Most developers today realize that their iOS devices can also handle leading coding apps. Even though they’re not as useful as their desktop equivalents, some capable mobile IDEs work as supplementary IDEs to iOS devices.
The new wave of technological advancements and Safari browser improvements on iPadOS make coding easier by using the best code editor for iOS.
Why Code on iOS?
Before we go ahead learning about what are the best code editors, let’s check out why code on an iOS. The main reason is convenience. iOS devices, especially iPad, are lighter and smaller than bulky desktops and laptops. They are highly portable.
Alongside other work, such as watching movies and checking email, writing code on iOS makes life easier. According to setapp.com, there are several effective Notepad++ alternatives available that allow you to Edit code on iOS devices.
Let’s take a look at the best code-editing apps available for iPhones and iPads.
Textastic
This is one of the best text editors for iPad, iPhone, and Mac for some good reasons. It provides rich support for syntax highlighting for 80+ programming and markup languages. Also, it is compatible with TextMate syntax themes and definitions.
Typing characters for programming becomes easier using the Display additional keys available over the virtual keyboard. You can get files through SFTP, FTP, WebDAV, Google Drive, and Dropbox. The excellent first screen makes it clear where to begin.
Koder
Featuring iTunes file-sharing support, Koder is another recommended code editor for iOS – iPhone and iPad. Using this editor, you can code easily at any time and anywhere, no matter whether you’re traveling or at a desk.
Just like Textastic, Koder also supports WebDAV, SFTP, FTP, Google Drive, and Dropbox file access. It comes with multiple features such as snippet manager, syntax highlighting, editor theme, tabbed editing, and more.
Pythonista 3
As the name depicts, Pythonista 3 primarily focuses on Python. It is an ideal coding app for Python coders as it supports entire Python coding for iPhones and iPad. You will get numerous color themes, a custom keyboard, and a snippet system for quick coding.
When coding with this editor, you can gain access to desktop-level features. For example, outline view, syntax highlighting, support for several tabs, and code completion. Using powerful interactive prompts, you can try snippets of code in ad-hoc calculations.
Swift Playgrounds
This is the ultimate coding app for experienced developers and Apple’s programming language beginners. It was started by Apple to make the Swift learning process interesting. It is used by many pros to develop highly renowned apps.
Students with no coding expertise can also use this app. It provides a blank canvas for coding to practice more and examine the code. Also, you can start coding from scratch. Its major limitation is that you can use it just for iPad, not for iPhone.
Buffer Code Editor
If you’re in search of a purposely-built development environment, then Buffer Code Editor is what you can call upon. Its customizable interface allows users to change between an array of themes.
The best thing is that this editor app is fully optimized for iPads as well as iPhones. Hence, you can perform several multitasking operations. It has syntax highlighting and supports connections to Google Drive, GitHub, SSH servers, BitBucket, SFTP, and Dropbox.
Code Server
This is an open-source project controlled by the developers of Coder. A large number of developers are using Coder Server to run VS code and access it via browser. VS code can run on any machine based on your requirement.
You can install it on a new or old machine. Once installed, use your iPad to link and start working. Beginning it with the –link command provides a dedicated URL, TLS, and authentication for accessing IDE out of the box.
Mimo
This is another high-rated coding app for iOS and iPadOS. It is useful for experienced coders and beginners to keep their momentum while learning new code. You can set limits for how much you wish to learn per day. You can also get points for achieving goals.
Its working is much similar to the Duolingo language. Based on your set goals, you can create customized lessons. Using this editor, you can use widely used coding languages and learning techniques.
Conclusion
So that’s all about the best code editors for iOS and iPadOS. While writing code with an iPad, you can use a native iOS app or use your iPad as a thin client to link with an IDE running on another server.
While coding on iOS, there are certain things that you should consider. For example, select a third-party keyboard that effectively works with your iOS device and other smartphones or tablets.
Generating random numbers in Python is a fairly straightforward activity which can be done in a few lines. There maybe many variations which you need to do ranging from decimal places, random numbers between a start and end number, and many more. We’ll go through many useful examples in this article.
The most basic way to generate random numbers in python is with the random library:
import random
num = random.random()
print( f"Random number between 0.0 and 1.0 ={num}\n")
Output as follows:
You’ll see that each time it is run it has a new random number.
Generating the same random number each time and why this matters
Sometimes, you may want to generate some random numbers, but then be able to generate the same random numbers each time. Now this may sound counter intuitive as the whole point of getting random numbers is so that, well, they are random. One scenario where you would like to regenerate the same random numbers is during testing. You may find some unusual behaviour and this is where you may want to replicate that behaviour for which you’l l need the same input. This is where you’d want to generate the same random number and you can do that in python using the seed function from the random library.
The idea behind the seed function is that you can think of it as a specific key which can be used to generate a series of random numbers which stems from a given key. Use a different seed and you’ll generate a different set of random numbers.
