" {item.quantity}x {item.description} @ ${item.unit_price:.2f}")
print(f"Total: ${result.total:.2f}")
Nested models work because instructor converts the entire schema — including nested classes — into a JSON Schema definition that the model understands. The model fills in every field of every nested object, and Pydantic validates the whole structure recursively. If the items list is missing or a line item has an invalid type, instructor retries the extraction with the validation error as feedback.
Nested Pydantic models: recursion that actually works.
Adding Custom Validation Rules
Pydantic’s field_validator lets you add business logic on top of type checking. instructor automatically feeds validation errors back to the model, so the model gets a second (or third) chance to return values that satisfy your rules:
# custom_validation.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field, field_validator
from typing import List
client = instructor.from_openai(OpenAI())
class ProductReview(BaseModel):
product_name: str
rating: int = Field(description="Rating from 1 to 5")
pros: List[str] = Field(description="List of positive aspects, at least one")
cons: List[str] = Field(description="List of negative aspects, can be empty")
summary: str = Field(description="One-sentence summary under 150 characters")
@field_validator("rating")
@classmethod
def rating_in_range(cls, v: int) -> int:
if not 1 <= v <= 5:
raise ValueError(f"Rating must be between 1 and 5, got {v}")
return v
@field_validator("pros")
@classmethod
def at_least_one_pro(cls, v: List[str]) -> List[str]:
if not v:
raise ValueError("Must include at least one positive aspect")
return v
@field_validator("summary")
@classmethod
def summary_length(cls, v: str) -> str:
if len(v) > 150:
raise ValueError(f"Summary too long: {len(v)} chars (max 150)")
return v
text = """
The new Python IDE is pretty solid. Boot time is fast, autocomplete works well.
The memory usage is high and the plugin store is still sparse. Overall a decent
choice for Python development. I'd give it 4 out of 5.
"""
review = client.chat.completions.create(
model="gpt-4o-mini",
response_model=ProductReview,
messages=[{"role": "user", "content": f"Extract review details: {text}"}]
)
print(f"Product: {review.product_name}")
print(f"Rating: {review.rating}/5")
print(f"Pros: {review.pros}")
print(f"Cons: {review.cons}")
print(f"Summary: {review.summary}")
Output:
Product: Python IDE
Rating: 4/5
Pros: ['Fast boot time', 'Good autocomplete']
Cons: ['High memory usage', 'Sparse plugin store']
Summary: A solid Python IDE with fast performance but limited plugins and high memory usage.
When a validator raises ValueError, instructor captures the error message and sends it back to the model in a follow-up message: “Validation failed: Rating must be between 1 and 5, got 6. Please fix and try again.” The model then self-corrects. By default, instructor retries up to 3 times before raising an exception. You can configure this with max_retries=N on the completion call.
Configuring Retries and Modes
instructor supports several extraction modes depending on what your model supports. The default mode uses OpenAI’s tool calling, but you can switch to JSON mode or other strategies:
# retry_config.py
import instructor
from instructor import Mode
from openai import OpenAI
from pydantic import BaseModel
# Default: tool calling (most reliable for OpenAI models)
client_tools = instructor.from_openai(OpenAI())
# JSON mode: model returns raw JSON instead of a tool call
client_json = instructor.from_openai(OpenAI(), mode=Mode.JSON)
# MD_JSON mode: model wraps JSON in markdown fences (useful for some fine-tunes)
client_md = instructor.from_openai(OpenAI(), mode=Mode.MD_JSON)
class City(BaseModel):
name: str
country: str
population: int
# Control retries per-call
city = client_tools.chat.completions.create(
model="gpt-4o-mini",
response_model=City,
max_retries=5, # retry up to 5 times on validation failure
messages=[{"role": "user", "content": "Tell me about Tokyo"}]
)
print(f"{city.name}, {city.country}: pop {city.population:,}")
Output:
Tokyo, Japan: pop 13,960,000
For most OpenAI models, the default tool-calling mode is most reliable. Use Mode.JSON for models that support JSON mode but not tool calling — for example, some fine-tuned models or older GPT versions. The max_retries parameter controls how many times instructor will re-prompt the model when validation fails. For production pipelines where data quality matters more than cost, set this to 3-5.
Three retries and a Pydantic error. That’s the whole self-correction system.
Using instructor with Non-OpenAI Models
If you are using Anthropic’s Claude, Google Gemini, or a local model via Ollama, instructor has provider-specific patches. For OpenAI-compatible endpoints (like local LLMs with an OpenAI-compatible API), you can pass a custom base_url:
# multi_provider.py
import instructor
from anthropic import Anthropic
from pydantic import BaseModel
# Anthropic Claude -- uses a different client class
anthropic_client = instructor.from_anthropic(Anthropic())
class Sentiment(BaseModel):
label: str # "positive", "negative", or "neutral"
score: float # confidence from 0.0 to 1.0
reason: str # one-sentence explanation
result = anthropic_client.messages.create(
model="claude-3-haiku-20240307",
max_tokens=256,
response_model=Sentiment,
messages=[{
"role": "user",
"content": "This new Python library is fantastic, saves me hours every week!"
}]
)
print(f"Sentiment: {result.label} ({result.score:.0%})")
print(f"Reason: {result.reason}")
Output:
Sentiment: positive (96%)
Reason: The user expresses strong enthusiasm and quantifies time savings, indicating genuine satisfaction.
For local models via Ollama (which provides an OpenAI-compatible API on localhost:11434), create the client with a custom base URL:
# ollama_instructor.py
import instructor
from openai import OpenAI
from pydantic import BaseModel
# Ollama runs an OpenAI-compatible server locally
ollama_client = instructor.from_openai(
OpenAI(base_url="http://localhost:11434/v1", api_key="ollama"),
mode=instructor.Mode.JSON # use JSON mode for local models
)
class Summary(BaseModel):
headline: str
key_points: list[str]
# Works the same as OpenAI -- just a different backend
# summary = ollama_client.chat.completions.create(
# model="llama3.2",
# response_model=Summary,
# messages=[{"role": "user", "content": "Summarize Python's async/await model"}]
# )
print("Local model client ready -- uncomment to use with Ollama running")
Output:
Local model client ready -- uncomment to use with Ollama running
Here is a complete pipeline that reads job postings from a list of texts, extracts structured data, filters by criteria, and exports to CSV — the kind of task that comes up in recruiting tools, market research, and job aggregators:
Structured extraction at scale: parsing 50 job posts is just a for loop.
# job_extraction_pipeline.py
import instructor
import csv
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import Optional, List
client = instructor.from_openai(OpenAI())
class JobPosting(BaseModel):
title: str = Field(description="Job title exactly as written")
company: str
location: str = Field(description="City/country or 'Remote'")
salary_min: Optional[int] = Field(None, description="Min annual salary USD")
salary_max: Optional[int] = Field(None, description="Max annual salary USD")
required_years: Optional[int] = Field(None, description="Years of experience required")
technologies: List[str] = Field(description="List of technologies mentioned")
is_remote: bool
# Sample job postings to process
JOB_TEXTS = [
"""Senior Python Engineer at Nexaflow -- Remote-first.
$150k-$190k. 5+ years Python, FastAPI, PostgreSQL, AWS required.""",
"""Junior Data Scientist at BioMetrics Ltd (London, UK).
GBP 45,000-55,000. 0-2 years exp, pandas, scikit-learn, matplotlib.""",
"""Staff ML Engineer at Quantra -- San Francisco CA.
$220,000 - $280,000/yr. 8+ years, PyTorch, CUDA, distributed training.""",
]
def extract_jobs(texts: List[str]) -> List[JobPosting]:
"""Extract structured job data from raw posting texts."""
jobs = []
for i, text in enumerate(texts, 1):
job = client.chat.completions.create(
model="gpt-4o-mini",
response_model=JobPosting,
max_retries=3,
messages=[{"role": "user", "content": f"Extract job details:\n\n{text}"}]
)
jobs.append(job)
print(f"[{i}/{len(texts)}] Extracted: {job.title} at {job.company}")
return jobs
def filter_remote(jobs: List[JobPosting]) -> List[JobPosting]:
return [j for j in jobs if j.is_remote]
def export_csv(jobs: List[JobPosting], path: str) -> None:
with open(path, "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(["Title", "Company", "Location", "Salary Min", "Salary Max",
"Yrs Required", "Technologies", "Remote"])
for j in jobs:
writer.writerow([
j.title, j.company, j.location,
j.salary_min or "", j.salary_max or "",
j.required_years or "",
", ".join(j.technologies),
j.is_remote
])
if __name__ == "__main__":
print("Extracting job postings...")
jobs = extract_jobs(JOB_TEXTS)
remote_jobs = filter_remote(jobs)
print(f"\nTotal extracted: {len(jobs)}, Remote: {len(remote_jobs)}")
export_csv(jobs, "jobs_extracted.csv")
print("Saved to jobs_extracted.csv")
Output:
Extracting job postings...
[1/3] Extracted: Senior Python Engineer at Nexaflow
[2/3] Extracted: Junior Data Scientist at BioMetrics Ltd
[3/3] Extracted: Staff ML Engineer at Quantra
Total extracted: 3, Remote: 1
Saved to jobs_extracted.csv
This pipeline is easy to extend: add a database write step, connect it to a web scraper that feeds real job pages, or add more validation rules to the JobPosting model. The core pattern — extract once, validate automatically, retry on failure — stays the same regardless of the scale. You can process thousands of postings by replacing JOB_TEXTS with a generator that reads from a queue or database, keeping the extraction logic identical.
Frequently Asked Questions
Does instructor increase API costs because of retries?
Yes, each retry is an additional API call, so failed extractions cost more. In practice, with well-designed schemas and clear field descriptions, validation failures are rare — under 5% for most extraction tasks. The cost increase is usually worth the reliability gain. If cost is a concern, use max_retries=1 and handle exceptions in your code rather than retrying automatically.
Does instructor support streaming responses?
Yes. Use response_model=Iterable[YourModel] for streaming lists, or Partial[YourModel] for streaming partial updates to a single model. Streaming is useful for large extractions where you want to process results as they arrive rather than waiting for the full response. See the instructor documentation for the streaming API details.
What happens when the model cannot extract a field?
If the field is typed as Optional[X], the model will return None for missing information. If the field is required (non-Optional), the model will either hallucinate a value or fail validation, triggering a retry. For fields that may legitimately be absent in the source text, always use Optional with a None default. This is the most common mistake new users make.
Can I extract data from large documents?
Yes, but be aware of token limits. For documents larger than a few thousand words, split them into chunks and extract from each chunk separately. Use a List[YourModel] return type if a single document contains multiple items to extract (like a list of transactions in a bank statement). For very large documents, consider summarizing first with a regular completion call, then extracting from the summary.
How is this different from just prompting for JSON output?
Prompting for JSON works until it does not — the model adds markdown fences, writes a preamble sentence, or omits fields. instructor uses tool calling (not prompting) to enforce the schema, so the model cannot deviate from the structure. It also runs Pydantic validation on the result and retries if types or constraints are violated. The difference in reliability for production use is significant — JSON prompting is fine for experiments, but instructor is the right tool for pipelines where data quality matters.
Is my data sent to OpenAI when I use instructor?
instructor is a thin wrapper around the OpenAI SDK — your data goes to whatever API endpoint you configure, subject to that provider’s data policy. If you are processing sensitive data, use a self-hosted model via Ollama or another local inference server, and point instructor at your local endpoint with a custom base_url. The library itself does not send data anywhere — it only wraps the client you provide.
Conclusion
The instructor library solves one of the most persistent frustrations in LLM application development: getting the model to return data in the shape your code expects, every time. We covered patching the OpenAI client, defining Pydantic schemas with field descriptions, extracting nested and list objects, adding custom validation rules, configuring retries and modes, and using instructor with non-OpenAI providers. The job extraction pipeline demonstrated how these pieces combine into a production-ready pattern.
The next step is to extend the real-life example: add a web scraper to pull live job postings, or connect the extracted data to a database. With instructor handling the model-to-schema translation, you can focus entirely on the business logic of what to extract and what to do with it.
Full documentation and more examples are at python.useinstructor.com. The library’s GitHub has a large collection of real-world examples including classification, knowledge graph extraction, and citation-backed answers.
async def defines a coroutine function and await pauses execution until an asynchronous operation completes. This enables concurrent I/O operations without threading, using the asyncio event loop.
When should I use async/await instead of threading?
Use async/await for I/O-bound tasks like network requests and database queries with many concurrent connections. Use threading for CPU-bound tasks or libraries that do not support async.
How do I run multiple async tasks concurrently?
Use asyncio.gather(task1(), task2()) to run multiple coroutines concurrently. Use asyncio.create_task() to schedule without immediately waiting.
What does ‘coroutine was never awaited’ mean?
You called an async function without await. Async functions return coroutine objects that must be awaited. Add await before the call or use asyncio.run() from synchronous code.
Can I mix synchronous and asynchronous code?
Yes. Use asyncio.run() to call async from sync. Use loop.run_in_executor() to run blocking functions inside async code without blocking the event loop.
Twitter Bots can be super useful to help automate some of the interactions on social media in order to build and grow engagement but also automate some tasks. There has been many changes on the twitter developer account and sometimes it’s uncertain how to even create a tweet bot. This article will walk through step bey step on how to create a twitter bot with the latest Twitter API v2 and also provide some code you can copy and paste in your next project. We also end with how to create a more useful bot that can post some articles about python automatically.
In a nutshell, how a twitter bot works is that you will need to run your code for a twitter bot in your own compute that can be triggered from a Twitter webhook (not covered) which is called by twitter based on a given event, or by having your program run periodically to read and send tweets (covered in this article). Either way, there are some commonalities and in this article we will walk through how to read tweets, and then to send tweets which are from google news related to python!
Step 1: Sign up for Developer program
If you haven’t already you will need to either sign in or sign up for a twitter account through twitter.com. Make sure your twitter account has an email address allocated to it (if you’re not aware, you can create a twitter account with just your mobile phone number)
Next go to developer.twitter.com and sign up for the developer program (yes, you need to sign up for a second time). This enables you to create applications.
First you’ll need to answer some questions on purpose of the developer account. You can chose “Make a Bot”
Next you will need to agree to the terms and conditions, and then a verification email will be sent to your email address from your twitter account.
When you click on the email to verify your account, you can then enter your app name. This is an internal name and something that will make it easy for you to reference.
Once you click on keys, you will then be given a set of security token keys like below. Please copy them in a safe place as your python code will need to use them to access your specific bot. If you do lose your keys, or someone gets access to them for some reason, you can generate new keys from your developer.twitter.com console.
There are two keys which you will need to use:
API Key (think of this like a username)
API Key Secret (think of this like a password)
Bearer Token (used for read queries such as getting latest tweets)
There is also a third key, a Bearer Token, but this you can ignore. It is for certain types of requests
At the bottom of the screen you’ll see a “Skip to Dashboard”, when you click on that you’ll then see the overview of your API metrics.
Within this screen you can see the limits of the number of calls per month for example and how much you have already consumed.
Next, click on the project and we have to generate the access tokens. Currently with the previous keys you can only read tweets, you cannot create ones as yet.
After clicking on the project, chose the “keys and tokens” tab and at the bottom you can generate the “Access Tokens”. In this screen you can also re-generate the API Keys and Bearer Token you just created before in case your keys were compromised or you forgot them.
Just like before, generate the keys and copy them.
By now, you have 5 security toknes:
API Key – also known as the Consumer Key (think of this like a username)
API Key Secret – also known as the Consumer Secret (think of this like a password)
Bearer Token (used for read queries such as getting latest tweets)
Access Token (‘username’ to allow you to create tweets)
Access Token Secret (‘password’ to allow you to create tweets)
Step 2: Test your twitter API query
Now that you have the API keys, you can do some tests. If you are using a linux based machine you can use the curl command to do a query. Otherwise, you can use a site such as https://reqbin.com/curl to do an online curl request.
Here’s a simple example to get the most recent tweets. It uses the API https://api.twitter.com/2/tweets/search/recent which must include the query keyword which includes a range of parameter options (find out the list in the twitter query documentation).
curl --request GET 'https://api.twitter.com/2/tweets/search/recent?query=from:pythonhowtocode' --header 'Authorization: Bearer <your bearer token from step 1>'
The output is as follows:
{
"data": [{
"id": "1523251860110405633",
"text": "See our latest article on THE complete beginner guide on creating a #discord #bot in #python \n\nEasily add this to your #100DaysOfCode #100daysofcodechallenge #100daysofpython \n\nhttps://t.co/4WKvDVh1g9"
}],
"meta": {
"newest_id": "1523251860110405633",
"oldest_id": "1523251860110405633",
"result_count": 1
}
}
Here’s a much more complex example. This includes the following parameters:
%23 – which is the escape characters for # and searches for hashtags. Below example is hashtag #python (case insensitive)
%20 – this is an escape character for a space and separates different filters with an AND operation
-is:retweet – this excludes retweets. The ‘-‘ sign preceding the is negates the actual filter
-is:reply – this excludes replies. The ‘-‘ sign preceding the is negates the actual filter
max_results=20 – an integer that defines the maximum number of return results and in this case 20 results
expansions=author_id – this makes sure to include the username internal twitter id and also the actual username under an includes section at the bottom of the returned JSON
tweet.fields=public_metrics,created_at – returns the interaction metrics such as number of likes, number of retweets, etc as well as the time (in GMT timezone) when the tweet was created
user.fields=created_at,location – this returns when the user account was created and the user self-reported location in their profile.
curl --request GET 'https://api.twitter.com/2/tweets/search/recent?query=%23python%20-is:retweet%20-is:reply&max_results=20&expansions=author_id&tweet.fields=public_metrics,created_at&user.fields=created_at,location' --header 'Authorization: Bearer <Your Bearer Token from Step 1>'
Result of this looks like the following – notice that the username details is in the includes section below where you can link the tweet with the username with the author_id field.
Building on top of the tests conducted on Step 2, it is a simple extra step in order to convert this to python code using the requests module which we’ll show first and after show a simpler way with the library tweepy. You can simply use the library to convert the curl command into a bit of python code. Here’s a structured version of this code where the logic is encapsulated in a class.
import requests, json
from urllib.parse import quote
from pprint import pprint
class TwitterBot():
URL_SEARCH_RECENT = 'https://api.twitter.com/2/tweets/search/recent'
def __init__(self, bearer_key):
self.bearer_key = bearer_key
def search_recent(self, query, include_retweets=False, include_replies=False):
url = self.URL_SEARCH_RECENT + "?query=" + quote(query)
if not include_retweets: url += quote(' ')+'-is:retweet'
if not include_replies: url += quote(' ')+'-is:reply'
url += '&max_results=20&expansions=author_id&tweet.fields=public_metrics,created_at&user.fields=created_at,location'
headers = {'Authorization': 'Bearer ' + self.bearer_key }
r = requests.get(url, headers = headers)
r.encoding = r.apparent_encoding. #Ensure to use UTF-8 if unicode characters
return json.loads(r.text)
#create an instance and pass in your Bearer Token
t = TwitterBot('<Insert your Bearer Token from Step 1>')
pprint( t.search_recent( '#python') )
The above code is fairly straightforward and does the following:
TwitterBot class – this class encapsulates the logic to send the API requests
TwitterBot.search_recent – this method takes in the query string, then escapes any special characters, then calls the requests.get() to call the https://api.twitter.com/2/tweets/search/recent API call
pprint() – this simply prints the output in a more readable format
This is the output:
However, there is a simpler way which is to use tweepy.
pip install tweepy
Next you can use the tweepy module to search recent tweets:
import tweepy
client = tweepy.Client(bearer_token='<insert your token here from previous step>')
query = '#python -is:retweet -is:reply' #exclude retweets and replies with '-'
tweets = client.search_recent_tweets( query=query,
tweet_fields=['public_metrics', 'context_annotations', 'created_at'],
user_fields=['username','created_at','location'],
expansions=['entities.mentions.username','author_id'],
max_results=10)
#The details of the users is in the 'includes' list
user_data = {}
for raw_user in tweets.includes['users']:
user_data[ raw_user.id ] = raw_user
for index, tweet in enumerate(tweets.data):
print(f"[{index}]::@{user_data[tweet.author_id]['username']}::{tweet.created_at}::{tweet.text.strip()}\n")
print("------------------------------------------------------------------------------")
Output as follows:
Please note, that after calling the API a few times your number of tweets consumed will have increased and may have hit the limit. You can always visit the dashboard at https://developer.twitter.com/en/portal/dashboard to see how many requests have been consumed. Notice, that this does not count the number of actual API calls but the actual number of tweets. So it can get consumed pretty quickly.
Step 4: Sending out a tweet
So far we’ve only been reading tweets. In order to send a tweet you can use the create_tweet() function of tweepy.
client = tweepy.Client( consumer_key= "<API key from above - see step 1>",
consumer_secret= "<API Key secret - see step 1>",
access_token= "<Access Token - see step 1>",
access_token_secret= "<Access Token Secret - see step 1>")
# Replace the text with whatever you want to Tweet about
response = client.create_tweet(text='A little girl walks into a pet shop and asks for a bunny. The worker says” the fluffy white one or the fluffy brown one”? The girl then says, I don’t think my python really cares.')
print(response)
Output from Console:
Output from Twitter:
How to Send Automated Tweets About the Latest News
To make this a bit more of a useful bot rather than simply tweet out static text, we’ll make it tweet about the latest things happened in the news about python.
In order to search for news information, you can use the python library pygooglenews
pip install pygooglenews
The library searches Google news RSS feed and was developed by Artem Bugara. You can see the full article of he developed the Google News library. You can put in a keyword and also time horizon to make it work. Here’s an example to find the latest python articles in last 24 hours.
from pygooglenews import GoogleNews
gn = GoogleNews()
search = gn.search('python programming', when = '12h')
for article in search['entries']:
print(article.title)
print(article.published)
print(article.source.title)
print('-'*80) #string multiplier - show '-' 80 times
Here’s the output:
So, the idea would be to show a random article on the twitter bot which is related to python programming. The gn.search() functions returns a list of all the articles under the entries dictionary item which has a list of those articles. We will simply pick a random one and construct the tweet with the article title and the link to the article.
import tweepy
from pygooglenews import GoogleNews
from random import randint
client = tweepy.Client( consumer_key= "<your consumer/API key - see step 1>",
consumer_secret= "<your consumer/API secret - see step 1>",
access_token= "<your access token key - see step 1>",
access_token_secret= "<your access token secret - see step 1>")
gn = GoogleNews()
search = gn.search('python programming', when = '24h')
#Find random article in last 24 hours using randint between index 0 and the last index
article = search['entries'][ randint( 0, len( search['entries'])-1 ) ]
#construct the tweet text
tweet_text = f"In python news: {article.title}. See full article: {article.link}. #python #pythonprogramming"
#Fire off the tweet!
response = client.create_tweet( tweet_text )
print(response)
Output from the console on the return result:
And, most importantly, here’s the tweet from our @pythonhowtocode! Twitter automatically pulled the article image
This has currently been scheduled as a daily background job!
You ask an LLM to extract a user’s name, age, and email from a paragraph of text. Sometimes it returns clean JSON. Sometimes it returns JSON wrapped in markdown fences. Sometimes it returns a paragraph explaining why it extracted those fields. If you have ever built a pipeline that breaks because the model decided today was a good day to add “Sure! Here is the extracted data:” before the JSON, you already understand why instructor exists.
The instructor library patches the OpenAI client (and any OpenAI-compatible API) to force the model to return a fully validated Pydantic model — every time. When validation fails, it retries automatically. You define exactly what fields you need, with their types and constraints, and instructor handles the conversation with the model until the output matches your schema. You need Python 3.9+, an OpenAI API key (or compatible endpoint), and pip install instructor.
This article walks through everything you need to get structured LLM outputs in production: installing and patching the client, defining Pydantic schemas, extracting nested objects, handling lists, using validation hooks, working with non-OpenAI models via LiteLLM, and building a real extraction pipeline. By the end you will have a reusable pattern for reliable structured data from any LLM.
Structured LLM Output: Quick Example
The fastest way to see instructor in action is to extract a structured object from a single sentence. Install the library and try this:
# quick_instructor.py
import instructor
from openai import OpenAI
from pydantic import BaseModel
client = instructor.from_openai(OpenAI())
class Person(BaseModel):
name: str
age: int
city: str
person = client.chat.completions.create(
model="gpt-4o-mini",
response_model=Person,
messages=[{"role": "user", "content": "Alice is 32 years old and lives in Melbourne."}]
)
print(person.name) # Alice
print(person.age) # 32
print(person.city) # Melbourne
print(type(person)) # <class '__main__.Person'>
Output:
Alice
32
Melbourne
<class '__main__.Person'>
The key line is instructor.from_openai(OpenAI()) — this patches the standard OpenAI client. After that, you pass response_model=Person to any chat.completions.create call, and instructor automatically: sends the Pydantic schema to the model as a tool definition, parses the model’s tool-call response, validates it against your schema, and retries if validation fails. The return value is a fully typed Pydantic object, not a string or dict.
That example covers the simplest case. The sections below show how to handle nested models, lists, validation rules, retry configuration, and real-world pipelines.
response_model= and the chaos becomes a schema.
What Is instructor and Why Use It?
When you call an LLM without constraints, it returns free-form text. Parsing that text into structured data is fragile — you write regex, JSON parsers, and fallback handlers that break every time the model changes its wording. instructor solves this by using OpenAI’s function/tool calling feature under the hood: it converts your Pydantic model into a JSON Schema tool definition, forces the model to call that tool, and validates the returned arguments against your schema.
The result is LLM output that behaves like a typed function return value instead of a string you have to parse. If the model returns a field with the wrong type (for example, age as a string “thirty-two” instead of an integer), instructor sends the validation error back to the model and asks it to try again — up to a configurable number of retries.
Approach
Reliability
Type Safety
Auto-Retry
Parse raw LLM text
Fragile
None
Manual
Parse JSON from prompt
Moderate
Manual
Manual
OpenAI function calling
Good
Partial
None
instructor + Pydantic
High
Full
Built-in
The library supports multiple backends: instructor.from_openai, instructor.from_anthropic, instructor.from_gemini, and any OpenAI-compatible endpoint via base_url. This makes it the same interface regardless of which model you use.
Installation and Setup
Install instructor and the OpenAI SDK together. If you are using a different provider, you may also need their SDK:
# Terminal
pip install instructor openai pydantic
Set your API key as an environment variable so it never appears in your code:
# setup_env.py -- run once, or add to your shell profile
import os
# In practice, set this in your shell:
# export OPENAI_API_KEY="sk-..."
print("OPENAI_API_KEY set:", bool(os.environ.get("OPENAI_API_KEY")))
Output:
OPENAI_API_KEY set: True
Patch the client once at startup and reuse it for all calls. Creating a new patched client for every request is wasteful:
# client_setup.py
import instructor
from openai import OpenAI
# Patch once at startup
client = instructor.from_openai(OpenAI()) # reads OPENAI_API_KEY from env
# The client now has response_model support on all completion calls
print(type(client)) # <class 'instructor.client.Instructor'>
Output:
<class 'instructor.client.Instructor'>
One patch. Every completion call now speaks schema.
Defining Pydantic Schemas for Extraction
Your Pydantic model defines exactly what fields the LLM must return. Field descriptions improve accuracy significantly — the model uses them as instructions for what to put in each field. Use Field(description=...) to guide the extraction:
# schema_example.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import Optional
client = instructor.from_openai(OpenAI())
class JobPosting(BaseModel):
title: str = Field(description="The exact job title as written in the posting")
company: str = Field(description="Company name offering the position")
location: str = Field(description="City and country, or 'Remote'")
salary_min: Optional[int] = Field(None, description="Minimum annual salary in USD if mentioned")
salary_max: Optional[int] = Field(None, description="Maximum annual salary in USD if mentioned")
is_remote: bool = Field(description="True if the role allows remote work")
text = """
Senior Python Developer at DataFlow Inc. -- Remote (US timezones preferred).
Salary range: $140,000 - $175,000 per year. Must have 5+ years Python experience.
"""
job = client.chat.completions.create(
model="gpt-4o-mini",
response_model=JobPosting,
messages=[{"role": "user", "content": f"Extract the job details from: {text}"}]
)
print(f"Title: {job.title}")
print(f"Company: {job.company}")
print(f"Location: {job.location}")
print(f"Salary: ${job.salary_min:,} - ${job.salary_max:,}")
print(f"Remote: {job.is_remote}")
The Optional[int] type tells instructor (and the model) that salary fields may be absent. When the source text does not mention a salary, these fields will be None instead of hallucinated values. Always use Optional for fields that may not appear in the input — without it, the model will invent plausible-sounding values rather than leaving the field empty.
Extracting Nested and List Objects
Real-world extraction often requires nested structures — for example, an invoice with multiple line items, or a resume with a list of work experiences. instructor handles nested Pydantic models and List types natively:
# nested_extraction.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import List
client = instructor.from_openai(OpenAI())
class LineItem(BaseModel):
description: str
quantity: int
unit_price: float
class Invoice(BaseModel):
vendor: str
invoice_number: str
items: List[LineItem]
total: float
invoice_text = """
Invoice #INV-2024-0891 from CloudHost Solutions
- 3x Server instances @ $45.00 each
- 1x SSL Certificate @ $12.00
- 2x Domain registrations @ $15.00 each
Total: $222.00
"""
result = client.chat.completions.create(
model="gpt-4o-mini",
response_model=Invoice,
messages=[{"role": "user", "content": f"Extract invoice data: {invoice_text}"}]
)
print(f"Vendor: {result.vendor}")
print(f"Invoice #: {result.invoice_number}")
for item in result.items:
print(f" {item.quantity}x {item.description} @ ${item.unit_price:.2f}")
print(f"Total: ${result.total:.2f}")
Nested models work because instructor converts the entire schema — including nested classes — into a JSON Schema definition that the model understands. The model fills in every field of every nested object, and Pydantic validates the whole structure recursively. If the items list is missing or a line item has an invalid type, instructor retries the extraction with the validation error as feedback.
Nested Pydantic models: recursion that actually works.
Adding Custom Validation Rules
Pydantic’s field_validator lets you add business logic on top of type checking. instructor automatically feeds validation errors back to the model, so the model gets a second (or third) chance to return values that satisfy your rules:
# custom_validation.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field, field_validator
from typing import List
client = instructor.from_openai(OpenAI())
class ProductReview(BaseModel):
product_name: str
rating: int = Field(description="Rating from 1 to 5")
pros: List[str] = Field(description="List of positive aspects, at least one")
cons: List[str] = Field(description="List of negative aspects, can be empty")
summary: str = Field(description="One-sentence summary under 150 characters")
@field_validator("rating")
@classmethod
def rating_in_range(cls, v: int) -> int:
if not 1 <= v <= 5:
raise ValueError(f"Rating must be between 1 and 5, got {v}")
return v
@field_validator("pros")
@classmethod
def at_least_one_pro(cls, v: List[str]) -> List[str]:
if not v:
raise ValueError("Must include at least one positive aspect")
return v
@field_validator("summary")
@classmethod
def summary_length(cls, v: str) -> str:
if len(v) > 150:
raise ValueError(f"Summary too long: {len(v)} chars (max 150)")
return v
text = """
The new Python IDE is pretty solid. Boot time is fast, autocomplete works well.
The memory usage is high and the plugin store is still sparse. Overall a decent
choice for Python development. I'd give it 4 out of 5.
"""
review = client.chat.completions.create(
model="gpt-4o-mini",
response_model=ProductReview,
messages=[{"role": "user", "content": f"Extract review details: {text}"}]
)
print(f"Product: {review.product_name}")
print(f"Rating: {review.rating}/5")
print(f"Pros: {review.pros}")
print(f"Cons: {review.cons}")
print(f"Summary: {review.summary}")
Output:
Product: Python IDE
Rating: 4/5
Pros: ['Fast boot time', 'Good autocomplete']
Cons: ['High memory usage', 'Sparse plugin store']
Summary: A solid Python IDE with fast performance but limited plugins and high memory usage.
When a validator raises ValueError, instructor captures the error message and sends it back to the model in a follow-up message: “Validation failed: Rating must be between 1 and 5, got 6. Please fix and try again.” The model then self-corrects. By default, instructor retries up to 3 times before raising an exception. You can configure this with max_retries=N on the completion call.
Configuring Retries and Modes
instructor supports several extraction modes depending on what your model supports. The default mode uses OpenAI’s tool calling, but you can switch to JSON mode or other strategies:
# retry_config.py
import instructor
from instructor import Mode
from openai import OpenAI
from pydantic import BaseModel
# Default: tool calling (most reliable for OpenAI models)
client_tools = instructor.from_openai(OpenAI())
# JSON mode: model returns raw JSON instead of a tool call
client_json = instructor.from_openai(OpenAI(), mode=Mode.JSON)
# MD_JSON mode: model wraps JSON in markdown fences (useful for some fine-tunes)
client_md = instructor.from_openai(OpenAI(), mode=Mode.MD_JSON)
class City(BaseModel):
name: str
country: str
population: int
# Control retries per-call
city = client_tools.chat.completions.create(
model="gpt-4o-mini",
response_model=City,
max_retries=5, # retry up to 5 times on validation failure
messages=[{"role": "user", "content": "Tell me about Tokyo"}]
)
print(f"{city.name}, {city.country}: pop {city.population:,}")
Output:
Tokyo, Japan: pop 13,960,000
For most OpenAI models, the default tool-calling mode is most reliable. Use Mode.JSON for models that support JSON mode but not tool calling — for example, some fine-tuned models or older GPT versions. The max_retries parameter controls how many times instructor will re-prompt the model when validation fails. For production pipelines where data quality matters more than cost, set this to 3-5.
Three retries and a Pydantic error. That’s the whole self-correction system.
Using instructor with Non-OpenAI Models
If you are using Anthropic’s Claude, Google Gemini, or a local model via Ollama, instructor has provider-specific patches. For OpenAI-compatible endpoints (like local LLMs with an OpenAI-compatible API), you can pass a custom base_url:
# multi_provider.py
import instructor
from anthropic import Anthropic
from pydantic import BaseModel
# Anthropic Claude -- uses a different client class
anthropic_client = instructor.from_anthropic(Anthropic())
class Sentiment(BaseModel):
label: str # "positive", "negative", or "neutral"
score: float # confidence from 0.0 to 1.0
reason: str # one-sentence explanation
result = anthropic_client.messages.create(
model="claude-3-haiku-20240307",
max_tokens=256,
response_model=Sentiment,
messages=[{
"role": "user",
"content": "This new Python library is fantastic, saves me hours every week!"
}]
)
print(f"Sentiment: {result.label} ({result.score:.0%})")
print(f"Reason: {result.reason}")
Output:
Sentiment: positive (96%)
Reason: The user expresses strong enthusiasm and quantifies time savings, indicating genuine satisfaction.
For local models via Ollama (which provides an OpenAI-compatible API on localhost:11434), create the client with a custom base URL:
# ollama_instructor.py
import instructor
from openai import OpenAI
from pydantic import BaseModel
# Ollama runs an OpenAI-compatible server locally
ollama_client = instructor.from_openai(
OpenAI(base_url="http://localhost:11434/v1", api_key="ollama"),
mode=instructor.Mode.JSON # use JSON mode for local models
)
class Summary(BaseModel):
headline: str
key_points: list[str]
# Works the same as OpenAI -- just a different backend
# summary = ollama_client.chat.completions.create(
# model="llama3.2",
# response_model=Summary,
# messages=[{"role": "user", "content": "Summarize Python's async/await model"}]
# )
print("Local model client ready -- uncomment to use with Ollama running")
Output:
Local model client ready -- uncomment to use with Ollama running
Here is a complete pipeline that reads job postings from a list of texts, extracts structured data, filters by criteria, and exports to CSV — the kind of task that comes up in recruiting tools, market research, and job aggregators:
Structured extraction at scale: parsing 50 job posts is just a for loop.
# job_extraction_pipeline.py
import instructor
import csv
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import Optional, List
client = instructor.from_openai(OpenAI())
class JobPosting(BaseModel):
title: str = Field(description="Job title exactly as written")
company: str
location: str = Field(description="City/country or 'Remote'")
salary_min: Optional[int] = Field(None, description="Min annual salary USD")
salary_max: Optional[int] = Field(None, description="Max annual salary USD")
required_years: Optional[int] = Field(None, description="Years of experience required")
technologies: List[str] = Field(description="List of technologies mentioned")
is_remote: bool
# Sample job postings to process
JOB_TEXTS = [
"""Senior Python Engineer at Nexaflow -- Remote-first.
$150k-$190k. 5+ years Python, FastAPI, PostgreSQL, AWS required.""",
"""Junior Data Scientist at BioMetrics Ltd (London, UK).
GBP 45,000-55,000. 0-2 years exp, pandas, scikit-learn, matplotlib.""",
"""Staff ML Engineer at Quantra -- San Francisco CA.
$220,000 - $280,000/yr. 8+ years, PyTorch, CUDA, distributed training.""",
]
def extract_jobs(texts: List[str]) -> List[JobPosting]:
"""Extract structured job data from raw posting texts."""
jobs = []
for i, text in enumerate(texts, 1):
job = client.chat.completions.create(
model="gpt-4o-mini",
response_model=JobPosting,
max_retries=3,
messages=[{"role": "user", "content": f"Extract job details:\n\n{text}"}]
)
jobs.append(job)
print(f"[{i}/{len(texts)}] Extracted: {job.title} at {job.company}")
return jobs
def filter_remote(jobs: List[JobPosting]) -> List[JobPosting]:
return [j for j in jobs if j.is_remote]
def export_csv(jobs: List[JobPosting], path: str) -> None:
with open(path, "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(["Title", "Company", "Location", "Salary Min", "Salary Max",
"Yrs Required", "Technologies", "Remote"])
for j in jobs:
writer.writerow([
j.title, j.company, j.location,
j.salary_min or "", j.salary_max or "",
j.required_years or "",
", ".join(j.technologies),
j.is_remote
])
if __name__ == "__main__":
print("Extracting job postings...")
jobs = extract_jobs(JOB_TEXTS)
remote_jobs = filter_remote(jobs)
print(f"\nTotal extracted: {len(jobs)}, Remote: {len(remote_jobs)}")
export_csv(jobs, "jobs_extracted.csv")
print("Saved to jobs_extracted.csv")
Output:
Extracting job postings...
[1/3] Extracted: Senior Python Engineer at Nexaflow
[2/3] Extracted: Junior Data Scientist at BioMetrics Ltd
[3/3] Extracted: Staff ML Engineer at Quantra
Total extracted: 3, Remote: 1
Saved to jobs_extracted.csv
This pipeline is easy to extend: add a database write step, connect it to a web scraper that feeds real job pages, or add more validation rules to the JobPosting model. The core pattern — extract once, validate automatically, retry on failure — stays the same regardless of the scale. You can process thousands of postings by replacing JOB_TEXTS with a generator that reads from a queue or database, keeping the extraction logic identical.
Frequently Asked Questions
Does instructor increase API costs because of retries?
Yes, each retry is an additional API call, so failed extractions cost more. In practice, with well-designed schemas and clear field descriptions, validation failures are rare — under 5% for most extraction tasks. The cost increase is usually worth the reliability gain. If cost is a concern, use max_retries=1 and handle exceptions in your code rather than retrying automatically.
Does instructor support streaming responses?
Yes. Use response_model=Iterable[YourModel] for streaming lists, or Partial[YourModel] for streaming partial updates to a single model. Streaming is useful for large extractions where you want to process results as they arrive rather than waiting for the full response. See the instructor documentation for the streaming API details.
What happens when the model cannot extract a field?
If the field is typed as Optional[X], the model will return None for missing information. If the field is required (non-Optional), the model will either hallucinate a value or fail validation, triggering a retry. For fields that may legitimately be absent in the source text, always use Optional with a None default. This is the most common mistake new users make.
Can I extract data from large documents?
Yes, but be aware of token limits. For documents larger than a few thousand words, split them into chunks and extract from each chunk separately. Use a List[YourModel] return type if a single document contains multiple items to extract (like a list of transactions in a bank statement). For very large documents, consider summarizing first with a regular completion call, then extracting from the summary.
How is this different from just prompting for JSON output?
Prompting for JSON works until it does not — the model adds markdown fences, writes a preamble sentence, or omits fields. instructor uses tool calling (not prompting) to enforce the schema, so the model cannot deviate from the structure. It also runs Pydantic validation on the result and retries if types or constraints are violated. The difference in reliability for production use is significant — JSON prompting is fine for experiments, but instructor is the right tool for pipelines where data quality matters.
Is my data sent to OpenAI when I use instructor?
instructor is a thin wrapper around the OpenAI SDK — your data goes to whatever API endpoint you configure, subject to that provider’s data policy. If you are processing sensitive data, use a self-hosted model via Ollama or another local inference server, and point instructor at your local endpoint with a custom base_url. The library itself does not send data anywhere — it only wraps the client you provide.
Conclusion
The instructor library solves one of the most persistent frustrations in LLM application development: getting the model to return data in the shape your code expects, every time. We covered patching the OpenAI client, defining Pydantic schemas with field descriptions, extracting nested and list objects, adding custom validation rules, configuring retries and modes, and using instructor with non-OpenAI providers. The job extraction pipeline demonstrated how these pieces combine into a production-ready pattern.
The next step is to extend the real-life example: add a web scraper to pull live job postings, or connect the extracted data to a database. With instructor handling the model-to-schema translation, you can focus entirely on the business logic of what to extract and what to do with it.
Full documentation and more examples are at python.useinstructor.com. The library’s GitHub has a large collection of real-world examples including classification, knowledge graph extraction, and citation-backed answers.
The Twitter API enforces strict rate limits. Instead of crashing when you hit one, implement exponential backoff to retry gracefully. Wrap your API calls in a retry function that doubles the wait time after each failed attempt, starting from 1 second up to a maximum of 64 seconds. This keeps your bot running reliably without getting your credentials revoked.
Store your API credentials in environment variables or a .env file, never in your source code. If you accidentally push hardcoded keys to a public GitHub repo, bots will find and abuse them within minutes. Use the python-dotenv library to load credentials from a .env file that you add to your .gitignore.
# secure_credentials.py
import os
from dotenv import load_dotenv
load_dotenv()
BEARER_TOKEN = os.getenv("TWITTER_BEARER_TOKEN")
API_KEY = os.getenv("TWITTER_API_KEY")
API_SECRET = os.getenv("TWITTER_API_SECRET")
if not BEARER_TOKEN:
raise ValueError("TWITTER_BEARER_TOKEN not set in .env file")
3. Add Logging Instead of Print Statements
Replace print() calls with Python’s built-in logging module. Logging gives you timestamps, severity levels, and the ability to write to files — essential for debugging a bot that runs unattended. When your bot tweets something unexpected at 3 AM, logs are the only way to figure out what happened.
2026-03-26 10:15:30 [INFO] Bot started successfully
2026-03-26 10:15:31 [WARNING] Approaching rate limit: 14/15 requests used
2026-03-26 10:15:32 [ERROR] Failed to post tweet: 403 Forbidden
4. Track Posted Content to Avoid Duplicates
Bots that post the same content repeatedly get flagged and suspended. Keep a simple record of what you have already tweeted using a JSON file or SQLite database. Before posting, check if the content has been posted before. This is especially important for news bots that might encounter the same story from multiple sources.
5. Use a Scheduler for Consistent Posting
Instead of running your bot in a loop with time.sleep(), use a proper scheduler like schedule or APScheduler. Schedulers handle timing more reliably, support cron-like expressions, and make it easy to run different tasks at different intervals. For production bots, consider using system-level scheduling with cron (Linux) or Task Scheduler (Windows).
Frequently Asked Questions
Can I still build a Twitter bot with the API?
Yes, but access has changed. The free tier of the X (formerly Twitter) API v2 allows basic posting. For reading tweets or higher volume, you need a paid plan. Check current pricing at developer.x.com.
What Python library should I use for the Twitter/X API?
Use tweepy for the most mature Python wrapper with v2 API support. It handles OAuth 2.0 authentication, rate limiting, and provides clean methods for posting, searching, and streaming.
How do I authenticate with the Twitter API v2?
Use OAuth 2.0 Bearer Token for read-only access or OAuth 1.0a for posting. Generate credentials in the X Developer Portal, then pass them to tweepy.Client().
What are the rate limits for the Twitter API?
Rate limits vary by endpoint and plan. The free tier allows 1,500 tweets per month. Always implement rate limit handling with tweepy’s wait_on_rate_limit=True.
What can a Twitter bot do?
Bots can auto-post content, reply to mentions, retweet by keyword, track hashtags, analyze sentiment, and provide automated responses. Always follow the X API terms of service.
For most serious applications, you will often have to have persistent storage (storage that still exists after your applications stops running) of some sort. For new developers, it can be quite daunting to decide which option to go for. Is a simple flat file enough? When should you use something like a database? Which database should you use? There are so many options that are available it becomes quite daunting to decide which way to go for.
This is a starting guide to provide an overview of some of the many data storage options that are available for you and how you can go about deciding. One thing to keep in mind is that if you are developing an application which is either planned or has a possibility to scale over time, your underlying database might also grow overtime. It may be quick and easy to implement a file as storage, but as your data grows it might be better to use a relational database but it will take a little bit more effort. Let’s look at this a bit deeper
What are the possible ways to store data?
There are many methods of persistent storage that you can use (persistent storage means that after your program is finished running your data is not lost). The typical ways you can do this is either by using a file which you save data to, or by using the python pickle mechanism. Firstly I will explain what some of the persistent storage options are:
File: This is where you store the data in a text based file in format such as CSV (comma separated values), JSON, and others
Python Pickle: A python pickle is a mechanism where you can save a data structure directly to a file, and then you can retrieve the data directly from the file next time you run your program. You can do this with a library called “pickle”
Config files: config files are similar to File and Python Pickle in that the data is stored in a file format but is intended to be directly edited by a user
Database SQLite: this is a database where you can run queries to search for data, but the data is stored in a file
Database Postgres (or other SQL based database): this is a database service where there’s another program that you run to manage the database, and you call functions (or SQL queries) on the database service to get the data back in an efficient manner. SQL based databases are great for structured data – e.g. table-like/excel-like data. You would search for data by category fields as an example
Key-value database (e.g redis is one of the most famous): A key-value database is exactly that, it contains a database where you search by a key, and then it returns a value. This value can be a single value or it can be a set of fields that are associated with that value. A common use of a key-value database is for hash-based data. Meaning that you have a specific key that you want to search for, and then you get all the related fields associated with that key – much like a dictionary in python, but the benefit being its in a persistent storage
Graph Database (e.g. Neo4J): A graph database stores data which is built to navigate relationships. This is something that is rather cumbersome to do in a relational database where you need to have many intermediary tables but becomes trivial with GraphQL language
Text Search (e.g. Elastic Search): A purpose built database for text search which is extremely fast when searching for strings or long text
Time series database (e.g. influx): For IoT data where each record is stored with a timestamp key and you need to do queries in time blocks, time series databases are ideal. You can do common operations such as to aggregate, search, slice data through specific query operations
NOSQL document database (e.g. mongodb, couchdb): this is a database that also runs as a separate service but is specifically for “unstructured data” (non-table like data) such as text, images where you search for records in a free form way such as by text strings.
There is no one persistent storage mechanism that fits all, it really depends on your purpose (or “use case”) to determine which database works best for you as there are pros and cons for each.
Optional. You can create a config file before hand
Yes – you can use any text based editor
Small
Slow
Slow
No – manual
Database SQLite
None – database created automatically
No – only in python
Small-Med
Slow-Med
Slow-Med
No – manual
Relational SQL Database
Separate installation of server
Through the SQL console or other SQL clients
Large
Fast
Fast
Yes, require extra setup
NoSQL Column Database
Separate installation of server
Yes, through external client
Very large
Very fast
Very fast
Yes, inbuilt
Key-Value database
Separate installation of server
Yes, through external client
Very large
Very fast
Fast-Very Fast
Yes, require extra setup
Graph Database
Separate installation of serverSeparate installation of server
Yes, through external client
Large
Med
Med
Yes, require extra setup
Time Series Database
Separate installation of server
Yes, through external client
Very large
Very fast
Fast
Yes, require extra setup
Text Search Database
Separate installation of server
Yes, through external client
Very large
Very fast
Fast
Yes, require extra setup
NoSQL Documet DB
Separate installation of server
Yes, through external client
Very large
Very fast
Fast
Yes, require extra setup
A big disclaimer here, for some of the responses, the more accurate answer is “it depends”. For example, for redundancy for relational databases, some have it inbuilt such as Oracle RAC enterprise databases and for others you can set up redundancy where you could have an infrastructure solution. However, to provide a simpler guidance, I’ve made this a bit more prescriptive. If you would like to dive deeper, then please don’t rely purely on the table above! Look into the documentation of the particular database product you are considering or reach out to me and I’m happy to provide some advice.
Summary
There are in fact plenty of SaaS-based options for database or persistent storage that are popping up which is exciting. These newer SaaS options (for example, firebase, restdb.io, anvil.works etc) are great in that they save you time on the heavy lifting, but then there may be times you still want to manage your own database. This may be because you want to keep your data yourself, or simply because you want to save costs as you already have an environment either on your own laptop, or you’re paying a fixed price for a virtual machine. Hence, managing your own persistent storage may be more cost effective rather than paying for another SaaS. However, certainly don’t discount the SaaS options altogether, as they will at least help you with things like backups, security updates etc for you.
You ask an LLM to extract a user’s name, age, and email from a paragraph of text. Sometimes it returns clean JSON. Sometimes it returns JSON wrapped in markdown fences. Sometimes it returns a paragraph explaining why it extracted those fields. If you have ever built a pipeline that breaks because the model decided today was a good day to add “Sure! Here is the extracted data:” before the JSON, you already understand why instructor exists.
The instructor library patches the OpenAI client (and any OpenAI-compatible API) to force the model to return a fully validated Pydantic model — every time. When validation fails, it retries automatically. You define exactly what fields you need, with their types and constraints, and instructor handles the conversation with the model until the output matches your schema. You need Python 3.9+, an OpenAI API key (or compatible endpoint), and pip install instructor.