See the following example code which generates a random number between 1 and 0:
import random
random.seed(1)
for i in range(1,5):
num = random.random()
print( f"Random number between 0.0 and 1.0 ={num}\n")
Output as follows:
No matter how many times it is run, since the seed is the same each time, it generates the same numbers.
Python Random Number Between 1 and 10
Now that we know how to generate random numbers, how do you do it between two numbers? This is easily done in with either randint() for whole numbers or with uniform() for decimal numbers.
import random
num_int = random.randint(1,10)
print( f"Random whole number between 1 and 10 ={num_int}\n")
num_uni = random.uniform(1,10)
print( f"Random decimal number between 1 and 10 ={num_uni}\n")
Python Generate Random Numbers From A Range
Suppose you needed to generate random numbers from a range of data whether that be numbers, names or even a pack of cards. This can be done through selecting the random element in an array by choosing the index randomly. For example, if you had an array of 5 items, then you can randomly chose and index from 0 to 4 (where 0 is the index of the first item).
There is another and shorter way in python which is to use the random.choice() function. If you pass it an array, it will then randomly return one of the elements.
Here’s an example to randomly select a name from a list with both using the index (to show you how it works), and the much most efficient random.choice() library function:
import random
###### Selecing numbers from a range
names_list = [ "Judy", "Harry", "Sarah", "Tom", "Gloria"]
rand_index = random.randint( 0, len(names_list)-1 )
print( f"Randomly selected person 1 is = { names_list[ rand_index] }\n")
print( f"Randomly selected person 2 is = { random.choice( names_list) }\n")
And the output is different each time:
Generate Random String Of Length n in Python
If you want to generate a specific length string (e.g. to generate a password), both the random and the string libraries can come in handy where you can use it to create an easy password generator as follows:
import random, string
###### Create a random password
def generate_password( pass_len=10):
password = ""
for i in range(1,pass_len+1):
password = password + random.choice( string.ascii_letters + string.punctuation )
return password
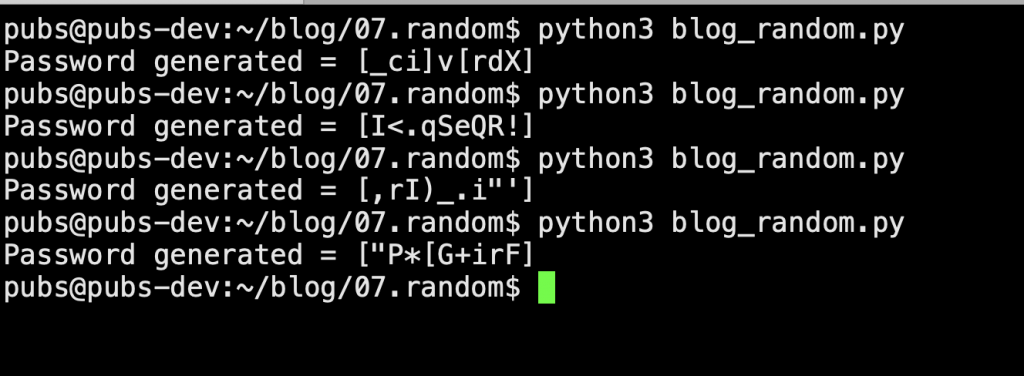
print( f"Password generated = [{ generate_password(10) }] ")
This will output a new password each time between square brackets:
If there are specific characters you want to include or exclude, you can simply replace the string.punctuation with your own list/array of specific characters to be included
Random Choice Without Replacement In Python
Suppose you wanted to randomly select items from a list without repeating any items. For example, you have a list of students and you have to select them in a random order to go first in a specific activity. In many programming languages you may need to generate a random list and remember the previously selected items to prevent any repeated selections. In the random library, there is a function called random.sample() that will do all that for you:
import random
#### Select unique random elements
students = ["John", "Tom", "Paul", "Sarah", "July", "Rachel"]
random_order = random.sample( students, 6)
print(random_order)
This will generate a unique list without repeating any selections:
In order to generate a date between two dates, this can be done by converting the dates into days first. This can be combined with the random.randint() in addition to the days of the date differences then adding back to the start date:
import random, datetime
#### Select a random date between two dates:
d1 = datetime.date( 2013, 2, 26 )
d2 = datetime.date( 2015, 12, 15 )
diff = d2 - d1
new_date_days = random.randint( 0, diff.days )
print( f"Random date is { d1 + datetime.timedelta( days=new_date_days ) }")
The output would be as follows:
Generate Random Temporary Filename in Python
A common need is to generate a random filename often for temporary storage. This might be for a log file, a cache file or some other scenario and can be easily done with the similar string generation as above. First a letter should be determined and then the remaining letters can be added with also numbers as well.