This article walks through everything you need to get structured LLM outputs in production: installing and patching the client, defining Pydantic schemas, extracting nested objects, handling lists, using validation hooks, working with non-OpenAI models via LiteLLM, and building a real extraction pipeline. By the end you will have a reusable pattern for reliable structured data from any LLM.
Structured LLM Output: Quick Example
The fastest way to see instructor in action is to extract a structured object from a single sentence. Install the library and try this:
# quick_instructor.py
import instructor
from openai import OpenAI
from pydantic import BaseModel
client = instructor.from_openai(OpenAI())
class Person(BaseModel):
name: str
age: int
city: str
person = client.chat.completions.create(
model="gpt-4o-mini",
response_model=Person,
messages=[{"role": "user", "content": "Alice is 32 years old and lives in Melbourne."}]
)
print(person.name) # Alice
print(person.age) # 32
print(person.city) # Melbourne
print(type(person)) # <class '__main__.Person'>
Output:
Alice
32
Melbourne
<class '__main__.Person'>
The key line is instructor.from_openai(OpenAI()) — this patches the standard OpenAI client. After that, you pass response_model=Person to any chat.completions.create call, and instructor automatically: sends the Pydantic schema to the model as a tool definition, parses the model’s tool-call response, validates it against your schema, and retries if validation fails. The return value is a fully typed Pydantic object, not a string or dict.
That example covers the simplest case. The sections below show how to handle nested models, lists, validation rules, retry configuration, and real-world pipelines.
response_model= and the chaos becomes a schema.
What Is instructor and Why Use It?
When you call an LLM without constraints, it returns free-form text. Parsing that text into structured data is fragile — you write regex, JSON parsers, and fallback handlers that break every time the model changes its wording. instructor solves this by using OpenAI’s function/tool calling feature under the hood: it converts your Pydantic model into a JSON Schema tool definition, forces the model to call that tool, and validates the returned arguments against your schema.
The result is LLM output that behaves like a typed function return value instead of a string you have to parse. If the model returns a field with the wrong type (for example, age as a string “thirty-two” instead of an integer), instructor sends the validation error back to the model and asks it to try again — up to a configurable number of retries.
Approach
Reliability
Type Safety
Auto-Retry
Parse raw LLM text
Fragile
None
Manual
Parse JSON from prompt
Moderate
Manual
Manual
OpenAI function calling
Good
Partial
None
instructor + Pydantic
High
Full
Built-in
The library supports multiple backends: instructor.from_openai, instructor.from_anthropic, instructor.from_gemini, and any OpenAI-compatible endpoint via base_url. This makes it the same interface regardless of which model you use.
Installation and Setup
Install instructor and the OpenAI SDK together. If you are using a different provider, you may also need their SDK:
# Terminal
pip install instructor openai pydantic
Set your API key as an environment variable so it never appears in your code:
# setup_env.py -- run once, or add to your shell profile
import os
# In practice, set this in your shell:
# export OPENAI_API_KEY="sk-..."
print("OPENAI_API_KEY set:", bool(os.environ.get("OPENAI_API_KEY")))
Output:
OPENAI_API_KEY set: True
Patch the client once at startup and reuse it for all calls. Creating a new patched client for every request is wasteful:
# client_setup.py
import instructor
from openai import OpenAI
# Patch once at startup
client = instructor.from_openai(OpenAI()) # reads OPENAI_API_KEY from env
# The client now has response_model support on all completion calls
print(type(client)) # <class 'instructor.client.Instructor'>
Output:
<class 'instructor.client.Instructor'>
One patch. Every completion call now speaks schema.
Defining Pydantic Schemas for Extraction
Your Pydantic model defines exactly what fields the LLM must return. Field descriptions improve accuracy significantly — the model uses them as instructions for what to put in each field. Use Field(description=...) to guide the extraction:
# schema_example.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import Optional
client = instructor.from_openai(OpenAI())
class JobPosting(BaseModel):
title: str = Field(description="The exact job title as written in the posting")
company: str = Field(description="Company name offering the position")
location: str = Field(description="City and country, or 'Remote'")
salary_min: Optional[int] = Field(None, description="Minimum annual salary in USD if mentioned")
salary_max: Optional[int] = Field(None, description="Maximum annual salary in USD if mentioned")
is_remote: bool = Field(description="True if the role allows remote work")
text = """
Senior Python Developer at DataFlow Inc. -- Remote (US timezones preferred).
Salary range: $140,000 - $175,000 per year. Must have 5+ years Python experience.
"""
job = client.chat.completions.create(
model="gpt-4o-mini",
response_model=JobPosting,
messages=[{"role": "user", "content": f"Extract the job details from: {text}"}]
)
print(f"Title: {job.title}")
print(f"Company: {job.company}")
print(f"Location: {job.location}")
print(f"Salary: ${job.salary_min:,} - ${job.salary_max:,}")
print(f"Remote: {job.is_remote}")
The Optional[int] type tells instructor (and the model) that salary fields may be absent. When the source text does not mention a salary, these fields will be None instead of hallucinated values. Always use Optional for fields that may not appear in the input — without it, the model will invent plausible-sounding values rather than leaving the field empty.
Extracting Nested and List Objects
Real-world extraction often requires nested structures — for example, an invoice with multiple line items, or a resume with a list of work experiences. instructor handles nested Pydantic models and List types natively:
# nested_extraction.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import List
client = instructor.from_openai(OpenAI())
class LineItem(BaseModel):
description: str
quantity: int
unit_price: float
class Invoice(BaseModel):
vendor: str
invoice_number: str
items: List[LineItem]
total: float
invoice_text = """
Invoice #INV-2024-0891 from CloudHost Solutions
- 3x Server instances @ $45.00 each
- 1x SSL Certificate @ $12.00
- 2x Domain registrations @ $15.00 each
Total: $222.00
"""
result = client.chat.completions.create(
model="gpt-4o-mini",
response_model=Invoice,
messages=[{"role": "user", "content": f"Extract invoice data: {invoice_text}"}]
)
print(f"Vendor: {result.vendor}")
print(f"Invoice #: {result.invoice_number}")
for item in result.items:
print(f" {item.quantity}x {item.description} @ ${item.unit_price:.2f}")
print(f"Total: ${result.total:.2f}")
Nested models work because instructor converts the entire schema — including nested classes — into a JSON Schema definition that the model understands. The model fills in every field of every nested object, and Pydantic validates the whole structure recursively. If the items list is missing or a line item has an invalid type, instructor retries the extraction with the validation error as feedback.
Nested Pydantic models: recursion that actually works.
Adding Custom Validation Rules
Pydantic’s field_validator lets you add business logic on top of type checking. instructor automatically feeds validation errors back to the model, so the model gets a second (or third) chance to return values that satisfy your rules:
# custom_validation.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field, field_validator
from typing import List
client = instructor.from_openai(OpenAI())
class ProductReview(BaseModel):
product_name: str
rating: int = Field(description="Rating from 1 to 5")
pros: List[str] = Field(description="List of positive aspects, at least one")
cons: List[str] = Field(description="List of negative aspects, can be empty")
summary: str = Field(description="One-sentence summary under 150 characters")
@field_validator("rating")
@classmethod
def rating_in_range(cls, v: int) -> int:
if not 1 <= v <= 5:
raise ValueError(f"Rating must be between 1 and 5, got {v}")
return v
@field_validator("pros")
@classmethod
def at_least_one_pro(cls, v: List[str]) -> List[str]:
if not v:
raise ValueError("Must include at least one positive aspect")
return v
@field_validator("summary")
@classmethod
def summary_length(cls, v: str) -> str:
if len(v) > 150:
raise ValueError(f"Summary too long: {len(v)} chars (max 150)")
return v
text = """
The new Python IDE is pretty solid. Boot time is fast, autocomplete works well.
The memory usage is high and the plugin store is still sparse. Overall a decent
choice for Python development. I'd give it 4 out of 5.
"""
review = client.chat.completions.create(
model="gpt-4o-mini",
response_model=ProductReview,
messages=[{"role": "user", "content": f"Extract review details: {text}"}]
)
print(f"Product: {review.product_name}")
print(f"Rating: {review.rating}/5")
print(f"Pros: {review.pros}")
print(f"Cons: {review.cons}")
print(f"Summary: {review.summary}")
Output:
Product: Python IDE
Rating: 4/5
Pros: ['Fast boot time', 'Good autocomplete']
Cons: ['High memory usage', 'Sparse plugin store']
Summary: A solid Python IDE with fast performance but limited plugins and high memory usage.
When a validator raises ValueError, instructor captures the error message and sends it back to the model in a follow-up message: “Validation failed: Rating must be between 1 and 5, got 6. Please fix and try again.” The model then self-corrects. By default, instructor retries up to 3 times before raising an exception. You can configure this with max_retries=N on the completion call.
Configuring Retries and Modes
instructor supports several extraction modes depending on what your model supports. The default mode uses OpenAI’s tool calling, but you can switch to JSON mode or other strategies:
# retry_config.py
import instructor
from instructor import Mode
from openai import OpenAI
from pydantic import BaseModel
# Default: tool calling (most reliable for OpenAI models)
client_tools = instructor.from_openai(OpenAI())
# JSON mode: model returns raw JSON instead of a tool call
client_json = instructor.from_openai(OpenAI(), mode=Mode.JSON)
# MD_JSON mode: model wraps JSON in markdown fences (useful for some fine-tunes)
client_md = instructor.from_openai(OpenAI(), mode=Mode.MD_JSON)
class City(BaseModel):
name: str
country: str
population: int
# Control retries per-call
city = client_tools.chat.completions.create(
model="gpt-4o-mini",
response_model=City,
max_retries=5, # retry up to 5 times on validation failure
messages=[{"role": "user", "content": "Tell me about Tokyo"}]
)
print(f"{city.name}, {city.country}: pop {city.population:,}")
Output:
Tokyo, Japan: pop 13,960,000
For most OpenAI models, the default tool-calling mode is most reliable. Use Mode.JSON for models that support JSON mode but not tool calling — for example, some fine-tuned models or older GPT versions. The max_retries parameter controls how many times instructor will re-prompt the model when validation fails. For production pipelines where data quality matters more than cost, set this to 3-5.
Three retries and a Pydantic error. That’s the whole self-correction system.
Using instructor with Non-OpenAI Models
If you are using Anthropic’s Claude, Google Gemini, or a local model via Ollama, instructor has provider-specific patches. For OpenAI-compatible endpoints (like local LLMs with an OpenAI-compatible API), you can pass a custom base_url:
# multi_provider.py
import instructor
from anthropic import Anthropic
from pydantic import BaseModel
# Anthropic Claude -- uses a different client class
anthropic_client = instructor.from_anthropic(Anthropic())
class Sentiment(BaseModel):
label: str # "positive", "negative", or "neutral"
score: float # confidence from 0.0 to 1.0
reason: str # one-sentence explanation
result = anthropic_client.messages.create(
model="claude-3-haiku-20240307",
max_tokens=256,
response_model=Sentiment,
messages=[{
"role": "user",
"content": "This new Python library is fantastic, saves me hours every week!"
}]
)
print(f"Sentiment: {result.label} ({result.score:.0%})")
print(f"Reason: {result.reason}")
Output:
Sentiment: positive (96%)
Reason: The user expresses strong enthusiasm and quantifies time savings, indicating genuine satisfaction.
For local models via Ollama (which provides an OpenAI-compatible API on localhost:11434), create the client with a custom base URL:
# ollama_instructor.py
import instructor
from openai import OpenAI
from pydantic import BaseModel
# Ollama runs an OpenAI-compatible server locally
ollama_client = instructor.from_openai(
OpenAI(base_url="http://localhost:11434/v1", api_key="ollama"),
mode=instructor.Mode.JSON # use JSON mode for local models
)
class Summary(BaseModel):
headline: str
key_points: list[str]
# Works the same as OpenAI -- just a different backend
# summary = ollama_client.chat.completions.create(
# model="llama3.2",
# response_model=Summary,
# messages=[{"role": "user", "content": "Summarize Python's async/await model"}]
# )
print("Local model client ready -- uncomment to use with Ollama running")
Output:
Local model client ready -- uncomment to use with Ollama running
Here is a complete pipeline that reads job postings from a list of texts, extracts structured data, filters by criteria, and exports to CSV — the kind of task that comes up in recruiting tools, market research, and job aggregators:
Structured extraction at scale: parsing 50 job posts is just a for loop.
# job_extraction_pipeline.py
import instructor
import csv
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import Optional, List
client = instructor.from_openai(OpenAI())
class JobPosting(BaseModel):
title: str = Field(description="Job title exactly as written")
company: str
location: str = Field(description="City/country or 'Remote'")
salary_min: Optional[int] = Field(None, description="Min annual salary USD")
salary_max: Optional[int] = Field(None, description="Max annual salary USD")
required_years: Optional[int] = Field(None, description="Years of experience required")
technologies: List[str] = Field(description="List of technologies mentioned")
is_remote: bool
# Sample job postings to process
JOB_TEXTS = [
"""Senior Python Engineer at Nexaflow -- Remote-first.
$150k-$190k. 5+ years Python, FastAPI, PostgreSQL, AWS required.""",
"""Junior Data Scientist at BioMetrics Ltd (London, UK).
GBP 45,000-55,000. 0-2 years exp, pandas, scikit-learn, matplotlib.""",
"""Staff ML Engineer at Quantra -- San Francisco CA.
$220,000 - $280,000/yr. 8+ years, PyTorch, CUDA, distributed training.""",
]
def extract_jobs(texts: List[str]) -> List[JobPosting]:
"""Extract structured job data from raw posting texts."""
jobs = []
for i, text in enumerate(texts, 1):
job = client.chat.completions.create(
model="gpt-4o-mini",
response_model=JobPosting,
max_retries=3,
messages=[{"role": "user", "content": f"Extract job details:\n\n{text}"}]
)
jobs.append(job)
print(f"[{i}/{len(texts)}] Extracted: {job.title} at {job.company}")
return jobs
def filter_remote(jobs: List[JobPosting]) -> List[JobPosting]:
return [j for j in jobs if j.is_remote]
def export_csv(jobs: List[JobPosting], path: str) -> None:
with open(path, "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(["Title", "Company", "Location", "Salary Min", "Salary Max",
"Yrs Required", "Technologies", "Remote"])
for j in jobs:
writer.writerow([
j.title, j.company, j.location,
j.salary_min or "", j.salary_max or "",
j.required_years or "",
", ".join(j.technologies),
j.is_remote
])
if __name__ == "__main__":
print("Extracting job postings...")
jobs = extract_jobs(JOB_TEXTS)
remote_jobs = filter_remote(jobs)
print(f"\nTotal extracted: {len(jobs)}, Remote: {len(remote_jobs)}")
export_csv(jobs, "jobs_extracted.csv")
print("Saved to jobs_extracted.csv")
Output:
Extracting job postings...
[1/3] Extracted: Senior Python Engineer at Nexaflow
[2/3] Extracted: Junior Data Scientist at BioMetrics Ltd
[3/3] Extracted: Staff ML Engineer at Quantra
Total extracted: 3, Remote: 1
Saved to jobs_extracted.csv
This pipeline is easy to extend: add a database write step, connect it to a web scraper that feeds real job pages, or add more validation rules to the JobPosting model. The core pattern — extract once, validate automatically, retry on failure — stays the same regardless of the scale. You can process thousands of postings by replacing JOB_TEXTS with a generator that reads from a queue or database, keeping the extraction logic identical.
Frequently Asked Questions
Does instructor increase API costs because of retries?
Yes, each retry is an additional API call, so failed extractions cost more. In practice, with well-designed schemas and clear field descriptions, validation failures are rare — under 5% for most extraction tasks. The cost increase is usually worth the reliability gain. If cost is a concern, use max_retries=1 and handle exceptions in your code rather than retrying automatically.
Does instructor support streaming responses?
Yes. Use response_model=Iterable[YourModel] for streaming lists, or Partial[YourModel] for streaming partial updates to a single model. Streaming is useful for large extractions where you want to process results as they arrive rather than waiting for the full response. See the instructor documentation for the streaming API details.
What happens when the model cannot extract a field?
If the field is typed as Optional[X], the model will return None for missing information. If the field is required (non-Optional), the model will either hallucinate a value or fail validation, triggering a retry. For fields that may legitimately be absent in the source text, always use Optional with a None default. This is the most common mistake new users make.
Can I extract data from large documents?
Yes, but be aware of token limits. For documents larger than a few thousand words, split them into chunks and extract from each chunk separately. Use a List[YourModel] return type if a single document contains multiple items to extract (like a list of transactions in a bank statement). For very large documents, consider summarizing first with a regular completion call, then extracting from the summary.
How is this different from just prompting for JSON output?
Prompting for JSON works until it does not — the model adds markdown fences, writes a preamble sentence, or omits fields. instructor uses tool calling (not prompting) to enforce the schema, so the model cannot deviate from the structure. It also runs Pydantic validation on the result and retries if types or constraints are violated. The difference in reliability for production use is significant — JSON prompting is fine for experiments, but instructor is the right tool for pipelines where data quality matters.
Is my data sent to OpenAI when I use instructor?
instructor is a thin wrapper around the OpenAI SDK — your data goes to whatever API endpoint you configure, subject to that provider’s data policy. If you are processing sensitive data, use a self-hosted model via Ollama or another local inference server, and point instructor at your local endpoint with a custom base_url. The library itself does not send data anywhere — it only wraps the client you provide.
Conclusion
The instructor library solves one of the most persistent frustrations in LLM application development: getting the model to return data in the shape your code expects, every time. We covered patching the OpenAI client, defining Pydantic schemas with field descriptions, extracting nested and list objects, adding custom validation rules, configuring retries and modes, and using instructor with non-OpenAI providers. The job extraction pipeline demonstrated how these pieces combine into a production-ready pattern.
The next step is to extend the real-life example: add a web scraper to pull live job postings, or connect the extracted data to a database. With instructor handling the model-to-schema translation, you can focus entirely on the business logic of what to extract and what to do with it.
Full documentation and more examples are at python.useinstructor.com. The library’s GitHub has a large collection of real-world examples including classification, knowledge graph extraction, and citation-backed answers.
Python supports flat files (text, CSV, JSON), databases (SQLite, PostgreSQL, MySQL), key-value stores (Redis, shelve), pickle serialization, and cloud storage. The best choice depends on data size, structure, and access patterns.
When should I use SQLite vs a full database?
Use SQLite for single-user apps, prototypes, and small-to-medium datasets. Switch to PostgreSQL or MySQL for concurrent multi-user access, complex queries at scale, or production-grade reliability.
How do I save Python objects to disk?
Use pickle for Python-specific serialization, json for interoperable data, shelve for dictionary-like persistent storage, or databases for structured data. For data analysis, pandas can save to CSV, Parquet, or HDF5.
Is JSON or CSV better for storing data?
JSON handles nested, hierarchical data well. CSV is simpler for tabular, flat data. Use JSON for API data and configuration; use CSV for datasets and spreadsheet-compatible exports.
How do I choose between file storage and a database?
Use file storage for simple, single-user scenarios. Use a database when you need querying, indexing, concurrent access, or ACID transactions. SQLite bridges both worlds for simpler applications.
Python is among the top programming languages that have been used in recent years in designing high-end technologies, such as Machine Learning, artificial intelligence, and data science. Programmers also use Python as their language of choice in developing large-scale applications that scale several products and services. This is why reputed companies hire candidates with good knowledge in coding with Python and other programming skills.
However, despite all these, some python myths can be a concern for aspiring developers. Below are some of the python programming myths you can easily come across.
1. Python is Slow
While Python is admissibly slower than Java and C++, it responds faster than JavaScript, Ruby, and other languages. Python features have specific runtimes and are not slower than other languages. Therefore, using Python for complicated applications saves time, and you’ll be done in a few minutes.
Some years ago, CPUs and memory were costly. However, currently, you can buy better-performing hardware at an affordable price to support programming with Python. Python also supports several programming paradigms, making it functional and imperative.
Python is slow. Python is too pretty. Python doesn’t scale. All wrong.
2. Python is Not Compiled and Only Used for Scripting
Python is generally an interpreted coding language since it falls in this category but is also considered a compiled language like Java and other programming languages. The compiling process is automated, making it difficult to detect, and a separate compiler isn’t required. It mostly compiles on virtual machines.
Python isn’t a scripting language wholly but more of a general-purpose coding language that can be used for scripting. Like most scripting languages, Python doesn’t have networking, regular expression, and exception features. This makes it a reliable and trusted programming language that can automate several tasks.
3. Learning to Code with Python is difficult and Time-consuming
Learning to program with Python is easy as it doesn’t require any prior programming knowledge. However, coding experts are advantaged as they can easily relate to its concepts. Python is a high-level language that can easily be implemented. Most of its syntax is simple mathematical instructions and calculations.
Most statements written in python programs look familiar with the English language as it contains less syntax. That said, learning to code with Python can take between three to six months, depending on your commitment. Besides, there are plenty of learning resources and a large supporting community that is ready to help learners.
4. Python is Not Scalable
Contrary to what most people believe, Python can scale both horizontally and vertically better than other languages. However, there is some confusion about this. The scaling process isn’t automated, thus requires some engineering effort. Scaling Python isn’t a straightforward process as it requires several entities.
For instance, you should make the most from the underlying memory, enhance single systems into distributed form, and more. Nonetheless, with proper architecture, scaling Python won’t be a problem.
Python runs your bank, your search engine, and your spacecraft.
5. Coding with Python is Expensive
You are highly mistaken if you think python programming is expensive. Unlike other coding languages, Python is an open-source language that can be downloaded for free from its official website. Python was officially developed in 1991 and is managed under the Python Software Foundation, which guarantees small and large scale users an Open Source License.
However, most of Python’s licenses remain open-source, though others are not. Some contributions, especially those from the General Public License, require users to pay a fee to access customizations added by other developers.
6. Python has Support and Security Issues
Another common myth is that Python isn’t secure, and code lines can easily be hacked. Most programmers believe the assumption that python codes are prone to cyberattacks. In contrast, Python has been used to build networking security systems. The language is also used to develop security testing tools and automation testing, which perform faster compared to others.
On the other hand, Python’s support team is always on standby and ready to assist in case of security issues affecting python programmers. You can contact them anytime, and your details will be kept confidential. Python has also adapted PayPal, eBay, and other highly-secured third-party payment gateways to prove its legitimacy.
7. Python Cannot be used for Big Projects
Just because Python is a simple language doesn’t mean it cannot be applied in big projects. Python has reusable codes and an extensive predefined library, which allow developers to create new codes tailored to suit project needs. Python libraries are also reusable, reducing the amount of time and effort required to write codes. Other languages are quite complicated and take long before a program is designed and implemented. This explains why tech giants, including Google, Facebook, YouTube, and Instagram, use this language.
Major websites / internet services written in Python
The Bottom Line
There is a lot to discover about Python and other programming languages in general. You shouldn’t agree easily to some of these baseless and unproven myths and misconceptions, which often arise during specific situations. That said, if you have some python programming basics, check out this course to learn UX/UI design and advance your skills to also expand your applications to cover front end as well.
[mfe_send_fox title=”Join the Python Insiders Group and get FREE tips in your inbox” body=”
Also, when you subscribe, we will send you a list of the most useful python one liners which will help you save time, make your code more readable, and which you can use immediately in your code! Subscribe to our email list and get the list now!
If you are new to the world of computer programming, choosing a programming language, to begin with, is probably the toughest hurdle. Currently, there are thousands of programming languages with different idiosyncrasies and complexities. On our site, we focus on Python, but there are other languages out there. Before you start your software development journey, choosing a programming language that suits your interests and career goals is important. That said, below are some of the best and in-demand coding languages you should consider.
1. JavaScript
Modern software developers cannot succeed without mastering JavaScript. A 2020 survey done by Stack Overflow found that JavaScript is still the most popular programming language for developers for eight years in a row. More than 70% of study participants reported that they used this language for more than one year.
Together with CSS and HTML, JavaScript is an important coding language for front-end website development. Most websites, including Facebook, Gmail, YouTube, and Twitter, depend on JavaScript to display dynamic content to users for their interactive website pages.
Even though JavaScript is primarily a front-end web development language on browsers, it can be used on the server-side to develop scalable network applications with the help of Node.js. Node.js works with Windows, Linux, Mac OS, and SunOs.
JavaScript is a popular language amongst programming beginners because of its simple learning curve. It is used all through the web, thanks to its speed, and works well with other coding languages, enabling it to be used in various applications. That aside, the demand for JavaScript developers is currently high, with a CareerFoundry study concluding that 72% of businesses need JavaScript developers.
Pros of learning JavaScript
Fast and can run immediately in browsers
Provides an enriched and better web interface
Highly versatile
It can be used in various applications
Has multiple add-ons
Easily integrates with other programming languages.
Cons of learning JavaScript
Lacks an equivalent or alternate method
Different web browsers can interpret code lines differently.
2. Python
Python is a general-purpose coding language that is also very learner-friendly; there are even Python classes for children. However, despite being easy to learn, Python is an overly versatile and powerful language, making it suitable for beginners and experts. It is because of this that major companies, including Facebook and Google, use this language.
Python’s popularity is largely attributed to its extensive usage. It has applications in data science, scientific computing, data analytics, animation, database interfacing, web applications, machine learning, and data visualization. This versatility also explains the high demand for experts in this language.
Key features of Python include;
It has a unique selling point – simple, productive, elegant, and powerful in one package.
It influences other programming languages, such as Go and Julia
Best for back-end web development with first-class integration with other programming languages, such as C++ and C.
It offers many tools that can be applied in computational science, mathematics, statistics, and various libraries and frameworks, such as NumPy, Scikit-Learn, and Pandas.
Pros of learning Python
Works in various platforms
Improves developers and programmers productivity
Has a wide array of support frameworks and libraries
Powered by object-oriented programming
Cons of learning Python
Not ideal for mobile computing
It has a primitive and underdeveloped database
Python won the language war. Just not the speed war.
3. Java
Java is another popular coding language commonly used in-app and web development. Despite being an old coding language, Java is still in demand due to its complexity. Unfortunately, it isn’t beginner-friendly. It is a platform-independent language and a popular choice for various organizations, including Google and Airbnb, for its stability.
Key features of Java include;
It is a multi-paradigm and feature-rich programming language
Very productive for developers
Moderate learning curve
It doesn’t have major changes and updates like Python and Scala
Has the best runtime
Pros of learning Java
Has a wide array of open-source libraries
Automated garbage collection
Allows for platform independence
Supports multithreading and distributed computing
Has multiple APIs that support completion of various tasks, such as database connection, networking, and XML parsing
Cons of learning Java
Expensive memory management
Slow compared to other coding languages, such as C and C++
4. C#
C# is an object-oriented programming language developed by Microsoft. It was initially designed as part of the .NET framework for developing windows applications but is currently used in various applications. It is a general-purpose coding language used particularly in back-end development, game creation, mobile app development, and more. Despite being a Windows-specific language, it can also be used in Android, Linux, and iOS platforms.
The language has a legion of libraries and frameworks that have accrued for the last 20 years. Like Java, C# is independent of other platforms, thanks to its Common Language Runtime feature.
Pros of learning C#
Can work with shared codebases
Safe compared C++ and C
Uses similar syntax with C++ and other C-derived languages
Has rich data types and library
Has a fast compilation and execution
Cons of learning C#
Less flexible compared to C++
You should have good knowledge to solve errors
Same web app, two stacks. The stack matters less than the team.
5. PHP
PHP is another excellent programming language with many applications. While it faces stiff competition from other languages, such as Python and JavaScript, especially for web development, there is still a high demand for PHP professionals in the current job market. PHP is also a general-purpose and dynamic coding language that can be used to develop server-side applications.
Pros of learning PHP
Easy to learn and use
Has a wide ecosystem and community support
Has many frameworks
Supports object-oriented and functional paradigms
Supports various automation tools
Cons of PHP
Builds slow web pages
Lacks error and security handling features
6. Angular
Angular is a recently updated and improved version of the initial AngularJS framework developed by Google. Compared to other recent coding languages, such as React, Angular has a steep learning curve but offers better practical solutions for front-end development. Developers can also program complicated and scalable applications using Angular, thanks to its great functionality, aesthetic visual designs, and business logic.
Key features of Angular include;
Features a model-view control architecture that facilitates dynamic modeling
Uses HTML coding language to develop user interfaces that are simple and easy to understand
Uses old JavaScript objects, which are self-sufficient and very functional
Has Angular filters, which filter data before being viewed
Pros of learning Angular
Requires minimal coding experience to use
Allows development of high-quality hybrid apps
Has quick app prototyping
Has enhanced testing ability
Cons of Angular
Angular developed apps are dynamic, diminishing their performance
Complicated pages in apps can cause glitches
Difficult to learn
Python or JavaScript? Pick what your team can hire for.
7. React
Also called ReactJS, React is a JavaScript framework developed by Facebook that enables programmers to develop user interfaces with dynamic abilities. Sites built using React respond faster, and developers can switch between multiple variable elements seamlessly. The language also enables businesses to build and maintain customer loyalty by providing a great user experience.
Pros of learning React
Easy to learn and SEO friendly
Reuses various components, thus saves time
Has an open-source library
Supported by a strong online community
Has plenty of helpful development tools
Cons of React
Additional SEO hurdle
Has poor code documentation
The Bottom Line
As you choose your preferred web development language to learn, ensure that you aren’t guided by flashy inclinations and popularity contests. Even though the realm of computer programming keeps changing rapidly, the languages mentioned above can withstand these changes. Learning one or more of these languages will put you in a great position for many years to come. Make use of federal funding to pay for your online programming courses and Bootcamps. Veterans can learn web development languages at a discount using the GI Bill Benefits.
You ask an LLM to extract a user’s name, age, and email from a paragraph of text. Sometimes it returns clean JSON. Sometimes it returns JSON wrapped in markdown fences. Sometimes it returns a paragraph explaining why it extracted those fields. If you have ever built a pipeline that breaks because the model decided today was a good day to add “Sure! Here is the extracted data:” before the JSON, you already understand why instructor exists.
The instructor library patches the OpenAI client (and any OpenAI-compatible API) to force the model to return a fully validated Pydantic model — every time. When validation fails, it retries automatically. You define exactly what fields you need, with their types and constraints, and instructor handles the conversation with the model until the output matches your schema. You need Python 3.9+, an OpenAI API key (or compatible endpoint), and pip install instructor.
This article walks through everything you need to get structured LLM outputs in production: installing and patching the client, defining Pydantic schemas, extracting nested objects, handling lists, using validation hooks, working with non-OpenAI models via LiteLLM, and building a real extraction pipeline. By the end you will have a reusable pattern for reliable structured data from any LLM.
Structured LLM Output: Quick Example
The fastest way to see instructor in action is to extract a structured object from a single sentence. Install the library and try this:
# quick_instructor.py
import instructor
from openai import OpenAI
from pydantic import BaseModel
client = instructor.from_openai(OpenAI())
class Person(BaseModel):
name: str
age: int
city: str
person = client.chat.completions.create(
model="gpt-4o-mini",
response_model=Person,
messages=[{"role": "user", "content": "Alice is 32 years old and lives in Melbourne."}]
)
print(person.name) # Alice
print(person.age) # 32
print(person.city) # Melbourne
print(type(person)) # <class '__main__.Person'>
Output:
Alice
32
Melbourne
<class '__main__.Person'>
The key line is instructor.from_openai(OpenAI()) — this patches the standard OpenAI client. After that, you pass response_model=Person to any chat.completions.create call, and instructor automatically: sends the Pydantic schema to the model as a tool definition, parses the model’s tool-call response, validates it against your schema, and retries if validation fails. The return value is a fully typed Pydantic object, not a string or dict.
That example covers the simplest case. The sections below show how to handle nested models, lists, validation rules, retry configuration, and real-world pipelines.
response_model= and the chaos becomes a schema.
What Is instructor and Why Use It?
When you call an LLM without constraints, it returns free-form text. Parsing that text into structured data is fragile — you write regex, JSON parsers, and fallback handlers that break every time the model changes its wording. instructor solves this by using OpenAI’s function/tool calling feature under the hood: it converts your Pydantic model into a JSON Schema tool definition, forces the model to call that tool, and validates the returned arguments against your schema.
The result is LLM output that behaves like a typed function return value instead of a string you have to parse. If the model returns a field with the wrong type (for example, age as a string “thirty-two” instead of an integer), instructor sends the validation error back to the model and asks it to try again — up to a configurable number of retries.
Approach
Reliability
Type Safety
Auto-Retry
Parse raw LLM text
Fragile
None
Manual
Parse JSON from prompt
Moderate
Manual
Manual
OpenAI function calling
Good
Partial
None
instructor + Pydantic
High
Full
Built-in
The library supports multiple backends: instructor.from_openai, instructor.from_anthropic, instructor.from_gemini, and any OpenAI-compatible endpoint via base_url. This makes it the same interface regardless of which model you use.
Installation and Setup
Install instructor and the OpenAI SDK together. If you are using a different provider, you may also need their SDK:
# Terminal
pip install instructor openai pydantic
Set your API key as an environment variable so it never appears in your code:
# setup_env.py -- run once, or add to your shell profile
import os
# In practice, set this in your shell:
# export OPENAI_API_KEY="sk-..."
print("OPENAI_API_KEY set:", bool(os.environ.get("OPENAI_API_KEY")))
Output:
OPENAI_API_KEY set: True
Patch the client once at startup and reuse it for all calls. Creating a new patched client for every request is wasteful:
# client_setup.py
import instructor
from openai import OpenAI
# Patch once at startup
client = instructor.from_openai(OpenAI()) # reads OPENAI_API_KEY from env
# The client now has response_model support on all completion calls
print(type(client)) # <class 'instructor.client.Instructor'>
Output:
<class 'instructor.client.Instructor'>
One patch. Every completion call now speaks schema.
Defining Pydantic Schemas for Extraction
Your Pydantic model defines exactly what fields the LLM must return. Field descriptions improve accuracy significantly — the model uses them as instructions for what to put in each field. Use Field(description=...) to guide the extraction:
# schema_example.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import Optional
client = instructor.from_openai(OpenAI())
class JobPosting(BaseModel):
title: str = Field(description="The exact job title as written in the posting")
company: str = Field(description="Company name offering the position")
location: str = Field(description="City and country, or 'Remote'")
salary_min: Optional[int] = Field(None, description="Minimum annual salary in USD if mentioned")
salary_max: Optional[int] = Field(None, description="Maximum annual salary in USD if mentioned")
is_remote: bool = Field(description="True if the role allows remote work")
text = """
Senior Python Developer at DataFlow Inc. -- Remote (US timezones preferred).
Salary range: $140,000 - $175,000 per year. Must have 5+ years Python experience.
"""
job = client.chat.completions.create(
model="gpt-4o-mini",
response_model=JobPosting,
messages=[{"role": "user", "content": f"Extract the job details from: {text}"}]
)
print(f"Title: {job.title}")
print(f"Company: {job.company}")
print(f"Location: {job.location}")
print(f"Salary: ${job.salary_min:,} - ${job.salary_max:,}")
print(f"Remote: {job.is_remote}")
The Optional[int] type tells instructor (and the model) that salary fields may be absent. When the source text does not mention a salary, these fields will be None instead of hallucinated values. Always use Optional for fields that may not appear in the input — without it, the model will invent plausible-sounding values rather than leaving the field empty.
Extracting Nested and List Objects
Real-world extraction often requires nested structures — for example, an invoice with multiple line items, or a resume with a list of work experiences. instructor handles nested Pydantic models and List types natively:
# nested_extraction.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import List
client = instructor.from_openai(OpenAI())
class LineItem(BaseModel):
description: str
quantity: int
unit_price: float
class Invoice(BaseModel):
vendor: str
invoice_number: str
items: List[LineItem]
total: float
invoice_text = """
Invoice #INV-2024-0891 from CloudHost Solutions
- 3x Server instances @ $45.00 each
- 1x SSL Certificate @ $12.00
- 2x Domain registrations @ $15.00 each
Total: $222.00
"""
result = client.chat.completions.create(
model="gpt-4o-mini",
response_model=Invoice,
messages=[{"role": "user", "content": f"Extract invoice data: {invoice_text}"}]
)
print(f"Vendor: {result.vendor}")
print(f"Invoice #: {result.invoice_number}")
for item in result.items:
print(f" {item.quantity}x {item.description} @ ${item.unit_price:.2f}")
print(f"Total: ${result.total:.2f}")
Nested models work because instructor converts the entire schema — including nested classes — into a JSON Schema definition that the model understands. The model fills in every field of every nested object, and Pydantic validates the whole structure recursively. If the items list is missing or a line item has an invalid type, instructor retries the extraction with the validation error as feedback.
Nested Pydantic models: recursion that actually works.
Adding Custom Validation Rules
Pydantic’s field_validator lets you add business logic on top of type checking. instructor automatically feeds validation errors back to the model, so the model gets a second (or third) chance to return values that satisfy your rules:
# custom_validation.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field, field_validator
from typing import List
client = instructor.from_openai(OpenAI())
class ProductReview(BaseModel):
product_name: str
rating: int = Field(description="Rating from 1 to 5")
pros: List[str] = Field(description="List of positive aspects, at least one")
cons: List[str] = Field(description="List of negative aspects, can be empty")
summary: str = Field(description="One-sentence summary under 150 characters")
@field_validator("rating")
@classmethod
def rating_in_range(cls, v: int) -> int:
if not 1 <= v <= 5:
raise ValueError(f"Rating must be between 1 and 5, got {v}")
return v
@field_validator("pros")
@classmethod
def at_least_one_pro(cls, v: List[str]) -> List[str]:
if not v:
raise ValueError("Must include at least one positive aspect")
return v
@field_validator("summary")
@classmethod
def summary_length(cls, v: str) -> str:
if len(v) > 150:
raise ValueError(f"Summary too long: {len(v)} chars (max 150)")
return v
text = """
The new Python IDE is pretty solid. Boot time is fast, autocomplete works well.
The memory usage is high and the plugin store is still sparse. Overall a decent
choice for Python development. I'd give it 4 out of 5.
"""
review = client.chat.completions.create(
model="gpt-4o-mini",
response_model=ProductReview,
messages=[{"role": "user", "content": f"Extract review details: {text}"}]
)
print(f"Product: {review.product_name}")
print(f"Rating: {review.rating}/5")
print(f"Pros: {review.pros}")
print(f"Cons: {review.cons}")
print(f"Summary: {review.summary}")
Output:
Product: Python IDE
Rating: 4/5
Pros: ['Fast boot time', 'Good autocomplete']
Cons: ['High memory usage', 'Sparse plugin store']
Summary: A solid Python IDE with fast performance but limited plugins and high memory usage.
When a validator raises ValueError, instructor captures the error message and sends it back to the model in a follow-up message: “Validation failed: Rating must be between 1 and 5, got 6. Please fix and try again.” The model then self-corrects. By default, instructor retries up to 3 times before raising an exception. You can configure this with max_retries=N on the completion call.
Configuring Retries and Modes
instructor supports several extraction modes depending on what your model supports. The default mode uses OpenAI’s tool calling, but you can switch to JSON mode or other strategies:
# retry_config.py
import instructor
from instructor import Mode
from openai import OpenAI
from pydantic import BaseModel
# Default: tool calling (most reliable for OpenAI models)
client_tools = instructor.from_openai(OpenAI())
# JSON mode: model returns raw JSON instead of a tool call
client_json = instructor.from_openai(OpenAI(), mode=Mode.JSON)
# MD_JSON mode: model wraps JSON in markdown fences (useful for some fine-tunes)
client_md = instructor.from_openai(OpenAI(), mode=Mode.MD_JSON)
class City(BaseModel):
name: str
country: str
population: int
# Control retries per-call
city = client_tools.chat.completions.create(
model="gpt-4o-mini",
response_model=City,
max_retries=5, # retry up to 5 times on validation failure
messages=[{"role": "user", "content": "Tell me about Tokyo"}]
)
print(f"{city.name}, {city.country}: pop {city.population:,}")
Output:
Tokyo, Japan: pop 13,960,000
For most OpenAI models, the default tool-calling mode is most reliable. Use Mode.JSON for models that support JSON mode but not tool calling — for example, some fine-tuned models or older GPT versions. The max_retries parameter controls how many times instructor will re-prompt the model when validation fails. For production pipelines where data quality matters more than cost, set this to 3-5.
Three retries and a Pydantic error. That’s the whole self-correction system.
Using instructor with Non-OpenAI Models
If you are using Anthropic’s Claude, Google Gemini, or a local model via Ollama, instructor has provider-specific patches. For OpenAI-compatible endpoints (like local LLMs with an OpenAI-compatible API), you can pass a custom base_url:
# multi_provider.py
import instructor
from anthropic import Anthropic
from pydantic import BaseModel
# Anthropic Claude -- uses a different client class
anthropic_client = instructor.from_anthropic(Anthropic())
class Sentiment(BaseModel):
label: str # "positive", "negative", or "neutral"
score: float # confidence from 0.0 to 1.0
reason: str # one-sentence explanation
result = anthropic_client.messages.create(
model="claude-3-haiku-20240307",
max_tokens=256,
response_model=Sentiment,
messages=[{
"role": "user",
"content": "This new Python library is fantastic, saves me hours every week!"
}]
)
print(f"Sentiment: {result.label} ({result.score:.0%})")
print(f"Reason: {result.reason}")
Output:
Sentiment: positive (96%)
Reason: The user expresses strong enthusiasm and quantifies time savings, indicating genuine satisfaction.
For local models via Ollama (which provides an OpenAI-compatible API on localhost:11434), create the client with a custom base URL:
# ollama_instructor.py
import instructor
from openai import OpenAI
from pydantic import BaseModel
# Ollama runs an OpenAI-compatible server locally
ollama_client = instructor.from_openai(
OpenAI(base_url="http://localhost:11434/v1", api_key="ollama"),
mode=instructor.Mode.JSON # use JSON mode for local models
)
class Summary(BaseModel):
headline: str
key_points: list[str]
# Works the same as OpenAI -- just a different backend
# summary = ollama_client.chat.completions.create(
# model="llama3.2",
# response_model=Summary,
# messages=[{"role": "user", "content": "Summarize Python's async/await model"}]
# )
print("Local model client ready -- uncomment to use with Ollama running")
Output:
Local model client ready -- uncomment to use with Ollama running
Here is a complete pipeline that reads job postings from a list of texts, extracts structured data, filters by criteria, and exports to CSV — the kind of task that comes up in recruiting tools, market research, and job aggregators:
Structured extraction at scale: parsing 50 job posts is just a for loop.
# job_extraction_pipeline.py
import instructor
import csv
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import Optional, List
client = instructor.from_openai(OpenAI())
class JobPosting(BaseModel):
title: str = Field(description="Job title exactly as written")
company: str
location: str = Field(description="City/country or 'Remote'")
salary_min: Optional[int] = Field(None, description="Min annual salary USD")
salary_max: Optional[int] = Field(None, description="Max annual salary USD")
required_years: Optional[int] = Field(None, description="Years of experience required")
technologies: List[str] = Field(description="List of technologies mentioned")
is_remote: bool
# Sample job postings to process
JOB_TEXTS = [
"""Senior Python Engineer at Nexaflow -- Remote-first.
$150k-$190k. 5+ years Python, FastAPI, PostgreSQL, AWS required.""",
"""Junior Data Scientist at BioMetrics Ltd (London, UK).
GBP 45,000-55,000. 0-2 years exp, pandas, scikit-learn, matplotlib.""",
"""Staff ML Engineer at Quantra -- San Francisco CA.
$220,000 - $280,000/yr. 8+ years, PyTorch, CUDA, distributed training.""",
]
def extract_jobs(texts: List[str]) -> List[JobPosting]:
"""Extract structured job data from raw posting texts."""
jobs = []
for i, text in enumerate(texts, 1):
job = client.chat.completions.create(
model="gpt-4o-mini",
response_model=JobPosting,
max_retries=3,
messages=[{"role": "user", "content": f"Extract job details:\n\n{text}"}]
)
jobs.append(job)
print(f"[{i}/{len(texts)}] Extracted: {job.title} at {job.company}")
return jobs
def filter_remote(jobs: List[JobPosting]) -> List[JobPosting]:
return [j for j in jobs if j.is_remote]
def export_csv(jobs: List[JobPosting], path: str) -> None:
with open(path, "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(["Title", "Company", "Location", "Salary Min", "Salary Max",
"Yrs Required", "Technologies", "Remote"])
for j in jobs:
writer.writerow([
j.title, j.company, j.location,
j.salary_min or "", j.salary_max or "",
j.required_years or "",
", ".join(j.technologies),
j.is_remote
])
if __name__ == "__main__":
print("Extracting job postings...")
jobs = extract_jobs(JOB_TEXTS)
remote_jobs = filter_remote(jobs)
print(f"\nTotal extracted: {len(jobs)}, Remote: {len(remote_jobs)}")
export_csv(jobs, "jobs_extracted.csv")
print("Saved to jobs_extracted.csv")
Output:
Extracting job postings...
[1/3] Extracted: Senior Python Engineer at Nexaflow
[2/3] Extracted: Junior Data Scientist at BioMetrics Ltd
[3/3] Extracted: Staff ML Engineer at Quantra
Total extracted: 3, Remote: 1
Saved to jobs_extracted.csv
This pipeline is easy to extend: add a database write step, connect it to a web scraper that feeds real job pages, or add more validation rules to the JobPosting model. The core pattern — extract once, validate automatically, retry on failure — stays the same regardless of the scale. You can process thousands of postings by replacing JOB_TEXTS with a generator that reads from a queue or database, keeping the extraction logic identical.
Frequently Asked Questions
Does instructor increase API costs because of retries?
Yes, each retry is an additional API call, so failed extractions cost more. In practice, with well-designed schemas and clear field descriptions, validation failures are rare — under 5% for most extraction tasks. The cost increase is usually worth the reliability gain. If cost is a concern, use max_retries=1 and handle exceptions in your code rather than retrying automatically.
Does instructor support streaming responses?
Yes. Use response_model=Iterable[YourModel] for streaming lists, or Partial[YourModel] for streaming partial updates to a single model. Streaming is useful for large extractions where you want to process results as they arrive rather than waiting for the full response. See the instructor documentation for the streaming API details.
What happens when the model cannot extract a field?
If the field is typed as Optional[X], the model will return None for missing information. If the field is required (non-Optional), the model will either hallucinate a value or fail validation, triggering a retry. For fields that may legitimately be absent in the source text, always use Optional with a None default. This is the most common mistake new users make.
Can I extract data from large documents?
Yes, but be aware of token limits. For documents larger than a few thousand words, split them into chunks and extract from each chunk separately. Use a List[YourModel] return type if a single document contains multiple items to extract (like a list of transactions in a bank statement). For very large documents, consider summarizing first with a regular completion call, then extracting from the summary.
How is this different from just prompting for JSON output?
Prompting for JSON works until it does not — the model adds markdown fences, writes a preamble sentence, or omits fields. instructor uses tool calling (not prompting) to enforce the schema, so the model cannot deviate from the structure. It also runs Pydantic validation on the result and retries if types or constraints are violated. The difference in reliability for production use is significant — JSON prompting is fine for experiments, but instructor is the right tool for pipelines where data quality matters.
Is my data sent to OpenAI when I use instructor?
instructor is a thin wrapper around the OpenAI SDK — your data goes to whatever API endpoint you configure, subject to that provider’s data policy. If you are processing sensitive data, use a self-hosted model via Ollama or another local inference server, and point instructor at your local endpoint with a custom base_url. The library itself does not send data anywhere — it only wraps the client you provide.
Conclusion
The instructor library solves one of the most persistent frustrations in LLM application development: getting the model to return data in the shape your code expects, every time. We covered patching the OpenAI client, defining Pydantic schemas with field descriptions, extracting nested and list objects, adding custom validation rules, configuring retries and modes, and using instructor with non-OpenAI providers. The job extraction pipeline demonstrated how these pieces combine into a production-ready pattern.
The next step is to extend the real-life example: add a web scraper to pull live job postings, or connect the extracted data to a database. With instructor handling the model-to-schema translation, you can focus entirely on the business logic of what to extract and what to do with it.
Full documentation and more examples are at python.useinstructor.com. The library’s GitHub has a large collection of real-world examples including classification, knowledge graph extraction, and citation-backed answers.
How does Python compare to JavaScript for web development?
Python excels in backend development with Django and Flask. JavaScript dominates the frontend and runs on the backend with Node.js. Python is preferred for data-heavy backends, while JavaScript enables full-stack development with a single language.
Is Python slower than other web languages?
Python is generally slower in raw execution speed compared to Go, Java, or Node.js. However, for most web apps the bottleneck is I/O, not CPU speed. Python’s developer productivity and rich ecosystem often outweigh the performance difference.
Can Python be used for frontend web development?
Python is primarily a backend language. Tools like Brython, Pyodide, and PyScript allow Python in the browser, but for production frontends JavaScript/TypeScript with React or Vue remains the standard.
What makes Python a good choice for web APIs?
Python offers mature API frameworks (Flask, FastAPI, Django REST Framework), excellent library support for data processing, simple syntax, and strong integration with databases, ML models, and third-party services.
Should I learn Python or JavaScript for web development?
Learn Python if you focus on data science, ML, or backend APIs. Learn JavaScript for full-stack web development. Many developers learn both. Python’s versatility across web, data, and automation makes it a strong choice.
The easiest and simplest mechanism to store data from python is the humble file storage which is often, but does not have to be, text based. There are no libraries that you require, and you can use native python functions to open and write to the file very easily.
There are many use cases for file storage and is usually the “go to” method when hacking a quick solution or prototype together. These are also arguably good solutions for production use cases.
Overview of using storing data to files in Python
The typical use cases has the following commonalities:
Setup: There’s no setup that is required for files. You can create the file even from python
Volume: Size Small-ish file size (< 5-10mb). You can go larger of course if your application is not doing heavy reads or writes nor if it doesn’t require fast response (e.g. batch processing)
Record access: Does not require to search data within the file to extract just portion of the records. You would load or save all the data in the file in one go
Data Writes: You can either append to the file or you can upload and download all data in the file.
Write reliability: You do not need to have multiple writes at the same time – there is only possibility (or likelihood) of one person writing at one time, and if there was a case of multiple people writing at once, the consequence are not serious for your application. There are ways to put a lock on a file to prevent conflicts, but you should double check if a file is the write option for you
Data formats: You may have structured record based (such as comma separated value – CSV or tab delimited) or unstructured (eg document of text or JSON format). You can also store binary data in a file as well – e.g. for images
Editability: You may want or allow direct editing of the file by other applications or direct editing by people
Redundancy: There’s no inbuilt redundancy. If there is any failure (data corrupt, the server with the file fails), then you’re out of luck. You need to setup your own mechanisms (e.g. replicate file to another server automatically)
Code examples to read and write to a file
Here are two sets of example code for writing and reading from a file. It is very easy and does not require any libraries. The one thing to be mindful of is what mode you want the file to be opened- read, write, read and write.
Open a text file for (over)writing:
To write to a file, it’s very easy to do so which is to use the ‘w’ switch on the open() function. There are other options as well:
‘r’ – Reading
‘w’ – Writing to a file
‘a’ – Append to end of file
‘r+’ – Read and write to the same file
‘x’ – Used to create and write to a new file
file = open( ‘population.txt’, ‘w’)
file.write(‘Japan’)
file.write(‘United States’)
file.write(‘Australia’)
file.write(‘China’)
file.close() #file is released and closed
You will then have the following output file of population.txt:
Japan
United States
Australia
China
Open a text file fully for reading:
Using the same population.txt file created above –
file = open( ‘population.txt’, ‘r’)
data = file.read() #read full contents of file into a single string
file.close() #file is released and closed
print(“*** file start ***”)
print( data )
print(“*** end file ***”)
The output would be:
*** file start ***
Japan
United States
Australia
China
*** end file ***
Now to explain this a bit further, the open() command helps to open a file where you need to specify how the file is to be opened – in this case with ‘r’ to indicate it is for reading. There are other options as well:
‘r’ – Reading
‘w’ – Writing to a file
‘a’ – Append to end of file
‘r+’ – Read and write to the same file
‘x’ – Used to create and write to a new file
Read a text file line by line:
file = open( ‘population.txt’, ‘r’)
data_list = file.readlines() #read full contents of file into a list of rows
file.close() #file is released and closed
print(“*** file start ***”)
counter = 0
for row in data_list:
counter = counter + 1
print( f”{counter}: {data_list}” )
print(“*** end file ***”)
The output would be:
*** file start ***
1: Japan
2: United States
3: Australia
4: China
*** end file ***
The difference in above to the first example is that the data comes out in a list separated by a newline so that you can process each row. Please note, you can simplify the above using the enumerate to avoid having the separate counter variable setup. E.g.
print(“*** file start ***”)
for index, row in enumerate(data_list):
print( f”{index+1}: {data_list}” ) #Note that when using enumerate, first index is 0
print(“*** end file ***”)
Read a file in 3 lines. Write it in 4. Everything else is detail.
Summary of writing and reading to a file
Reading and writing to a file is a very straightforward native operation in Python. There are many other related operations that you can do ranging from putting a lock on a file to prevent two processes writing to the same file, checking file attributes such as access and size, and many other operations. At the most basic though, you can simply use the “open” statement to do the read/write to satisfy most of your needs.
You ask an LLM to extract a user’s name, age, and email from a paragraph of text. Sometimes it returns clean JSON. Sometimes it returns JSON wrapped in markdown fences. Sometimes it returns a paragraph explaining why it extracted those fields. If you have ever built a pipeline that breaks because the model decided today was a good day to add “Sure! Here is the extracted data:” before the JSON, you already understand why instructor exists.
The instructor library patches the OpenAI client (and any OpenAI-compatible API) to force the model to return a fully validated Pydantic model — every time. When validation fails, it retries automatically. You define exactly what fields you need, with their types and constraints, and instructor handles the conversation with the model until the output matches your schema. You need Python 3.9+, an OpenAI API key (or compatible endpoint), and pip install instructor.
This article walks through everything you need to get structured LLM outputs in production: installing and patching the client, defining Pydantic schemas, extracting nested objects, handling lists, using validation hooks, working with non-OpenAI models via LiteLLM, and building a real extraction pipeline. By the end you will have a reusable pattern for reliable structured data from any LLM.
Structured LLM Output: Quick Example
The fastest way to see instructor in action is to extract a structured object from a single sentence. Install the library and try this:
# quick_instructor.py
import instructor
from openai import OpenAI
from pydantic import BaseModel
client = instructor.from_openai(OpenAI())
class Person(BaseModel):
name: str
age: int
city: str
person = client.chat.completions.create(
model="gpt-4o-mini",
response_model=Person,
messages=[{"role": "user", "content": "Alice is 32 years old and lives in Melbourne."}]
)
print(person.name) # Alice
print(person.age) # 32
print(person.city) # Melbourne
print(type(person)) # <class '__main__.Person'>
Output:
Alice
32
Melbourne
<class '__main__.Person'>
The key line is instructor.from_openai(OpenAI()) — this patches the standard OpenAI client. After that, you pass response_model=Person to any chat.completions.create call, and instructor automatically: sends the Pydantic schema to the model as a tool definition, parses the model’s tool-call response, validates it against your schema, and retries if validation fails. The return value is a fully typed Pydantic object, not a string or dict.
That example covers the simplest case. The sections below show how to handle nested models, lists, validation rules, retry configuration, and real-world pipelines.
response_model= and the chaos becomes a schema.
What Is instructor and Why Use It?
When you call an LLM without constraints, it returns free-form text. Parsing that text into structured data is fragile — you write regex, JSON parsers, and fallback handlers that break every time the model changes its wording. instructor solves this by using OpenAI’s function/tool calling feature under the hood: it converts your Pydantic model into a JSON Schema tool definition, forces the model to call that tool, and validates the returned arguments against your schema.
The result is LLM output that behaves like a typed function return value instead of a string you have to parse. If the model returns a field with the wrong type (for example, age as a string “thirty-two” instead of an integer), instructor sends the validation error back to the model and asks it to try again — up to a configurable number of retries.
Approach
Reliability
Type Safety
Auto-Retry
Parse raw LLM text
Fragile
None
Manual
Parse JSON from prompt
Moderate
Manual
Manual
OpenAI function calling
Good
Partial
None
instructor + Pydantic
High
Full
Built-in
The library supports multiple backends: instructor.from_openai, instructor.from_anthropic, instructor.from_gemini, and any OpenAI-compatible endpoint via base_url. This makes it the same interface regardless of which model you use.
Installation and Setup
Install instructor and the OpenAI SDK together. If you are using a different provider, you may also need their SDK:
# Terminal
pip install instructor openai pydantic
Set your API key as an environment variable so it never appears in your code:
# setup_env.py -- run once, or add to your shell profile
import os
# In practice, set this in your shell:
# export OPENAI_API_KEY="sk-..."
print("OPENAI_API_KEY set:", bool(os.environ.get("OPENAI_API_KEY")))
Output:
OPENAI_API_KEY set: True
Patch the client once at startup and reuse it for all calls. Creating a new patched client for every request is wasteful:
# client_setup.py
import instructor
from openai import OpenAI
# Patch once at startup
client = instructor.from_openai(OpenAI()) # reads OPENAI_API_KEY from env
# The client now has response_model support on all completion calls
print(type(client)) # <class 'instructor.client.Instructor'>
Output:
<class 'instructor.client.Instructor'>
One patch. Every completion call now speaks schema.
Defining Pydantic Schemas for Extraction
Your Pydantic model defines exactly what fields the LLM must return. Field descriptions improve accuracy significantly — the model uses them as instructions for what to put in each field. Use Field(description=...) to guide the extraction:
# schema_example.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import Optional
client = instructor.from_openai(OpenAI())
class JobPosting(BaseModel):
title: str = Field(description="The exact job title as written in the posting")
company: str = Field(description="Company name offering the position")
location: str = Field(description="City and country, or 'Remote'")
salary_min: Optional[int] = Field(None, description="Minimum annual salary in USD if mentioned")
salary_max: Optional[int] = Field(None, description="Maximum annual salary in USD if mentioned")
is_remote: bool = Field(description="True if the role allows remote work")
text = """
Senior Python Developer at DataFlow Inc. -- Remote (US timezones preferred).
Salary range: $140,000 - $175,000 per year. Must have 5+ years Python experience.
"""
job = client.chat.completions.create(
model="gpt-4o-mini",
response_model=JobPosting,
messages=[{"role": "user", "content": f"Extract the job details from: {text}"}]
)
print(f"Title: {job.title}")
print(f"Company: {job.company}")
print(f"Location: {job.location}")
print(f"Salary: ${job.salary_min:,} - ${job.salary_max:,}")
print(f"Remote: {job.is_remote}")
The Optional[int] type tells instructor (and the model) that salary fields may be absent. When the source text does not mention a salary, these fields will be None instead of hallucinated values. Always use Optional for fields that may not appear in the input — without it, the model will invent plausible-sounding values rather than leaving the field empty.
Extracting Nested and List Objects
Real-world extraction often requires nested structures — for example, an invoice with multiple line items, or a resume with a list of work experiences. instructor handles nested Pydantic models and List types natively:
# nested_extraction.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import List
client = instructor.from_openai(OpenAI())
class LineItem(BaseModel):
description: str
quantity: int
unit_price: float
class Invoice(BaseModel):
vendor: str
invoice_number: str
items: List[LineItem]
total: float
invoice_text = """
Invoice #INV-2024-0891 from CloudHost Solutions
- 3x Server instances @ $45.00 each
- 1x SSL Certificate @ $12.00
- 2x Domain registrations @ $15.00 each
Total: $222.00
"""
result = client.chat.completions.create(
model="gpt-4o-mini",
response_model=Invoice,
messages=[{"role": "user", "content": f"Extract invoice data: {invoice_text}"}]
)
print(f"Vendor: {result.vendor}")
print(f"Invoice #: {result.invoice_number}")
for item in result.items:
print(f" {item.quantity}x {item.description} @ ${item.unit_price:.2f}")
print(f"Total: ${result.total:.2f}")
Nested models work because instructor converts the entire schema — including nested classes — into a JSON Schema definition that the model understands. The model fills in every field of every nested object, and Pydantic validates the whole structure recursively. If the items list is missing or a line item has an invalid type, instructor retries the extraction with the validation error as feedback.
Nested Pydantic models: recursion that actually works.
Adding Custom Validation Rules
Pydantic’s field_validator lets you add business logic on top of type checking. instructor automatically feeds validation errors back to the model, so the model gets a second (or third) chance to return values that satisfy your rules:
# custom_validation.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field, field_validator
from typing import List
client = instructor.from_openai(OpenAI())
class ProductReview(BaseModel):
product_name: str
rating: int = Field(description="Rating from 1 to 5")
pros: List[str] = Field(description="List of positive aspects, at least one")
cons: List[str] = Field(description="List of negative aspects, can be empty")
summary: str = Field(description="One-sentence summary under 150 characters")
@field_validator("rating")
@classmethod
def rating_in_range(cls, v: int) -> int:
if not 1 <= v <= 5:
raise ValueError(f"Rating must be between 1 and 5, got {v}")
return v
@field_validator("pros")
@classmethod
def at_least_one_pro(cls, v: List[str]) -> List[str]:
if not v:
raise ValueError("Must include at least one positive aspect")
return v
@field_validator("summary")
@classmethod
def summary_length(cls, v: str) -> str:
if len(v) > 150:
raise ValueError(f"Summary too long: {len(v)} chars (max 150)")
return v
text = """
The new Python IDE is pretty solid. Boot time is fast, autocomplete works well.
The memory usage is high and the plugin store is still sparse. Overall a decent
choice for Python development. I'd give it 4 out of 5.
"""
review = client.chat.completions.create(
model="gpt-4o-mini",
response_model=ProductReview,
messages=[{"role": "user", "content": f"Extract review details: {text}"}]
)
print(f"Product: {review.product_name}")
print(f"Rating: {review.rating}/5")
print(f"Pros: {review.pros}")
print(f"Cons: {review.cons}")
print(f"Summary: {review.summary}")
Output:
Product: Python IDE
Rating: 4/5
Pros: ['Fast boot time', 'Good autocomplete']
Cons: ['High memory usage', 'Sparse plugin store']
Summary: A solid Python IDE with fast performance but limited plugins and high memory usage.
When a validator raises ValueError, instructor captures the error message and sends it back to the model in a follow-up message: “Validation failed: Rating must be between 1 and 5, got 6. Please fix and try again.” The model then self-corrects. By default, instructor retries up to 3 times before raising an exception. You can configure this with max_retries=N on the completion call.
Configuring Retries and Modes
instructor supports several extraction modes depending on what your model supports. The default mode uses OpenAI’s tool calling, but you can switch to JSON mode or other strategies:
# retry_config.py
import instructor
from instructor import Mode
from openai import OpenAI
from pydantic import BaseModel
# Default: tool calling (most reliable for OpenAI models)
client_tools = instructor.from_openai(OpenAI())
# JSON mode: model returns raw JSON instead of a tool call
client_json = instructor.from_openai(OpenAI(), mode=Mode.JSON)
# MD_JSON mode: model wraps JSON in markdown fences (useful for some fine-tunes)
client_md = instructor.from_openai(OpenAI(), mode=Mode.MD_JSON)
class City(BaseModel):
name: str
country: str
population: int
# Control retries per-call
city = client_tools.chat.completions.create(
model="gpt-4o-mini",
response_model=City,
max_retries=5, # retry up to 5 times on validation failure
messages=[{"role": "user", "content": "Tell me about Tokyo"}]
)
print(f"{city.name}, {city.country}: pop {city.population:,}")
Output:
Tokyo, Japan: pop 13,960,000
For most OpenAI models, the default tool-calling mode is most reliable. Use Mode.JSON for models that support JSON mode but not tool calling — for example, some fine-tuned models or older GPT versions. The max_retries parameter controls how many times instructor will re-prompt the model when validation fails. For production pipelines where data quality matters more than cost, set this to 3-5.
Three retries and a Pydantic error. That’s the whole self-correction system.
Using instructor with Non-OpenAI Models
If you are using Anthropic’s Claude, Google Gemini, or a local model via Ollama, instructor has provider-specific patches. For OpenAI-compatible endpoints (like local LLMs with an OpenAI-compatible API), you can pass a custom base_url:
# multi_provider.py
import instructor
from anthropic import Anthropic
from pydantic import BaseModel
# Anthropic Claude -- uses a different client class
anthropic_client = instructor.from_anthropic(Anthropic())
class Sentiment(BaseModel):
label: str # "positive", "negative", or "neutral"
score: float # confidence from 0.0 to 1.0
reason: str # one-sentence explanation
result = anthropic_client.messages.create(
model="claude-3-haiku-20240307",
max_tokens=256,
response_model=Sentiment,
messages=[{
"role": "user",
"content": "This new Python library is fantastic, saves me hours every week!"
}]
)
print(f"Sentiment: {result.label} ({result.score:.0%})")
print(f"Reason: {result.reason}")
Output:
Sentiment: positive (96%)
Reason: The user expresses strong enthusiasm and quantifies time savings, indicating genuine satisfaction.
For local models via Ollama (which provides an OpenAI-compatible API on localhost:11434), create the client with a custom base URL:
# ollama_instructor.py
import instructor
from openai import OpenAI
from pydantic import BaseModel
# Ollama runs an OpenAI-compatible server locally
ollama_client = instructor.from_openai(
OpenAI(base_url="http://localhost:11434/v1", api_key="ollama"),
mode=instructor.Mode.JSON # use JSON mode for local models
)
class Summary(BaseModel):
headline: str
key_points: list[str]
# Works the same as OpenAI -- just a different backend
# summary = ollama_client.chat.completions.create(
# model="llama3.2",
# response_model=Summary,
# messages=[{"role": "user", "content": "Summarize Python's async/await model"}]
# )
print("Local model client ready -- uncomment to use with Ollama running")
Output:
Local model client ready -- uncomment to use with Ollama running
Here is a complete pipeline that reads job postings from a list of texts, extracts structured data, filters by criteria, and exports to CSV — the kind of task that comes up in recruiting tools, market research, and job aggregators:
Structured extraction at scale: parsing 50 job posts is just a for loop.
# job_extraction_pipeline.py
import instructor
import csv
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import Optional, List
client = instructor.from_openai(OpenAI())
class JobPosting(BaseModel):
title: str = Field(description="Job title exactly as written")
company: str
location: str = Field(description="City/country or 'Remote'")
salary_min: Optional[int] = Field(None, description="Min annual salary USD")
salary_max: Optional[int] = Field(None, description="Max annual salary USD")
required_years: Optional[int] = Field(None, description="Years of experience required")
technologies: List[str] = Field(description="List of technologies mentioned")
is_remote: bool
# Sample job postings to process
JOB_TEXTS = [
"""Senior Python Engineer at Nexaflow -- Remote-first.
$150k-$190k. 5+ years Python, FastAPI, PostgreSQL, AWS required.""",
"""Junior Data Scientist at BioMetrics Ltd (London, UK).
GBP 45,000-55,000. 0-2 years exp, pandas, scikit-learn, matplotlib.""",
"""Staff ML Engineer at Quantra -- San Francisco CA.
$220,000 - $280,000/yr. 8+ years, PyTorch, CUDA, distributed training.""",
]
def extract_jobs(texts: List[str]) -> List[JobPosting]:
"""Extract structured job data from raw posting texts."""
jobs = []
for i, text in enumerate(texts, 1):
job = client.chat.completions.create(
model="gpt-4o-mini",
response_model=JobPosting,
max_retries=3,
messages=[{"role": "user", "content": f"Extract job details:\n\n{text}"}]
)
jobs.append(job)
print(f"[{i}/{len(texts)}] Extracted: {job.title} at {job.company}")
return jobs
def filter_remote(jobs: List[JobPosting]) -> List[JobPosting]:
return [j for j in jobs if j.is_remote]
def export_csv(jobs: List[JobPosting], path: str) -> None:
with open(path, "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(["Title", "Company", "Location", "Salary Min", "Salary Max",
"Yrs Required", "Technologies", "Remote"])
for j in jobs:
writer.writerow([
j.title, j.company, j.location,
j.salary_min or "", j.salary_max or "",
j.required_years or "",
", ".join(j.technologies),
j.is_remote
])
if __name__ == "__main__":
print("Extracting job postings...")
jobs = extract_jobs(JOB_TEXTS)
remote_jobs = filter_remote(jobs)
print(f"\nTotal extracted: {len(jobs)}, Remote: {len(remote_jobs)}")
export_csv(jobs, "jobs_extracted.csv")
print("Saved to jobs_extracted.csv")
Output:
Extracting job postings...
[1/3] Extracted: Senior Python Engineer at Nexaflow
[2/3] Extracted: Junior Data Scientist at BioMetrics Ltd
[3/3] Extracted: Staff ML Engineer at Quantra
Total extracted: 3, Remote: 1
Saved to jobs_extracted.csv
This pipeline is easy to extend: add a database write step, connect it to a web scraper that feeds real job pages, or add more validation rules to the JobPosting model. The core pattern — extract once, validate automatically, retry on failure — stays the same regardless of the scale. You can process thousands of postings by replacing JOB_TEXTS with a generator that reads from a queue or database, keeping the extraction logic identical.
Frequently Asked Questions
Does instructor increase API costs because of retries?
Yes, each retry is an additional API call, so failed extractions cost more. In practice, with well-designed schemas and clear field descriptions, validation failures are rare — under 5% for most extraction tasks. The cost increase is usually worth the reliability gain. If cost is a concern, use max_retries=1 and handle exceptions in your code rather than retrying automatically.
Does instructor support streaming responses?
Yes. Use response_model=Iterable[YourModel] for streaming lists, or Partial[YourModel] for streaming partial updates to a single model. Streaming is useful for large extractions where you want to process results as they arrive rather than waiting for the full response. See the instructor documentation for the streaming API details.
What happens when the model cannot extract a field?
If the field is typed as Optional[X], the model will return None for missing information. If the field is required (non-Optional), the model will either hallucinate a value or fail validation, triggering a retry. For fields that may legitimately be absent in the source text, always use Optional with a None default. This is the most common mistake new users make.
Can I extract data from large documents?
Yes, but be aware of token limits. For documents larger than a few thousand words, split them into chunks and extract from each chunk separately. Use a List[YourModel] return type if a single document contains multiple items to extract (like a list of transactions in a bank statement). For very large documents, consider summarizing first with a regular completion call, then extracting from the summary.
How is this different from just prompting for JSON output?
Prompting for JSON works until it does not — the model adds markdown fences, writes a preamble sentence, or omits fields. instructor uses tool calling (not prompting) to enforce the schema, so the model cannot deviate from the structure. It also runs Pydantic validation on the result and retries if types or constraints are violated. The difference in reliability for production use is significant — JSON prompting is fine for experiments, but instructor is the right tool for pipelines where data quality matters.
Is my data sent to OpenAI when I use instructor?
instructor is a thin wrapper around the OpenAI SDK — your data goes to whatever API endpoint you configure, subject to that provider’s data policy. If you are processing sensitive data, use a self-hosted model via Ollama or another local inference server, and point instructor at your local endpoint with a custom base_url. The library itself does not send data anywhere — it only wraps the client you provide.
Conclusion
The instructor library solves one of the most persistent frustrations in LLM application development: getting the model to return data in the shape your code expects, every time. We covered patching the OpenAI client, defining Pydantic schemas with field descriptions, extracting nested and list objects, adding custom validation rules, configuring retries and modes, and using instructor with non-OpenAI providers. The job extraction pipeline demonstrated how these pieces combine into a production-ready pattern.
The next step is to extend the real-life example: add a web scraper to pull live job postings, or connect the extracted data to a database. With instructor handling the model-to-schema translation, you can focus entirely on the business logic of what to extract and what to do with it.
Full documentation and more examples are at python.useinstructor.com. The library’s GitHub has a large collection of real-world examples including classification, knowledge graph extraction, and citation-backed answers.
Forgot to close the file? Welcome to the leak club.
Frequently Asked Questions
How do I read a text file in Python?
Use open('file.txt', 'r') with a with statement: with open('file.txt') as f: content = f.read(). This reads the entire file and automatically closes it. Use f.readlines() to get a list of lines instead.
What is the difference between read(), readline(), and readlines()?
read() returns the entire file as a single string. readline() reads one line at a time. readlines() returns a list of all lines. For large files, iterating with for line in f: is the most memory-efficient approach.
How do I write to a file in Python?
Use open('file.txt', 'w') to write (overwrites existing content) or 'a' to append. Write with f.write('text') or f.writelines(list_of_strings). Always use a with statement to ensure the file is properly closed.
What encoding should I use when reading text files?
Use encoding='utf-8' for most modern text files. UTF-8 handles international characters and is the default on most systems. For legacy files, you may need 'latin-1' or 'cp1252'.
How do I handle file not found errors in Python?
Use a try/except block catching FileNotFoundError. Alternatively, check if the file exists first with pathlib.Path('file.txt').exists() before attempting to read it.
A config file is a flat file but is used for reading and writing of settings that affect the behaviour of your application. These files can be incredibly useful so that you can put individual settings inside the human editable file and then have the settings read from your application. This helps you configure your application in the way you need without having to change the application code.
Typically the config file is edited by a simple text editor by the user, then the application runs and reads the config file. If there are any changes to the config file, normally (depending how the code is written), the application will then have to be restarted to take on the new settings.
Some of the considerations for using a config file as a “data store” includes:
Setup: There’s no setup that is required for files. You should use one of the config management python libraries that are available to make it easier to manipulate config files.
Volume: Size Small-ish file size (< 5-10mb)
Record access: Does not require to search data within the file to extract just a portion of the records. You would load or save all the data in the file in one go
Data Writes: Applications don’t generally write to a config file, but it can be done. Instead the config file is edited outside in a text editor
Data formats: Normally the data would be a structured record based (such as comma separated value – CSV or tab delimited), or a more complex structure such as what you see in windows based .INI files or JSON format even
Editability: You generally want to allow direct editing of the file by users
Redundancy: There’s no inbuilt redundancy. If there is any failure (data corrupt, the server with the file fails), then you’re out of luck. You need to setup your own mechanisms (e.g. replicate file to another server automatically)
Code examples to read and write from config file using ConfigParse
Setting up a config file is actually not that much harder than simply creating a constants inside your application. Your main decision will be what type of configuration file format you’d like to use as there are quite a few to choose from. Here are some options and samples:
Example 1: Simple text file which is tab-delimited
You can see a full article on how to read a text file in our “Storing Data in Files in Python” article. The short version of open a tab delimited file is as follows:
Suppose you have a configuration file as follows where each row has two fields which is separated by a tab:
Some explanation may be required on the code though to make it easier to understand. Firstly, the for loop is used to read a record line by line. So each time the for loop iterates, it will read a line into the field rec until the whole file is read.
The following code is a little tricky, but the intent is to take the two columns in the tab delimited file and create a dictionary key value pair.
It first removes the newline character from the end of the line (through rec.strip() )
This will then return a string which is then split with split() by the a tab characters (denoted by ‘\t’)
The result of this is a two filed array which is then created into a tuple format
The tuple is then put in a list and added to list with the [] brackets
The dictionary .update() method is used to finally add they key value pair
Example 2: A properties file with key value pair
If you have a fairly simple configuration needs with just a key-value pair, then a properties type file would work for you where you have <config name> = <config value>. This can be easily loaded as a text file and then the key-value be loaded into a dictionary.
The following code could easily load this configuration:
config = {}
with open('config_data.txt', 'r') as file_hander:
for rec in file_hander:
if rec.startswith('#'): continue
key, value = rec.strip().split('=')
if key: config[key] = value
print( config )
Here the code ignores any comment lines (e.g. the line starts with a ‘#’), and then string-splits the line by the ‘=’ sign. This will then load the dictionary ‘config’
[default]
name = development
host = 192.168.1.1
port = 31
username = admin
password = admin
[database]
name = production
host = 144.101.1.1
You can then read the file with the following simple code:
import configparser
config = configparser.ConfigParser()
#Open the file again to try to read it
config.read('test.ini')
print( config['database'][‘name’] ) #This will output ‘production’
print( config['database'][‘port’] ) #This will output ‘31’. As there is no port under# database the default value will be extracted
Example 4: Reading Config values from a JSON file
With JSON being so popular, this is also another alternative you could use to keep all your config data in. It is very easy to also load.
Assume your config file is as follows: config_data.txt
A config file is a great option if you are looking to store settings for your applications. These are usually loaded at the start of the application and then can be loaded into a dictionary which can then serve as a set of constants which your application can use. This will both avoid the need to hardcode settings and also allow you to change the behaviour of your application without having to touch the code.
You ask an LLM to extract a user’s name, age, and email from a paragraph of text. Sometimes it returns clean JSON. Sometimes it returns JSON wrapped in markdown fences. Sometimes it returns a paragraph explaining why it extracted those fields. If you have ever built a pipeline that breaks because the model decided today was a good day to add “Sure! Here is the extracted data:” before the JSON, you already understand why instructor exists.
The instructor library patches the OpenAI client (and any OpenAI-compatible API) to force the model to return a fully validated Pydantic model — every time. When validation fails, it retries automatically. You define exactly what fields you need, with their types and constraints, and instructor handles the conversation with the model until the output matches your schema. You need Python 3.9+, an OpenAI API key (or compatible endpoint), and pip install instructor.
This article walks through everything you need to get structured LLM outputs in production: installing and patching the client, defining Pydantic schemas, extracting nested objects, handling lists, using validation hooks, working with non-OpenAI models via LiteLLM, and building a real extraction pipeline. By the end you will have a reusable pattern for reliable structured data from any LLM.
Structured LLM Output: Quick Example
The fastest way to see instructor in action is to extract a structured object from a single sentence. Install the library and try this:
# quick_instructor.py
import instructor
from openai import OpenAI
from pydantic import BaseModel
client = instructor.from_openai(OpenAI())
class Person(BaseModel):
name: str
age: int
city: str
person = client.chat.completions.create(
model="gpt-4o-mini",
response_model=Person,
messages=[{"role": "user", "content": "Alice is 32 years old and lives in Melbourne."}]
)
print(person.name) # Alice
print(person.age) # 32
print(person.city) # Melbourne
print(type(person)) # <class '__main__.Person'>
Output:
Alice
32
Melbourne
<class '__main__.Person'>
The key line is instructor.from_openai(OpenAI()) — this patches the standard OpenAI client. After that, you pass response_model=Person to any chat.completions.create call, and instructor automatically: sends the Pydantic schema to the model as a tool definition, parses the model’s tool-call response, validates it against your schema, and retries if validation fails. The return value is a fully typed Pydantic object, not a string or dict.
That example covers the simplest case. The sections below show how to handle nested models, lists, validation rules, retry configuration, and real-world pipelines.
response_model= and the chaos becomes a schema.
What Is instructor and Why Use It?
When you call an LLM without constraints, it returns free-form text. Parsing that text into structured data is fragile — you write regex, JSON parsers, and fallback handlers that break every time the model changes its wording. instructor solves this by using OpenAI’s function/tool calling feature under the hood: it converts your Pydantic model into a JSON Schema tool definition, forces the model to call that tool, and validates the returned arguments against your schema.
The result is LLM output that behaves like a typed function return value instead of a string you have to parse. If the model returns a field with the wrong type (for example, age as a string “thirty-two” instead of an integer), instructor sends the validation error back to the model and asks it to try again — up to a configurable number of retries.
Approach
Reliability
Type Safety
Auto-Retry
Parse raw LLM text
Fragile
None
Manual
Parse JSON from prompt
Moderate
Manual
Manual
OpenAI function calling
Good
Partial
None
instructor + Pydantic
High
Full
Built-in
The library supports multiple backends: instructor.from_openai, instructor.from_anthropic, instructor.from_gemini, and any OpenAI-compatible endpoint via base_url. This makes it the same interface regardless of which model you use.
Installation and Setup
Install instructor and the OpenAI SDK together. If you are using a different provider, you may also need their SDK:
# Terminal
pip install instructor openai pydantic
Set your API key as an environment variable so it never appears in your code:
# setup_env.py -- run once, or add to your shell profile
import os
# In practice, set this in your shell:
# export OPENAI_API_KEY="sk-..."
print("OPENAI_API_KEY set:", bool(os.environ.get("OPENAI_API_KEY")))
Output:
OPENAI_API_KEY set: True
Patch the client once at startup and reuse it for all calls. Creating a new patched client for every request is wasteful:
# client_setup.py
import instructor
from openai import OpenAI
# Patch once at startup
client = instructor.from_openai(OpenAI()) # reads OPENAI_API_KEY from env
# The client now has response_model support on all completion calls
print(type(client)) # <class 'instructor.client.Instructor'>
Output:
<class 'instructor.client.Instructor'>
One patch. Every completion call now speaks schema.
Defining Pydantic Schemas for Extraction
Your Pydantic model defines exactly what fields the LLM must return. Field descriptions improve accuracy significantly — the model uses them as instructions for what to put in each field. Use Field(description=...) to guide the extraction:
# schema_example.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import Optional
client = instructor.from_openai(OpenAI())
class JobPosting(BaseModel):
title: str = Field(description="The exact job title as written in the posting")
company: str = Field(description="Company name offering the position")
location: str = Field(description="City and country, or 'Remote'")
salary_min: Optional[int] = Field(None, description="Minimum annual salary in USD if mentioned")
salary_max: Optional[int] = Field(None, description="Maximum annual salary in USD if mentioned")
is_remote: bool = Field(description="True if the role allows remote work")
text = """
Senior Python Developer at DataFlow Inc. -- Remote (US timezones preferred).
Salary range: $140,000 - $175,000 per year. Must have 5+ years Python experience.
"""
job = client.chat.completions.create(
model="gpt-4o-mini",
response_model=JobPosting,
messages=[{"role": "user", "content": f"Extract the job details from: {text}"}]
)
print(f"Title: {job.title}")
print(f"Company: {job.company}")
print(f"Location: {job.location}")
print(f"Salary: ${job.salary_min:,} - ${job.salary_max:,}")
print(f"Remote: {job.is_remote}")
The Optional[int] type tells instructor (and the model) that salary fields may be absent. When the source text does not mention a salary, these fields will be None instead of hallucinated values. Always use Optional for fields that may not appear in the input — without it, the model will invent plausible-sounding values rather than leaving the field empty.
Extracting Nested and List Objects
Real-world extraction often requires nested structures — for example, an invoice with multiple line items, or a resume with a list of work experiences. instructor handles nested Pydantic models and List types natively:
# nested_extraction.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import List
client = instructor.from_openai(OpenAI())
class LineItem(BaseModel):
description: str
quantity: int
unit_price: float
class Invoice(BaseModel):
vendor: str
invoice_number: str
items: List[LineItem]
total: float
invoice_text = """
Invoice #INV-2024-0891 from CloudHost Solutions
- 3x Server instances @ $45.00 each
- 1x SSL Certificate @ $12.00
- 2x Domain registrations @ $15.00 each
Total: $222.00
"""
result = client.chat.completions.create(
model="gpt-4o-mini",
response_model=Invoice,
messages=[{"role": "user", "content": f"Extract invoice data: {invoice_text}"}]
)
print(f"Vendor: {result.vendor}")
print(f"Invoice #: {result.invoice_number}")
for item in result.items:
print(f" {item.quantity}x {item.description} @ ${item.unit_price:.2f}")
print(f"Total: ${result.total:.2f}")
Nested models work because instructor converts the entire schema — including nested classes — into a JSON Schema definition that the model understands. The model fills in every field of every nested object, and Pydantic validates the whole structure recursively. If the items list is missing or a line item has an invalid type, instructor retries the extraction with the validation error as feedback.
Nested Pydantic models: recursion that actually works.
Adding Custom Validation Rules
Pydantic’s field_validator lets you add business logic on top of type checking. instructor automatically feeds validation errors back to the model, so the model gets a second (or third) chance to return values that satisfy your rules:
# custom_validation.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field, field_validator
from typing import List
client = instructor.from_openai(OpenAI())
class ProductReview(BaseModel):
product_name: str
rating: int = Field(description="Rating from 1 to 5")
pros: List[str] = Field(description="List of positive aspects, at least one")
cons: List[str] = Field(description="List of negative aspects, can be empty")
summary: str = Field(description="One-sentence summary under 150 characters")
@field_validator("rating")
@classmethod
def rating_in_range(cls, v: int) -> int:
if not 1 <= v <= 5:
raise ValueError(f"Rating must be between 1 and 5, got {v}")
return v
@field_validator("pros")
@classmethod
def at_least_one_pro(cls, v: List[str]) -> List[str]:
if not v:
raise ValueError("Must include at least one positive aspect")
return v
@field_validator("summary")
@classmethod
def summary_length(cls, v: str) -> str:
if len(v) > 150:
raise ValueError(f"Summary too long: {len(v)} chars (max 150)")
return v
text = """
The new Python IDE is pretty solid. Boot time is fast, autocomplete works well.
The memory usage is high and the plugin store is still sparse. Overall a decent
choice for Python development. I'd give it 4 out of 5.
"""
review = client.chat.completions.create(
model="gpt-4o-mini",
response_model=ProductReview,
messages=[{"role": "user", "content": f"Extract review details: {text}"}]
)
print(f"Product: {review.product_name}")
print(f"Rating: {review.rating}/5")
print(f"Pros: {review.pros}")
print(f"Cons: {review.cons}")
print(f"Summary: {review.summary}")
Output:
Product: Python IDE
Rating: 4/5
Pros: ['Fast boot time', 'Good autocomplete']
Cons: ['High memory usage', 'Sparse plugin store']
Summary: A solid Python IDE with fast performance but limited plugins and high memory usage.
When a validator raises ValueError, instructor captures the error message and sends it back to the model in a follow-up message: “Validation failed: Rating must be between 1 and 5, got 6. Please fix and try again.” The model then self-corrects. By default, instructor retries up to 3 times before raising an exception. You can configure this with max_retries=N on the completion call.
Configuring Retries and Modes
instructor supports several extraction modes depending on what your model supports. The default mode uses OpenAI’s tool calling, but you can switch to JSON mode or other strategies:
# retry_config.py
import instructor
from instructor import Mode
from openai import OpenAI
from pydantic import BaseModel
# Default: tool calling (most reliable for OpenAI models)
client_tools = instructor.from_openai(OpenAI())
# JSON mode: model returns raw JSON instead of a tool call
client_json = instructor.from_openai(OpenAI(), mode=Mode.JSON)
# MD_JSON mode: model wraps JSON in markdown fences (useful for some fine-tunes)
client_md = instructor.from_openai(OpenAI(), mode=Mode.MD_JSON)
class City(BaseModel):
name: str
country: str
population: int
# Control retries per-call
city = client_tools.chat.completions.create(
model="gpt-4o-mini",
response_model=City,
max_retries=5, # retry up to 5 times on validation failure
messages=[{"role": "user", "content": "Tell me about Tokyo"}]
)
print(f"{city.name}, {city.country}: pop {city.population:,}")
Output:
Tokyo, Japan: pop 13,960,000
For most OpenAI models, the default tool-calling mode is most reliable. Use Mode.JSON for models that support JSON mode but not tool calling — for example, some fine-tuned models or older GPT versions. The max_retries parameter controls how many times instructor will re-prompt the model when validation fails. For production pipelines where data quality matters more than cost, set this to 3-5.
Three retries and a Pydantic error. That’s the whole self-correction system.
Using instructor with Non-OpenAI Models
If you are using Anthropic’s Claude, Google Gemini, or a local model via Ollama, instructor has provider-specific patches. For OpenAI-compatible endpoints (like local LLMs with an OpenAI-compatible API), you can pass a custom base_url:
# multi_provider.py
import instructor
from anthropic import Anthropic
from pydantic import BaseModel
# Anthropic Claude -- uses a different client class
anthropic_client = instructor.from_anthropic(Anthropic())
class Sentiment(BaseModel):
label: str # "positive", "negative", or "neutral"
score: float # confidence from 0.0 to 1.0
reason: str # one-sentence explanation
result = anthropic_client.messages.create(
model="claude-3-haiku-20240307",
max_tokens=256,
response_model=Sentiment,
messages=[{
"role": "user",
"content": "This new Python library is fantastic, saves me hours every week!"
}]
)
print(f"Sentiment: {result.label} ({result.score:.0%})")
print(f"Reason: {result.reason}")
Output:
Sentiment: positive (96%)
Reason: The user expresses strong enthusiasm and quantifies time savings, indicating genuine satisfaction.
For local models via Ollama (which provides an OpenAI-compatible API on localhost:11434), create the client with a custom base URL:
# ollama_instructor.py
import instructor
from openai import OpenAI
from pydantic import BaseModel
# Ollama runs an OpenAI-compatible server locally
ollama_client = instructor.from_openai(
OpenAI(base_url="http://localhost:11434/v1", api_key="ollama"),
mode=instructor.Mode.JSON # use JSON mode for local models
)
class Summary(BaseModel):
headline: str
key_points: list[str]
# Works the same as OpenAI -- just a different backend
# summary = ollama_client.chat.completions.create(
# model="llama3.2",
# response_model=Summary,
# messages=[{"role": "user", "content": "Summarize Python's async/await model"}]
# )
print("Local model client ready -- uncomment to use with Ollama running")
Output:
Local model client ready -- uncomment to use with Ollama running
Here is a complete pipeline that reads job postings from a list of texts, extracts structured data, filters by criteria, and exports to CSV — the kind of task that comes up in recruiting tools, market research, and job aggregators:
Structured extraction at scale: parsing 50 job posts is just a for loop.
# job_extraction_pipeline.py
import instructor
import csv
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import Optional, List
client = instructor.from_openai(OpenAI())
class JobPosting(BaseModel):
title: str = Field(description="Job title exactly as written")
company: str
location: str = Field(description="City/country or 'Remote'")
salary_min: Optional[int] = Field(None, description="Min annual salary USD")
salary_max: Optional[int] = Field(None, description="Max annual salary USD")
required_years: Optional[int] = Field(None, description="Years of experience required")
technologies: List[str] = Field(description="List of technologies mentioned")
is_remote: bool
# Sample job postings to process
JOB_TEXTS = [
"""Senior Python Engineer at Nexaflow -- Remote-first.
$150k-$190k. 5+ years Python, FastAPI, PostgreSQL, AWS required.""",
"""Junior Data Scientist at BioMetrics Ltd (London, UK).
GBP 45,000-55,000. 0-2 years exp, pandas, scikit-learn, matplotlib.""",
"""Staff ML Engineer at Quantra -- San Francisco CA.
$220,000 - $280,000/yr. 8+ years, PyTorch, CUDA, distributed training.""",
]
def extract_jobs(texts: List[str]) -> List[JobPosting]:
"""Extract structured job data from raw posting texts."""
jobs = []
for i, text in enumerate(texts, 1):
job = client.chat.completions.create(
model="gpt-4o-mini",
response_model=JobPosting,
max_retries=3,
messages=[{"role": "user", "content": f"Extract job details:\n\n{text}"}]
)
jobs.append(job)
print(f"[{i}/{len(texts)}] Extracted: {job.title} at {job.company}")
return jobs
def filter_remote(jobs: List[JobPosting]) -> List[JobPosting]:
return [j for j in jobs if j.is_remote]
def export_csv(jobs: List[JobPosting], path: str) -> None:
with open(path, "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(["Title", "Company", "Location", "Salary Min", "Salary Max",
"Yrs Required", "Technologies", "Remote"])
for j in jobs:
writer.writerow([
j.title, j.company, j.location,
j.salary_min or "", j.salary_max or "",
j.required_years or "",
", ".join(j.technologies),
j.is_remote
])
if __name__ == "__main__":
print("Extracting job postings...")
jobs = extract_jobs(JOB_TEXTS)
remote_jobs = filter_remote(jobs)
print(f"\nTotal extracted: {len(jobs)}, Remote: {len(remote_jobs)}")
export_csv(jobs, "jobs_extracted.csv")
print("Saved to jobs_extracted.csv")
Output:
Extracting job postings...
[1/3] Extracted: Senior Python Engineer at Nexaflow
[2/3] Extracted: Junior Data Scientist at BioMetrics Ltd
[3/3] Extracted: Staff ML Engineer at Quantra
Total extracted: 3, Remote: 1
Saved to jobs_extracted.csv
This pipeline is easy to extend: add a database write step, connect it to a web scraper that feeds real job pages, or add more validation rules to the JobPosting model. The core pattern — extract once, validate automatically, retry on failure — stays the same regardless of the scale. You can process thousands of postings by replacing JOB_TEXTS with a generator that reads from a queue or database, keeping the extraction logic identical.
Frequently Asked Questions
Does instructor increase API costs because of retries?
Yes, each retry is an additional API call, so failed extractions cost more. In practice, with well-designed schemas and clear field descriptions, validation failures are rare — under 5% for most extraction tasks. The cost increase is usually worth the reliability gain. If cost is a concern, use max_retries=1 and handle exceptions in your code rather than retrying automatically.
Does instructor support streaming responses?
Yes. Use response_model=Iterable[YourModel] for streaming lists, or Partial[YourModel] for streaming partial updates to a single model. Streaming is useful for large extractions where you want to process results as they arrive rather than waiting for the full response. See the instructor documentation for the streaming API details.
What happens when the model cannot extract a field?
If the field is typed as Optional[X], the model will return None for missing information. If the field is required (non-Optional), the model will either hallucinate a value or fail validation, triggering a retry. For fields that may legitimately be absent in the source text, always use Optional with a None default. This is the most common mistake new users make.
Can I extract data from large documents?
Yes, but be aware of token limits. For documents larger than a few thousand words, split them into chunks and extract from each chunk separately. Use a List[YourModel] return type if a single document contains multiple items to extract (like a list of transactions in a bank statement). For very large documents, consider summarizing first with a regular completion call, then extracting from the summary.
How is this different from just prompting for JSON output?
Prompting for JSON works until it does not — the model adds markdown fences, writes a preamble sentence, or omits fields. instructor uses tool calling (not prompting) to enforce the schema, so the model cannot deviate from the structure. It also runs Pydantic validation on the result and retries if types or constraints are violated. The difference in reliability for production use is significant — JSON prompting is fine for experiments, but instructor is the right tool for pipelines where data quality matters.
Is my data sent to OpenAI when I use instructor?
instructor is a thin wrapper around the OpenAI SDK — your data goes to whatever API endpoint you configure, subject to that provider’s data policy. If you are processing sensitive data, use a self-hosted model via Ollama or another local inference server, and point instructor at your local endpoint with a custom base_url. The library itself does not send data anywhere — it only wraps the client you provide.
Conclusion
The instructor library solves one of the most persistent frustrations in LLM application development: getting the model to return data in the shape your code expects, every time. We covered patching the OpenAI client, defining Pydantic schemas with field descriptions, extracting nested and list objects, adding custom validation rules, configuring retries and modes, and using instructor with non-OpenAI providers. The job extraction pipeline demonstrated how these pieces combine into a production-ready pattern.
The next step is to extend the real-life example: add a web scraper to pull live job postings, or connect the extracted data to a database. With instructor handling the model-to-schema translation, you can focus entirely on the business logic of what to extract and what to do with it.
Full documentation and more examples are at python.useinstructor.com. The library’s GitHub has a large collection of real-world examples including classification, knowledge graph extraction, and citation-backed answers.
For simple key-value settings, use INI files with ConfigParser. For nested data, use JSON or TOML. For environment-specific settings, use .env files with python-dotenv. The best choice depends on your complexity needs and whether non-developers will edit the settings.
How do I create a config file in Python?
Use ConfigParser to create INI files: instantiate the parser, add sections and key-value pairs with config['section'] = {'key': 'value'}, then write with config.write(open('config.ini', 'w')). For JSON, use json.dump().
Should I use environment variables or config files?
Use environment variables for sensitive data (API keys, passwords) and deployment-specific settings. Use config files for application-level settings that rarely change. Many projects combine both: a config file for defaults and environment variables for overrides and secrets.
How do I prevent config files from being committed to Git?
Add your config file names to .gitignore (e.g., config.ini, .env). Provide a config.example.ini template in the repository so other developers know what settings are needed without exposing actual values.
Can I use YAML for Python configuration files?
Yes. Install PyYAML with pip install pyyaml and use yaml.safe_load() to read YAML files. YAML supports nested structures, lists, and comments, making it more expressive than INI. However, it is not part of Python’s standard library.
Importing modules or packages (in other languages this would be referred to as libraries) is a fundamental aspect of the language which makes it so useful. As of this writing, the most popular python package library, pypi.org, has over 300k packages to import. This isn’t just important for importing of external packages. It also becomes a must when your own project becomes quite large. You need to make sure you can split your code into manageable logical chunks which can talk to each other. This is what this article is all about.
What’s the difference between a python package vs module
First, some terminology. A module, is a single python file (still with a .py extension) that contains some code which you can import. While a package, is a collection of files. In your project, a package is all the files in a given directory and where the directory also contains the file __init__.py to signal that this is a package.
What happens when you import a python module
There is nothing special in fact you need to do to make a module – all python files are by default a module and can be imported. When a file is imported, all the code does get processed – e.g. if there’s any code to be executed it will run.
See following example. Suppose we have the following relationship:
We have main_file.py importing two modules
Code as follows:
#module1.py
print("module1: I'm in module 1 root section")
def output_hw():
print("module1: Hello world - output_hw 1")
#module2.py
import module1
print("module2: I'm in root section of module 2")
def output_hw():
print("module2: Hello world - output_hw 2")
#main_file.py
print("main_file: starting code")
import module1
import module2
print("main_file: I'm in the root section ")
if __name__ == '__main__':
print("main_file: ******* starting __main__ section")
module1.output_hw()
module2.output_hw()
print("main_file: Main file done!")
Output:
So what’s happening here:
The main_file.py gets executed first and then imports module1 then module2
As part of importing module1, it executes all the code including the print statements in the root part of the code. Similarly for module2
Then the code returns to the main_file where it calls the functions under module1 and module2.
Please note, that both module1 and module2 have the same function name of output_hw(). This is perfectly fine as the scope of the function is in different modules.
One additional item to note, is that the module2 also imports module1. However, the print statement in the root section print("module1: I'm in module 1 root section") did not get executed the second time. Why? Python only imports a given module once.
Now let’s make a slight change – let’s remove the references to module1 in the main_file, and in module2, import module1!
Now import module1 from module2
The updated code looks like this:
#module1.py
print("module1: I'm in module 1 root section")
def output_hw():
print("module1: Hello world - output_hw 1")
#module2.py
import module1
print("module2: I'm in root section of module 2")
def output_hw():
print("module2: Hello world - output_hw 2")
#main_file.py
print("main_file: starting code")
# import module1
import module2
print("main_file: I'm in the root section ")
if __name__ == '__main__':
print("main_file: ******* starting __main__ section")
module2.output_hw()
# module2.output_hw()
print("main_file: Main file done!")
Output:
Now notice that module1 gets imported and executed from module2. Notice that the first line is “module1: I’m in module 1 root section” since the very first line of module2 is to import module1!
How do you make a package in your python project
To create a package it’s fairly straightforward. You simply need to move all your files into a directory and then create a file called __init__.py.
This means your directory structure looks like this:
#module1.py
print("module1: I'm in module 1 root section")
def output_hw():
print("module1: Hello world - output_hw 1")
#module2.py
import package1.module1
print("module2: I'm in root section of module 2")
def output_hw():
print("module2: Hello world - output_hw 2")
#main_file.py
print("main_file: starting code")
import package
print("main_file: I'm in the root section ")
if __name__ == '__main__':
print("main_file: ******* starting __main__ section")
package1.module1.output_hw()
package1.module2.output_hw()
print("main_file: Main file done!")
So in the __init__.py file, it imports module1 & module2. The reason this is important is because so that when in main_file the package1 is imported, then it will have immediate access to module1 and module2. This is why the package1.module1 and package1.module2 works.
You cannot make the inclusion of modules automatic, and generally you shouldn’t as you may have name clashes which you can avoid if you do this manually.
Can you avoid typing the prefix of “package1” each time? Yes in fact if you use the “from”. See next section.
Only Import a part of a module
You can also import just either a class or a function of a given module if you prefer in order to limit what is accessible in your local code. However, it does still execute your whole module though. It is more a means to make your code much more readable. See the following example:
#module1.py
print("module1: I'm in module 1 root section")
def output_hw():
print("module1: Hello world - output_hw 1")
#main_file.py
print("main_file: starting code")
from module1 import output_hw
print("main_file: I'm in the root section ")
if __name__ == '__main__':
print("main_file: ******* starting __main__ section")
output_hw()
print("main_file: Main file done!")
Output
As can be seen in the above output, although just the output_hw() function is being imported, the statement “module1: Im in module1 root section” was still executed.
Note also, that you do not need to mention the module prefix in the code, you can just refer to the function as is.
So back to above, for the packages, instead of the following:
import package1.module1
you can instead use the “from” keyword but force to check local directory:
from .module1 import *
There’s a few things going on here. The '.' in front of module1 is referring to the current directory. If you wanted to check the parent directory then you can use two '.'s so the line looks like this: from ..module1 import *. The second item is that everything is being imported with the import * section.
Importing a module and applying an alias
In case you wanted to make your code easier to read, or you wanted to avoid any name clashes (see at the start of the article how module1 and module2 both had the same function name of output_hw() ), you can use the “as” keyword at the import statement to give an alternative name.
You can do the following:
#main_file.py
print("main_file: starting code")
from module1 import output_hw as module1__output_hw
print("main_file: I'm in the root section ")
if __name__ == '__main__':
print("main_file: ******* starting __main__ section")
module1__output_hw()
print("main_file: Main file done!")
This can also be done with the module or package name as well, i.e.
import module1 as mod1
Importing modules outside your project folder
Modules can by default be imported from the sub-directories up to the main script file. So the following works:
To resolve this, you can in fact tell python where to look. Python keeps track of all the directories to search for modules under sys.path folder. Hence, the solution is to add an entry for the parent directory. Namely:
import sys
sys.path.append("..")
So the full code looks like the following:
#main_file.py
import sys
sys.path.append("..")
print("main_file: starting code")
import package1
print("main_file: I'm in the root section ")
if __name__ == '__main__':
print("main_file: ******* starting __main__ section")
package1.module1.output_hw()
print("main_file: Main file done!")
#module1.py
from package2.pkg2_mod_a import get_main_list
from server_key import get_server_master_key
def output_hw():
print("module1: List from pkg2 module A:" + str( get_main_list()) )
print("module1: server key :" + get_server_master_key() )
All of the above is when you know exactly what the module name to import. However, what if you don’t know the module name until runtime?
This is where you can use the __import__ and the getattr functions to achieve this.
Firstly the getattr(). This function is used to in fact load an object dynamically where you can specify the object name in a string, or provide a default.
Secondly, the __import__() can be used to provide a module name as a string.
When you combine the two together, you first load the module with __import__, and then use getattr to load the actual function you want to call or class you want to load from the import.
#module1.py
def output_hw():
print("module1: take me to a funky town")
#main_file.py
if __name__ == '__main__':
print("main_file: ******* starting __main__ section")
module = __import__( 'package1.module1')
func = getattr( module, 'output_hw', None)
if func:
func()
print("main_file: Main file done!")
In the above code, we first load the module called “package1.module1” which only loads the module. Then the getattr is called on the module and then the function is passed as a string. You can also pass in a class name if you wish.
Conclusion
There are many ways to import files and to organize your projects into smaller chunks. The most difficult piece is to decide what parts of your code go where..
Get notified automatically of new articles
We are always here to help provide useful articles with usable ode snippets. Sign up to our newsletter and receive articles in your inbox automatically so you won’t miss out on the next useful tips.
You ask an LLM to extract a user’s name, age, and email from a paragraph of text. Sometimes it returns clean JSON. Sometimes it returns JSON wrapped in markdown fences. Sometimes it returns a paragraph explaining why it extracted those fields. If you have ever built a pipeline that breaks because the model decided today was a good day to add “Sure! Here is the extracted data:” before the JSON, you already understand why instructor exists.
The instructor library patches the OpenAI client (and any OpenAI-compatible API) to force the model to return a fully validated Pydantic model — every time. When validation fails, it retries automatically. You define exactly what fields you need, with their types and constraints, and instructor handles the conversation with the model until the output matches your schema. You need Python 3.9+, an OpenAI API key (or compatible endpoint), and pip install instructor.
This article walks through everything you need to get structured LLM outputs in production: installing and patching the client, defining Pydantic schemas, extracting nested objects, handling lists, using validation hooks, working with non-OpenAI models via LiteLLM, and building a real extraction pipeline. By the end you will have a reusable pattern for reliable structured data from any LLM.
Structured LLM Output: Quick Example
The fastest way to see instructor in action is to extract a structured object from a single sentence. Install the library and try this:
# quick_instructor.py
import instructor
from openai import OpenAI
from pydantic import BaseModel
client = instructor.from_openai(OpenAI())
class Person(BaseModel):
name: str
age: int
city: str
person = client.chat.completions.create(
model="gpt-4o-mini",
response_model=Person,
messages=[{"role": "user", "content": "Alice is 32 years old and lives in Melbourne."}]
)
print(person.name) # Alice
print(person.age) # 32
print(person.city) # Melbourne
print(type(person)) # <class '__main__.Person'>
Output:
Alice
32
Melbourne
<class '__main__.Person'>
The key line is instructor.from_openai(OpenAI()) — this patches the standard OpenAI client. After that, you pass response_model=Person to any chat.completions.create call, and instructor automatically: sends the Pydantic schema to the model as a tool definition, parses the model’s tool-call response, validates it against your schema, and retries if validation fails. The return value is a fully typed Pydantic object, not a string or dict.
That example covers the simplest case. The sections below show how to handle nested models, lists, validation rules, retry configuration, and real-world pipelines.
response_model= and the chaos becomes a schema.
What Is instructor and Why Use It?
When you call an LLM without constraints, it returns free-form text. Parsing that text into structured data is fragile — you write regex, JSON parsers, and fallback handlers that break every time the model changes its wording. instructor solves this by using OpenAI’s function/tool calling feature under the hood: it converts your Pydantic model into a JSON Schema tool definition, forces the model to call that tool, and validates the returned arguments against your schema.
The result is LLM output that behaves like a typed function return value instead of a string you have to parse. If the model returns a field with the wrong type (for example, age as a string “thirty-two” instead of an integer), instructor sends the validation error back to the model and asks it to try again — up to a configurable number of retries.
Approach
Reliability
Type Safety
Auto-Retry
Parse raw LLM text
Fragile
None
Manual
Parse JSON from prompt
Moderate
Manual
Manual
OpenAI function calling
Good
Partial
None
instructor + Pydantic
High
Full
Built-in
The library supports multiple backends: instructor.from_openai, instructor.from_anthropic, instructor.from_gemini, and any OpenAI-compatible endpoint via base_url. This makes it the same interface regardless of which model you use.
Installation and Setup
Install instructor and the OpenAI SDK together. If you are using a different provider, you may also need their SDK:
# Terminal
pip install instructor openai pydantic
Set your API key as an environment variable so it never appears in your code:
# setup_env.py -- run once, or add to your shell profile
import os
# In practice, set this in your shell:
# export OPENAI_API_KEY="sk-..."
print("OPENAI_API_KEY set:", bool(os.environ.get("OPENAI_API_KEY")))
Output:
OPENAI_API_KEY set: True
Patch the client once at startup and reuse it for all calls. Creating a new patched client for every request is wasteful:
# client_setup.py
import instructor
from openai import OpenAI
# Patch once at startup
client = instructor.from_openai(OpenAI()) # reads OPENAI_API_KEY from env
# The client now has response_model support on all completion calls
print(type(client)) # <class 'instructor.client.Instructor'>
Output:
<class 'instructor.client.Instructor'>
One patch. Every completion call now speaks schema.
Defining Pydantic Schemas for Extraction
Your Pydantic model defines exactly what fields the LLM must return. Field descriptions improve accuracy significantly — the model uses them as instructions for what to put in each field. Use Field(description=...) to guide the extraction:
# schema_example.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import Optional
client = instructor.from_openai(OpenAI())
class JobPosting(BaseModel):
title: str = Field(description="The exact job title as written in the posting")
company: str = Field(description="Company name offering the position")
location: str = Field(description="City and country, or 'Remote'")
salary_min: Optional[int] = Field(None, description="Minimum annual salary in USD if mentioned")
salary_max: Optional[int] = Field(None, description="Maximum annual salary in USD if mentioned")
is_remote: bool = Field(description="True if the role allows remote work")
text = """
Senior Python Developer at DataFlow Inc. -- Remote (US timezones preferred).
Salary range: $140,000 - $175,000 per year. Must have 5+ years Python experience.
"""
job = client.chat.completions.create(
model="gpt-4o-mini",
response_model=JobPosting,
messages=[{"role": "user", "content": f"Extract the job details from: {text}"}]
)
print(f"Title: {job.title}")
print(f"Company: {job.company}")
print(f"Location: {job.location}")
print(f"Salary: ${job.salary_min:,} - ${job.salary_max:,}")
print(f"Remote: {job.is_remote}")
The Optional[int] type tells instructor (and the model) that salary fields may be absent. When the source text does not mention a salary, these fields will be None instead of hallucinated values. Always use Optional for fields that may not appear in the input — without it, the model will invent plausible-sounding values rather than leaving the field empty.
Extracting Nested and List Objects
Real-world extraction often requires nested structures — for example, an invoice with multiple line items, or a resume with a list of work experiences. instructor handles nested Pydantic models and List types natively:
# nested_extraction.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import List
client = instructor.from_openai(OpenAI())
class LineItem(BaseModel):
description: str
quantity: int
unit_price: float
class Invoice(BaseModel):
vendor: str
invoice_number: str
items: List[LineItem]
total: float
invoice_text = """
Invoice #INV-2024-0891 from CloudHost Solutions
- 3x Server instances @ $45.00 each
- 1x SSL Certificate @ $12.00
- 2x Domain registrations @ $15.00 each
Total: $222.00
"""
result = client.chat.completions.create(
model="gpt-4o-mini",
response_model=Invoice,
messages=[{"role": "user", "content": f"Extract invoice data: {invoice_text}"}]
)
print(f"Vendor: {result.vendor}")
print(f"Invoice #: {result.invoice_number}")
for item in result.items:
print(f" {item.quantity}x {item.description} @ ${item.unit_price:.2f}")
print(f"Total: ${result.total:.2f}")
Nested models work because instructor converts the entire schema — including nested classes — into a JSON Schema definition that the model understands. The model fills in every field of every nested object, and Pydantic validates the whole structure recursively. If the items list is missing or a line item has an invalid type, instructor retries the extraction with the validation error as feedback.
Nested Pydantic models: recursion that actually works.
Adding Custom Validation Rules
Pydantic’s field_validator lets you add business logic on top of type checking. instructor automatically feeds validation errors back to the model, so the model gets a second (or third) chance to return values that satisfy your rules:
# custom_validation.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field, field_validator
from typing import List
client = instructor.from_openai(OpenAI())
class ProductReview(BaseModel):
product_name: str
rating: int = Field(description="Rating from 1 to 5")
pros: List[str] = Field(description="List of positive aspects, at least one")
cons: List[str] = Field(description="List of negative aspects, can be empty")
summary: str = Field(description="One-sentence summary under 150 characters")
@field_validator("rating")
@classmethod
def rating_in_range(cls, v: int) -> int:
if not 1 <= v <= 5:
raise ValueError(f"Rating must be between 1 and 5, got {v}")
return v
@field_validator("pros")
@classmethod
def at_least_one_pro(cls, v: List[str]) -> List[str]:
if not v:
raise ValueError("Must include at least one positive aspect")
return v
@field_validator("summary")
@classmethod
def summary_length(cls, v: str) -> str:
if len(v) > 150:
raise ValueError(f"Summary too long: {len(v)} chars (max 150)")
return v
text = """
The new Python IDE is pretty solid. Boot time is fast, autocomplete works well.
The memory usage is high and the plugin store is still sparse. Overall a decent
choice for Python development. I'd give it 4 out of 5.
"""
review = client.chat.completions.create(
model="gpt-4o-mini",
response_model=ProductReview,
messages=[{"role": "user", "content": f"Extract review details: {text}"}]
)
print(f"Product: {review.product_name}")
print(f"Rating: {review.rating}/5")
print(f"Pros: {review.pros}")
print(f"Cons: {review.cons}")
print(f"Summary: {review.summary}")
Output:
Product: Python IDE
Rating: 4/5
Pros: ['Fast boot time', 'Good autocomplete']
Cons: ['High memory usage', 'Sparse plugin store']
Summary: A solid Python IDE with fast performance but limited plugins and high memory usage.
When a validator raises ValueError, instructor captures the error message and sends it back to the model in a follow-up message: “Validation failed: Rating must be between 1 and 5, got 6. Please fix and try again.” The model then self-corrects. By default, instructor retries up to 3 times before raising an exception. You can configure this with max_retries=N on the completion call.
Configuring Retries and Modes
instructor supports several extraction modes depending on what your model supports. The default mode uses OpenAI’s tool calling, but you can switch to JSON mode or other strategies:
# retry_config.py
import instructor
from instructor import Mode
from openai import OpenAI
from pydantic import BaseModel
# Default: tool calling (most reliable for OpenAI models)
client_tools = instructor.from_openai(OpenAI())
# JSON mode: model returns raw JSON instead of a tool call
client_json = instructor.from_openai(OpenAI(), mode=Mode.JSON)
# MD_JSON mode: model wraps JSON in markdown fences (useful for some fine-tunes)
client_md = instructor.from_openai(OpenAI(), mode=Mode.MD_JSON)
class City(BaseModel):
name: str
country: str
population: int
# Control retries per-call
city = client_tools.chat.completions.create(
model="gpt-4o-mini",
response_model=City,
max_retries=5, # retry up to 5 times on validation failure
messages=[{"role": "user", "content": "Tell me about Tokyo"}]
)
print(f"{city.name}, {city.country}: pop {city.population:,}")
Output:
Tokyo, Japan: pop 13,960,000
For most OpenAI models, the default tool-calling mode is most reliable. Use Mode.JSON for models that support JSON mode but not tool calling — for example, some fine-tuned models or older GPT versions. The max_retries parameter controls how many times instructor will re-prompt the model when validation fails. For production pipelines where data quality matters more than cost, set this to 3-5.
Three retries and a Pydantic error. That’s the whole self-correction system.
Using instructor with Non-OpenAI Models
If you are using Anthropic’s Claude, Google Gemini, or a local model via Ollama, instructor has provider-specific patches. For OpenAI-compatible endpoints (like local LLMs with an OpenAI-compatible API), you can pass a custom base_url:
# multi_provider.py
import instructor
from anthropic import Anthropic
from pydantic import BaseModel
# Anthropic Claude -- uses a different client class
anthropic_client = instructor.from_anthropic(Anthropic())
class Sentiment(BaseModel):
label: str # "positive", "negative", or "neutral"
score: float # confidence from 0.0 to 1.0
reason: str # one-sentence explanation
result = anthropic_client.messages.create(
model="claude-3-haiku-20240307",
max_tokens=256,
response_model=Sentiment,
messages=[{
"role": "user",
"content": "This new Python library is fantastic, saves me hours every week!"
}]
)
print(f"Sentiment: {result.label} ({result.score:.0%})")
print(f"Reason: {result.reason}")
Output:
Sentiment: positive (96%)
Reason: The user expresses strong enthusiasm and quantifies time savings, indicating genuine satisfaction.
For local models via Ollama (which provides an OpenAI-compatible API on localhost:11434), create the client with a custom base URL:
# ollama_instructor.py
import instructor
from openai import OpenAI
from pydantic import BaseModel
# Ollama runs an OpenAI-compatible server locally
ollama_client = instructor.from_openai(
OpenAI(base_url="http://localhost:11434/v1", api_key="ollama"),
mode=instructor.Mode.JSON # use JSON mode for local models
)
class Summary(BaseModel):
headline: str
key_points: list[str]
# Works the same as OpenAI -- just a different backend
# summary = ollama_client.chat.completions.create(
# model="llama3.2",
# response_model=Summary,
# messages=[{"role": "user", "content": "Summarize Python's async/await model"}]
# )
print("Local model client ready -- uncomment to use with Ollama running")
Output:
Local model client ready -- uncomment to use with Ollama running
Here is a complete pipeline that reads job postings from a list of texts, extracts structured data, filters by criteria, and exports to CSV — the kind of task that comes up in recruiting tools, market research, and job aggregators:
Structured extraction at scale: parsing 50 job posts is just a for loop.
# job_extraction_pipeline.py
import instructor
import csv
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import Optional, List
client = instructor.from_openai(OpenAI())
class JobPosting(BaseModel):
title: str = Field(description="Job title exactly as written")
company: str
location: str = Field(description="City/country or 'Remote'")
salary_min: Optional[int] = Field(None, description="Min annual salary USD")
salary_max: Optional[int] = Field(None, description="Max annual salary USD")
required_years: Optional[int] = Field(None, description="Years of experience required")
technologies: List[str] = Field(description="List of technologies mentioned")
is_remote: bool
# Sample job postings to process
JOB_TEXTS = [
"""Senior Python Engineer at Nexaflow -- Remote-first.
$150k-$190k. 5+ years Python, FastAPI, PostgreSQL, AWS required.""",
"""Junior Data Scientist at BioMetrics Ltd (London, UK).
GBP 45,000-55,000. 0-2 years exp, pandas, scikit-learn, matplotlib.""",
"""Staff ML Engineer at Quantra -- San Francisco CA.
$220,000 - $280,000/yr. 8+ years, PyTorch, CUDA, distributed training.""",
]
def extract_jobs(texts: List[str]) -> List[JobPosting]:
"""Extract structured job data from raw posting texts."""
jobs = []
for i, text in enumerate(texts, 1):
job = client.chat.completions.create(
model="gpt-4o-mini",
response_model=JobPosting,
max_retries=3,
messages=[{"role": "user", "content": f"Extract job details:\n\n{text}"}]
)
jobs.append(job)
print(f"[{i}/{len(texts)}] Extracted: {job.title} at {job.company}")
return jobs
def filter_remote(jobs: List[JobPosting]) -> List[JobPosting]:
return [j for j in jobs if j.is_remote]
def export_csv(jobs: List[JobPosting], path: str) -> None:
with open(path, "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(["Title", "Company", "Location", "Salary Min", "Salary Max",
"Yrs Required", "Technologies", "Remote"])
for j in jobs:
writer.writerow([
j.title, j.company, j.location,
j.salary_min or "", j.salary_max or "",
j.required_years or "",
", ".join(j.technologies),
j.is_remote
])
if __name__ == "__main__":
print("Extracting job postings...")
jobs = extract_jobs(JOB_TEXTS)
remote_jobs = filter_remote(jobs)
print(f"\nTotal extracted: {len(jobs)}, Remote: {len(remote_jobs)}")
export_csv(jobs, "jobs_extracted.csv")
print("Saved to jobs_extracted.csv")
Output:
Extracting job postings...
[1/3] Extracted: Senior Python Engineer at Nexaflow
[2/3] Extracted: Junior Data Scientist at BioMetrics Ltd
[3/3] Extracted: Staff ML Engineer at Quantra
Total extracted: 3, Remote: 1
Saved to jobs_extracted.csv
This pipeline is easy to extend: add a database write step, connect it to a web scraper that feeds real job pages, or add more validation rules to the JobPosting model. The core pattern — extract once, validate automatically, retry on failure — stays the same regardless of the scale. You can process thousands of postings by replacing JOB_TEXTS with a generator that reads from a queue or database, keeping the extraction logic identical.
Frequently Asked Questions
Does instructor increase API costs because of retries?
Yes, each retry is an additional API call, so failed extractions cost more. In practice, with well-designed schemas and clear field descriptions, validation failures are rare — under 5% for most extraction tasks. The cost increase is usually worth the reliability gain. If cost is a concern, use max_retries=1 and handle exceptions in your code rather than retrying automatically.
Does instructor support streaming responses?
Yes. Use response_model=Iterable[YourModel] for streaming lists, or Partial[YourModel] for streaming partial updates to a single model. Streaming is useful for large extractions where you want to process results as they arrive rather than waiting for the full response. See the instructor documentation for the streaming API details.
What happens when the model cannot extract a field?
If the field is typed as Optional[X], the model will return None for missing information. If the field is required (non-Optional), the model will either hallucinate a value or fail validation, triggering a retry. For fields that may legitimately be absent in the source text, always use Optional with a None default. This is the most common mistake new users make.
Can I extract data from large documents?
Yes, but be aware of token limits. For documents larger than a few thousand words, split them into chunks and extract from each chunk separately. Use a List[YourModel] return type if a single document contains multiple items to extract (like a list of transactions in a bank statement). For very large documents, consider summarizing first with a regular completion call, then extracting from the summary.
How is this different from just prompting for JSON output?
Prompting for JSON works until it does not — the model adds markdown fences, writes a preamble sentence, or omits fields. instructor uses tool calling (not prompting) to enforce the schema, so the model cannot deviate from the structure. It also runs Pydantic validation on the result and retries if types or constraints are violated. The difference in reliability for production use is significant — JSON prompting is fine for experiments, but instructor is the right tool for pipelines where data quality matters.
Is my data sent to OpenAI when I use instructor?
instructor is a thin wrapper around the OpenAI SDK — your data goes to whatever API endpoint you configure, subject to that provider’s data policy. If you are processing sensitive data, use a self-hosted model via Ollama or another local inference server, and point instructor at your local endpoint with a custom base_url. The library itself does not send data anywhere — it only wraps the client you provide.
Conclusion
The instructor library solves one of the most persistent frustrations in LLM application development: getting the model to return data in the shape your code expects, every time. We covered patching the OpenAI client, defining Pydantic schemas with field descriptions, extracting nested and list objects, adding custom validation rules, configuring retries and modes, and using instructor with non-OpenAI providers. The job extraction pipeline demonstrated how these pieces combine into a production-ready pattern.
The next step is to extend the real-life example: add a web scraper to pull live job postings, or connect the extracted data to a database. With instructor handling the model-to-schema translation, you can focus entirely on the business logic of what to extract and what to do with it.
Full documentation and more examples are at python.useinstructor.com. The library’s GitHub has a large collection of real-world examples including classification, knowledge graph extraction, and citation-backed answers.
What is the difference between absolute and relative imports in Python?
Absolute imports use the full package path from the project root (e.g., from mypackage.module import func). Relative imports use dots to reference the current package (e.g., from .module import func). Absolute imports are generally preferred for clarity.
What does __init__.py do in a Python package?
The __init__.py file marks a directory as a Python package, allowing its modules to be imported. It can be empty or contain initialization code, define __all__ for controlling wildcard imports, or re-export symbols for a cleaner public API.
How do I fix ‘ModuleNotFoundError’ in Python?
Check that the module is installed (pip install), verify your PYTHONPATH includes the right directories, ensure __init__.py files exist in package directories, and confirm you are using the correct Python environment. Running from the project root often resolves path issues.
What is the best project structure for a Python application?
A common structure includes a top-level project directory containing a src/ folder with your package, a tests/ folder, setup.py or pyproject.toml, and a requirements.txt. This keeps source code, tests, and configuration clearly separated.
Should I use relative or absolute imports?
PEP 8 recommends absolute imports for most cases because they are more readable and less error-prone. Use relative imports only within a package when the internal structure is unlikely to change and the import path would be excessively long with absolute imports.
Selenium is a useful python library to extract web page data especially for pages with javascript loading. Many of you may have tried to use selenium but may have gotten stuck in the installation process. One key thing you have to remember is that Selenium will run an actual browser in the background (or foreground if you wish) to query a given website. So a key step is to install the driver if you haven’t done so already.
Step 1: Locate the right web driver
Since Selenium will use an actual driver, one of the first decisions you’ll need to make is to determine which driver to use. Generally it won’t matter, but the best browser to use, is the one that works the best for your target website. For example, if your target website works best under Firefox, then use that.
So decide which one, and then go to the download page. For this example we will use FireFox. In the above table, the download link goes to this page: https://github.com/mozilla/geckodriver/releases
You can then click on the latest release:
First, click on the latest release
You can then scroll down to the bottom of the page to see the driver list:
Right click on the .gz file, and then get the URL.
Step 2: Download the web driver
Next go to your linux terminal and create a directory to store this file:
Next go into that directory, and then use wget to download the url by pasting the link you copied above:
Next you should see the .gz file when you list the files:
You can the gzip the file to extract it:
gzip -d geckodriver-v0.29.1-linux32.tar.gz
You can then finally untar the file to decompress:
tar -xvf geckodriver-v0.29.1-linux32.tar
Step 4: Configure PATH
What you will be left with is a file called “geckodriver”. This is the driver file. You will need to have it made available via the export path. The reason is that the selenium looks for the driver file from the PATH operating system environment variable.
I simply went to the parent directory, then updated the PATH environment variable by taking the existing PATH value ($PATH) then appending the gdriver folder:
export PATH=$PATH:gdriver
If you do not do the above, you will get the error:
selenium.common.exceptions.WebDriverException: Message: 'geckodriver' executable needs to be in PATH.
Step 5: Test running the web driver
That’s it! Now if you test the following code, you should be able to run a web query by running a firefox driver in the background:
# main.py
from selenium import webdriver
from selenium.webdriver import FirefoxOptions
opts = FirefoxOptions()
opts.add_argument("--headless")
browser = webdriver.Firefox(options=opts)
# Declare a variable containing the URL is going to be scrapped
URL = 'https://pythonhowtoprogram.com/'
# Web driver going into website
browser.get(URL)
# Printing page title
print(browser.title)
You will notice it does take a few seconds to run for the first time. It’s because that an instance of a browser needs to be loaded which does take a few seconds. Just keep this in mind in case you need to have faster performance for which you may need to use urllib or requests instead.
You ask an LLM to extract a user’s name, age, and email from a paragraph of text. Sometimes it returns clean JSON. Sometimes it returns JSON wrapped in markdown fences. Sometimes it returns a paragraph explaining why it extracted those fields. If you have ever built a pipeline that breaks because the model decided today was a good day to add “Sure! Here is the extracted data:” before the JSON, you already understand why instructor exists.
The instructor library patches the OpenAI client (and any OpenAI-compatible API) to force the model to return a fully validated Pydantic model — every time. When validation fails, it retries automatically. You define exactly what fields you need, with their types and constraints, and instructor handles the conversation with the model until the output matches your schema. You need Python 3.9+, an OpenAI API key (or compatible endpoint), and pip install instructor.
This article walks through everything you need to get structured LLM outputs in production: installing and patching the client, defining Pydantic schemas, extracting nested objects, handling lists, using validation hooks, working with non-OpenAI models via LiteLLM, and building a real extraction pipeline. By the end you will have a reusable pattern for reliable structured data from any LLM.
Structured LLM Output: Quick Example
The fastest way to see instructor in action is to extract a structured object from a single sentence. Install the library and try this:
# quick_instructor.py
import instructor
from openai import OpenAI
from pydantic import BaseModel
client = instructor.from_openai(OpenAI())
class Person(BaseModel):
name: str
age: int
city: str
person = client.chat.completions.create(
model="gpt-4o-mini",
response_model=Person,
messages=[{"role": "user", "content": "Alice is 32 years old and lives in Melbourne."}]
)
print(person.name) # Alice
print(person.age) # 32
print(person.city) # Melbourne
print(type(person)) # <class '__main__.Person'>
Output:
Alice
32
Melbourne
<class '__main__.Person'>
The key line is instructor.from_openai(OpenAI()) — this patches the standard OpenAI client. After that, you pass response_model=Person to any chat.completions.create call, and instructor automatically: sends the Pydantic schema to the model as a tool definition, parses the model’s tool-call response, validates it against your schema, and retries if validation fails. The return value is a fully typed Pydantic object, not a string or dict.
That example covers the simplest case. The sections below show how to handle nested models, lists, validation rules, retry configuration, and real-world pipelines.
response_model= and the chaos becomes a schema.
What Is instructor and Why Use It?
When you call an LLM without constraints, it returns free-form text. Parsing that text into structured data is fragile — you write regex, JSON parsers, and fallback handlers that break every time the model changes its wording. instructor solves this by using OpenAI’s function/tool calling feature under the hood: it converts your Pydantic model into a JSON Schema tool definition, forces the model to call that tool, and validates the returned arguments against your schema.
The result is LLM output that behaves like a typed function return value instead of a string you have to parse. If the model returns a field with the wrong type (for example, age as a string “thirty-two” instead of an integer), instructor sends the validation error back to the model and asks it to try again — up to a configurable number of retries.
Approach
Reliability
Type Safety
Auto-Retry
Parse raw LLM text
Fragile
None
Manual
Parse JSON from prompt
Moderate
Manual
Manual
OpenAI function calling
Good
Partial
None
instructor + Pydantic
High
Full
Built-in
The library supports multiple backends: instructor.from_openai, instructor.from_anthropic, instructor.from_gemini, and any OpenAI-compatible endpoint via base_url. This makes it the same interface regardless of which model you use.
Installation and Setup
Install instructor and the OpenAI SDK together. If you are using a different provider, you may also need their SDK:
# Terminal
pip install instructor openai pydantic
Set your API key as an environment variable so it never appears in your code:
# setup_env.py -- run once, or add to your shell profile
import os
# In practice, set this in your shell:
# export OPENAI_API_KEY="sk-..."
print("OPENAI_API_KEY set:", bool(os.environ.get("OPENAI_API_KEY")))
Output:
OPENAI_API_KEY set: True
Patch the client once at startup and reuse it for all calls. Creating a new patched client for every request is wasteful:
# client_setup.py
import instructor
from openai import OpenAI
# Patch once at startup
client = instructor.from_openai(OpenAI()) # reads OPENAI_API_KEY from env
# The client now has response_model support on all completion calls
print(type(client)) # <class 'instructor.client.Instructor'>
Output:
<class 'instructor.client.Instructor'>
One patch. Every completion call now speaks schema.
Defining Pydantic Schemas for Extraction
Your Pydantic model defines exactly what fields the LLM must return. Field descriptions improve accuracy significantly — the model uses them as instructions for what to put in each field. Use Field(description=...) to guide the extraction:
# schema_example.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import Optional
client = instructor.from_openai(OpenAI())
class JobPosting(BaseModel):
title: str = Field(description="The exact job title as written in the posting")
company: str = Field(description="Company name offering the position")
location: str = Field(description="City and country, or 'Remote'")
salary_min: Optional[int] = Field(None, description="Minimum annual salary in USD if mentioned")
salary_max: Optional[int] = Field(None, description="Maximum annual salary in USD if mentioned")
is_remote: bool = Field(description="True if the role allows remote work")
text = """
Senior Python Developer at DataFlow Inc. -- Remote (US timezones preferred).
Salary range: $140,000 - $175,000 per year. Must have 5+ years Python experience.
"""
job = client.chat.completions.create(
model="gpt-4o-mini",
response_model=JobPosting,
messages=[{"role": "user", "content": f"Extract the job details from: {text}"}]
)
print(f"Title: {job.title}")
print(f"Company: {job.company}")
print(f"Location: {job.location}")
print(f"Salary: ${job.salary_min:,} - ${job.salary_max:,}")
print(f"Remote: {job.is_remote}")
The Optional[int] type tells instructor (and the model) that salary fields may be absent. When the source text does not mention a salary, these fields will be None instead of hallucinated values. Always use Optional for fields that may not appear in the input — without it, the model will invent plausible-sounding values rather than leaving the field empty.
Extracting Nested and List Objects
Real-world extraction often requires nested structures — for example, an invoice with multiple line items, or a resume with a list of work experiences. instructor handles nested Pydantic models and List types natively:
# nested_extraction.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import List
client = instructor.from_openai(OpenAI())
class LineItem(BaseModel):
description: str
quantity: int
unit_price: float
class Invoice(BaseModel):
vendor: str
invoice_number: str
items: List[LineItem]
total: float
invoice_text = """
Invoice #INV-2024-0891 from CloudHost Solutions
- 3x Server instances @ $45.00 each
- 1x SSL Certificate @ $12.00
- 2x Domain registrations @ $15.00 each
Total: $222.00
"""
result = client.chat.completions.create(
model="gpt-4o-mini",
response_model=Invoice,
messages=[{"role": "user", "content": f"Extract invoice data: {invoice_text}"}]
)
print(f"Vendor: {result.vendor}")
print(f"Invoice #: {result.invoice_number}")
for item in result.items:
print(f" {item.quantity}x {item.description} @ ${item.unit_price:.2f}")
print(f"Total: ${result.total:.2f}")
Nested models work because instructor converts the entire schema — including nested classes — into a JSON Schema definition that the model understands. The model fills in every field of every nested object, and Pydantic validates the whole structure recursively. If the items list is missing or a line item has an invalid type, instructor retries the extraction with the validation error as feedback.
Nested Pydantic models: recursion that actually works.
Adding Custom Validation Rules
Pydantic’s field_validator lets you add business logic on top of type checking. instructor automatically feeds validation errors back to the model, so the model gets a second (or third) chance to return values that satisfy your rules:
# custom_validation.py
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field, field_validator
from typing import List
client = instructor.from_openai(OpenAI())
class ProductReview(BaseModel):
product_name: str
rating: int = Field(description="Rating from 1 to 5")
pros: List[str] = Field(description="List of positive aspects, at least one")
cons: List[str] = Field(description="List of negative aspects, can be empty")
summary: str = Field(description="One-sentence summary under 150 characters")
@field_validator("rating")
@classmethod
def rating_in_range(cls, v: int) -> int:
if not 1 <= v <= 5:
raise ValueError(f"Rating must be between 1 and 5, got {v}")
return v
@field_validator("pros")
@classmethod
def at_least_one_pro(cls, v: List[str]) -> List[str]:
if not v:
raise ValueError("Must include at least one positive aspect")
return v
@field_validator("summary")
@classmethod
def summary_length(cls, v: str) -> str:
if len(v) > 150:
raise ValueError(f"Summary too long: {len(v)} chars (max 150)")
return v
text = """
The new Python IDE is pretty solid. Boot time is fast, autocomplete works well.
The memory usage is high and the plugin store is still sparse. Overall a decent
choice for Python development. I'd give it 4 out of 5.
"""
review = client.chat.completions.create(
model="gpt-4o-mini",
response_model=ProductReview,
messages=[{"role": "user", "content": f"Extract review details: {text}"}]
)
print(f"Product: {review.product_name}")
print(f"Rating: {review.rating}/5")
print(f"Pros: {review.pros}")
print(f"Cons: {review.cons}")
print(f"Summary: {review.summary}")
Output:
Product: Python IDE
Rating: 4/5
Pros: ['Fast boot time', 'Good autocomplete']
Cons: ['High memory usage', 'Sparse plugin store']
Summary: A solid Python IDE with fast performance but limited plugins and high memory usage.
When a validator raises ValueError, instructor captures the error message and sends it back to the model in a follow-up message: “Validation failed: Rating must be between 1 and 5, got 6. Please fix and try again.” The model then self-corrects. By default, instructor retries up to 3 times before raising an exception. You can configure this with max_retries=N on the completion call.
Configuring Retries and Modes
instructor supports several extraction modes depending on what your model supports. The default mode uses OpenAI’s tool calling, but you can switch to JSON mode or other strategies:
# retry_config.py
import instructor
from instructor import Mode
from openai import OpenAI
from pydantic import BaseModel
# Default: tool calling (most reliable for OpenAI models)
client_tools = instructor.from_openai(OpenAI())
# JSON mode: model returns raw JSON instead of a tool call
client_json = instructor.from_openai(OpenAI(), mode=Mode.JSON)
# MD_JSON mode: model wraps JSON in markdown fences (useful for some fine-tunes)
client_md = instructor.from_openai(OpenAI(), mode=Mode.MD_JSON)
class City(BaseModel):
name: str
country: str
population: int
# Control retries per-call
city = client_tools.chat.completions.create(
model="gpt-4o-mini",
response_model=City,
max_retries=5, # retry up to 5 times on validation failure
messages=[{"role": "user", "content": "Tell me about Tokyo"}]
)
print(f"{city.name}, {city.country}: pop {city.population:,}")
Output:
Tokyo, Japan: pop 13,960,000
For most OpenAI models, the default tool-calling mode is most reliable. Use Mode.JSON for models that support JSON mode but not tool calling — for example, some fine-tuned models or older GPT versions. The max_retries parameter controls how many times instructor will re-prompt the model when validation fails. For production pipelines where data quality matters more than cost, set this to 3-5.
Three retries and a Pydantic error. That’s the whole self-correction system.
Using instructor with Non-OpenAI Models
If you are using Anthropic’s Claude, Google Gemini, or a local model via Ollama, instructor has provider-specific patches. For OpenAI-compatible endpoints (like local LLMs with an OpenAI-compatible API), you can pass a custom base_url:
# multi_provider.py
import instructor
from anthropic import Anthropic
from pydantic import BaseModel
# Anthropic Claude -- uses a different client class
anthropic_client = instructor.from_anthropic(Anthropic())
class Sentiment(BaseModel):
label: str # "positive", "negative", or "neutral"
score: float # confidence from 0.0 to 1.0
reason: str # one-sentence explanation
result = anthropic_client.messages.create(
model="claude-3-haiku-20240307",
max_tokens=256,
response_model=Sentiment,
messages=[{
"role": "user",
"content": "This new Python library is fantastic, saves me hours every week!"
}]
)
print(f"Sentiment: {result.label} ({result.score:.0%})")
print(f"Reason: {result.reason}")
Output:
Sentiment: positive (96%)
Reason: The user expresses strong enthusiasm and quantifies time savings, indicating genuine satisfaction.
For local models via Ollama (which provides an OpenAI-compatible API on localhost:11434), create the client with a custom base URL:
# ollama_instructor.py
import instructor
from openai import OpenAI
from pydantic import BaseModel
# Ollama runs an OpenAI-compatible server locally
ollama_client = instructor.from_openai(
OpenAI(base_url="http://localhost:11434/v1", api_key="ollama"),
mode=instructor.Mode.JSON # use JSON mode for local models
)
class Summary(BaseModel):
headline: str
key_points: list[str]
# Works the same as OpenAI -- just a different backend
# summary = ollama_client.chat.completions.create(
# model="llama3.2",
# response_model=Summary,
# messages=[{"role": "user", "content": "Summarize Python's async/await model"}]
# )
print("Local model client ready -- uncomment to use with Ollama running")
Output:
Local model client ready -- uncomment to use with Ollama running
Here is a complete pipeline that reads job postings from a list of texts, extracts structured data, filters by criteria, and exports to CSV — the kind of task that comes up in recruiting tools, market research, and job aggregators:
Structured extraction at scale: parsing 50 job posts is just a for loop.
# job_extraction_pipeline.py
import instructor
import csv
from openai import OpenAI
from pydantic import BaseModel, Field
from typing import Optional, List
client = instructor.from_openai(OpenAI())
class JobPosting(BaseModel):
title: str = Field(description="Job title exactly as written")
company: str
location: str = Field(description="City/country or 'Remote'")
salary_min: Optional[int] = Field(None, description="Min annual salary USD")
salary_max: Optional[int] = Field(None, description="Max annual salary USD")
required_years: Optional[int] = Field(None, description="Years of experience required")
technologies: List[str] = Field(description="List of technologies mentioned")
is_remote: bool
# Sample job postings to process
JOB_TEXTS = [
"""Senior Python Engineer at Nexaflow -- Remote-first.
$150k-$190k. 5+ years Python, FastAPI, PostgreSQL, AWS required.""",
"""Junior Data Scientist at BioMetrics Ltd (London, UK).
GBP 45,000-55,000. 0-2 years exp, pandas, scikit-learn, matplotlib.""",
"""Staff ML Engineer at Quantra -- San Francisco CA.
$220,000 - $280,000/yr. 8+ years, PyTorch, CUDA, distributed training.""",
]
def extract_jobs(texts: List[str]) -> List[JobPosting]:
"""Extract structured job data from raw posting texts."""
jobs = []
for i, text in enumerate(texts, 1):
job = client.chat.completions.create(
model="gpt-4o-mini",
response_model=JobPosting,
max_retries=3,
messages=[{"role": "user", "content": f"Extract job details:\n\n{text}"}]
)
jobs.append(job)
print(f"[{i}/{len(texts)}] Extracted: {job.title} at {job.company}")
return jobs
def filter_remote(jobs: List[JobPosting]) -> List[JobPosting]:
return [j for j in jobs if j.is_remote]
def export_csv(jobs: List[JobPosting], path: str) -> None:
with open(path, "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(["Title", "Company", "Location", "Salary Min", "Salary Max",
"Yrs Required", "Technologies", "Remote"])
for j in jobs:
writer.writerow([
j.title, j.company, j.location,
j.salary_min or "", j.salary_max or "",
j.required_years or "",
", ".join(j.technologies),
j.is_remote
])
if __name__ == "__main__":
print("Extracting job postings...")
jobs = extract_jobs(JOB_TEXTS)
remote_jobs = filter_remote(jobs)
print(f"\nTotal extracted: {len(jobs)}, Remote: {len(remote_jobs)}")
export_csv(jobs, "jobs_extracted.csv")
print("Saved to jobs_extracted.csv")
Output:
Extracting job postings...
[1/3] Extracted: Senior Python Engineer at Nexaflow
[2/3] Extracted: Junior Data Scientist at BioMetrics Ltd
[3/3] Extracted: Staff ML Engineer at Quantra
Total extracted: 3, Remote: 1
Saved to jobs_extracted.csv
This pipeline is easy to extend: add a database write step, connect it to a web scraper that feeds real job pages, or add more validation rules to the JobPosting model. The core pattern — extract once, validate automatically, retry on failure — stays the same regardless of the scale. You can process thousands of postings by replacing JOB_TEXTS with a generator that reads from a queue or database, keeping the extraction logic identical.
Frequently Asked Questions
Does instructor increase API costs because of retries?
Yes, each retry is an additional API call, so failed extractions cost more. In practice, with well-designed schemas and clear field descriptions, validation failures are rare — under 5% for most extraction tasks. The cost increase is usually worth the reliability gain. If cost is a concern, use max_retries=1 and handle exceptions in your code rather than retrying automatically.
Does instructor support streaming responses?
Yes. Use response_model=Iterable[YourModel] for streaming lists, or Partial[YourModel] for streaming partial updates to a single model. Streaming is useful for large extractions where you want to process results as they arrive rather than waiting for the full response. See the instructor documentation for the streaming API details.
What happens when the model cannot extract a field?
If the field is typed as Optional[X], the model will return None for missing information. If the field is required (non-Optional), the model will either hallucinate a value or fail validation, triggering a retry. For fields that may legitimately be absent in the source text, always use Optional with a None default. This is the most common mistake new users make.
Can I extract data from large documents?
Yes, but be aware of token limits. For documents larger than a few thousand words, split them into chunks and extract from each chunk separately. Use a List[YourModel] return type if a single document contains multiple items to extract (like a list of transactions in a bank statement). For very large documents, consider summarizing first with a regular completion call, then extracting from the summary.
How is this different from just prompting for JSON output?
Prompting for JSON works until it does not — the model adds markdown fences, writes a preamble sentence, or omits fields. instructor uses tool calling (not prompting) to enforce the schema, so the model cannot deviate from the structure. It also runs Pydantic validation on the result and retries if types or constraints are violated. The difference in reliability for production use is significant — JSON prompting is fine for experiments, but instructor is the right tool for pipelines where data quality matters.
Is my data sent to OpenAI when I use instructor?
instructor is a thin wrapper around the OpenAI SDK — your data goes to whatever API endpoint you configure, subject to that provider’s data policy. If you are processing sensitive data, use a self-hosted model via Ollama or another local inference server, and point instructor at your local endpoint with a custom base_url. The library itself does not send data anywhere — it only wraps the client you provide.
Conclusion
The instructor library solves one of the most persistent frustrations in LLM application development: getting the model to return data in the shape your code expects, every time. We covered patching the OpenAI client, defining Pydantic schemas with field descriptions, extracting nested and list objects, adding custom validation rules, configuring retries and modes, and using instructor with non-OpenAI providers. The job extraction pipeline demonstrated how these pieces combine into a production-ready pattern.
The next step is to extend the real-life example: add a web scraper to pull live job postings, or connect the extracted data to a database. With instructor handling the model-to-schema translation, you can focus entirely on the business logic of what to extract and what to do with it.
Full documentation and more examples are at python.useinstructor.com. The library’s GitHub has a large collection of real-world examples including classification, knowledge graph extraction, and citation-backed answers.
Selenium WebDriver is a tool for automating web browser interactions. In Python, it is used for web scraping, automated testing of web applications, form filling, screenshot capture, and any task that requires programmatic control of a web browser.
Which browser drivers work with Selenium in Python?
Selenium supports ChromeDriver (Chrome/Chromium), GeckoDriver (Firefox), EdgeDriver (Microsoft Edge), and SafariDriver (Safari). ChromeDriver and GeckoDriver are the most commonly used for Linux-based automation.
How do I install ChromeDriver on Linux?
Download ChromeDriver from the official site matching your Chrome version, extract it, and place it in your PATH (e.g., /usr/local/bin/). Alternatively, use webdriver-manager package: pip install webdriver-manager to handle driver installation automatically.
Why do I get ‘WebDriver not found’ errors?
This typically occurs when the driver executable is not in your system PATH, the driver version does not match your browser version, or the driver file lacks execute permissions. Use chmod +x chromedriver to set permissions and ensure version compatibility.
Can Selenium run without a visible browser window?
Yes. Use headless mode by adding options.add_argument('--headless') to your browser options. This runs the browser in the background without a GUI, which is faster and ideal for servers and CI/CD pipelines.
Installing the Right Driver Binary
Selenium needs a browser-specific driver binary on the system PATH or pointed to explicitly. The two paths that work on Linux:
Option 1 — Selenium Manager (Selenium 4.6+): The library auto-downloads the right driver. Zero setup beyond installing selenium:
Option 2 — webdriver-manager: Explicit installation per session, handy when you need to pin a version:
# pip install webdriver-manager
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
Headless Mode for Servers
On a server with no display, you need headless mode (and matching Chrome / Chromium installed). The minimal Chrome install on Ubuntu 22.04 and Debian:
# Install Chrome and the libraries it needs
sudo apt-get update
sudo apt-get install -y wget gnupg
wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | sudo apt-key add -
echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main" | \
sudo tee /etc/apt/sources.list.d/google-chrome.list
sudo apt-get update
sudo apt-get install -y google-chrome-stable
# Python: enable headless
from selenium.webdriver.chrome.options import Options
opts = Options()
opts.add_argument("--headless=new") # use the new headless mode (Chrome 109+)
opts.add_argument("--no-sandbox") # required when running as root
opts.add_argument("--disable-dev-shm-usage") # avoid /dev/shm size issues
opts.add_argument("--window-size=1920,1080") # avoid layout-dependent failures
driver = webdriver.Chrome(options=opts)
The --disable-dev-shm-usage flag fixes a notorious crash in Docker containers where the shared-memory partition is too small. --no-sandbox is required when Chrome runs as root (Docker default).
Firefox / geckodriver
If Chrome isn’t your target, swap in Firefox. Same pattern, different driver:
sudo apt-get install -y firefox
# Python
from selenium import webdriver
from selenium.webdriver.firefox.options import Options as FFOptions
from selenium.webdriver.firefox.service import Service as FFService
from webdriver_manager.firefox import GeckoDriverManager
opts = FFOptions()
opts.add_argument("--headless")
service = FFService(GeckoDriverManager().install())
driver = webdriver.Firefox(service=service, options=opts)
driver.get("https://example.com")
Docker Setup for Selenium
For CI / production, run Selenium in Docker rather than installing system-wide. The official Selenium images have everything bundled:
# Pull a ready-to-go Chrome stack
docker run -d -p 4444:4444 -p 7900:7900 --shm-size=2g \
selenium/standalone-chrome:latest
# Now connect from any host (no local Chrome needed)
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
opts = Options()
opts.add_argument("--headless=new")
driver = webdriver.Remote(
command_executor="http://localhost:4444/wd/hub",
options=opts,
)
driver.get("https://example.com")
The --shm-size=2g on the container fixes the same shared-memory issue as --disable-dev-shm-usage in the Chrome args. Pick whichever is convenient.
Verifying Your Setup
A 6-line smoke test catches 90% of install failures:
If this runs and prints “Welcome to Python.org” — you’re done. If it fails, the error message tells you exactly what’s missing (driver, browser binary, sandbox flag, etc.).
Common Pitfalls
Mixing Chrome and chromedriver versions. chromedriver must match Chrome’s major version. Selenium Manager handles this; webdriver-manager handles it; manual installs break every Chrome update.
Forgetting –no-sandbox in Docker. Chrome refuses to run as root (which Docker default is) without it. Add it OR run as a non-root user.
Insufficient /dev/shm. Default 64MB shared memory in Docker isn’t enough. Use --shm-size=2g or --disable-dev-shm-usage.
Missing browser binary. chromedriver alone isn’t enough — you also need Chrome itself installed. Same for Firefox + geckodriver.
Old –headless flag. Chrome’s old headless mode is deprecated in favor of --headless=new (Chrome 109+). The new mode is faster and renders more accurately.
FAQ
Q: Selenium or Playwright?
A: For new projects, Playwright is faster, has better selectors, and auto-handles waits. Selenium is mature and ubiquitous — if you have existing Selenium tests or need browser support beyond Chrome/Firefox/WebKit, stick with it.
Q: Headless or headful?
A: Headless for CI, scrapers, and any unattended workflow. Headful when developing — you can SEE what your code is doing, which speeds debugging by 10x.
Q: How do I run as a specific browser version?
A: Install that specific version of Chrome / Firefox, then point Selenium at it: options.binary_location = "/path/to/chrome". webdriver-manager can also pin to a version.
Q: Why is the test slow on the first run?
A: The driver download. Subsequent runs use the cached binary. CI systems should cache ~/.wdm (webdriver-manager) and ~/.cache/selenium.
Q: How do I bypass Cloudflare / bot protection?
A: Standard Selenium gets blocked by Cloudflare. Use undetected-chromedriver (better) or Playwright with stealth plugins (best). For aggressive bot detection, you may need to rotate user agents and use residential proxies.
Wrapping Up
Selenium on Linux comes down to three pieces: Python’s selenium package, the browser binary (Chrome or Firefox), and the driver binary (chromedriver or geckodriver). Selenium Manager handles the driver auto-download. --headless=new, --no-sandbox, and --disable-dev-shm-usage are the three flags that make Chrome work reliably in Docker. Get that combination right and Selenium runs cleanly in CI, on servers, and in production scrapers.