The random library has many uses from generating numbers to specific strings with a given length for password generation. Typically, these use cases sometimes have specialised libraries as there can be nuances (e.g for passwords, you may not want a repeating sequence which may be possible through random luck) which you can search for through pypi.org. However, many can be created with simple lines of code as demonstrated above. Send comments below or email me to ask further questions.
Subscribe
Not subscribed to our email list? Sign up now and get your next article in your inbox:
For some of your web apps you develop in python, you will want to run them on the cloud so that your script can run 24/7. For some of your smaller applications, you may want to find the right free python hosting service so you don’t have to worry about the per month charges. These web applications might be a website written in flask, or using another web framework, it might be other types of python apps that runs in the background and runs your automation. This is where you can consider some of the hosting services that have a free plan and are still very easy to setup.
To find the right hosting platforms that fits your needs, you want to consider a few things:
Ease of access to upload projects
What type of support they provide
What specifications that virtual server environment has to offer
One such new platform is called deta.sh. Deta is a free hosting service that can be used to provide web hosting for deploying python web applications or other types of python applications that run in the background.
The deta service, as of mid-2022, is still in the development stage and is expected to have a permanent free python hosting service so that online python applications can be setup and deployed quickly and easily. Deta is a relatively new service but is a service that is intended to compete with pythonanywhere, heroku, and similar services to run python on web servers. The service lets you host python script online without fuss directly from a command line, much like how you can check in code to github. Although it is new, it has the potential to be one of the best free python hosting there is in order to get your python online.
The platform provides you mini virtual environments (called ‘micros’) where you can host your python scripts. These can be separated into workspaces called ‘projects’ so that you can also more easily manage your environments. The way you can access/upload your code is with the command line through a password Access Token.
We will go through step by step how to run your python online. For this article, we will guide you on using deta to host a simple flask based web page so that you can have python as a webserver.
Signing up for Deta.sh
Deta.sh is effectively a cloud python hosting service which sits on top of AWS and allows you to deploy your python code into a virtual machine (called a deta micro), store files (called data drive) and also store data (called deta base). Unlike AWS or other hosting services, you can quickly host and run your script without going through the hassle of setting up server, security configurations etc.
The Deta.sh team offers the service for free in order to allow developers to monetize the solutions where deta.sh will be able to share some of that revenue. To date, there are no paid Deta.sh hosting plans for python hosting and no intention. So you can continue to run python code online forever.
To begin with, head over to the website https://deta.sh to first create an account.
Enter a unique username, password and email. The Email must be real in order to activate your account
Once you have submitted, go to your email and click on the verify link.
You will be taken to this “verification success” page. Here you can sign in, but also join the “Discord” channel. You can get any help very quickly from the community that’s there.
After you click on sign-in, enter the same username and password, and you will be taken to the default page where you will have the ability to “See My Key”
Click on the “See My Key” to see your secret password. You will only be able to see it once and will not be able to see it ever again.
This is what they project key will look like:
You need both the key and the project id.
Think of the key like a password and the “Project ID” as a password. When you want to access your deta.sh to upload programs, make changes, you will need to use your project key to access your space.
If you lose your project id/key, you will not be able to recover it. However, you can create a new one with Settings->Create Key option.
Create a new project key with Settings -> Create Key (this key you see on the screen has already been deleted!)
One thing I’d like to call out is the Project ID. This is the ID of this particular s[ace
If you have multiple programs which access deta.sh, it is best to have separate project keys. The reason is that if one of your keys are compromised, then you can simply just change that key and not have all your applications be affected.
Setting Up Your Remote Access For Deta.sh
We will first setup deta.sh in the command line interface so that you can communicate to your deta.sh space on the cloud.
You can do this with either one of:
Mac / Linux:
curl -fsSL https://get.deta.dev/cli.sh | sh
Windows:
iwr https://get.deta.dev/cli.ps1 -useb | iex
Once that’s done, what will happen is that there will be a hidden folder called $HOME/.deta that is created (specifically in the case of Mac / Linux). It’s in this directory that the deta command line application will be found.
You can type deta --help to check that the command line tool was installed correctly
Next, you will need to create an access token so that you can connect to your deta.sh account. For this you will need to create an access token. Go to your deta.sh home page (e.g. https://web.deta.sh/) and then go back to the main projects page.
Next, click on the Create Access token under settings
Once you create token, this will create an Access Token so that you don’t need to login each time.
Copy this Access Token and then, create a file called tokens in the $HOME/.deta/ directory. Steps for Mac/Linux are:
cd $HOME/.deta
nano tokens
You can then add the following json inside the tokens file:
{
"deta_access_token": "<your access token created above>"
}
Finally, you can install the python library that will be used to access the deta components with the deta library.
pip install deta
Have a Free Python Hosting Flask on Deta.sh
To create an environment to host your python code and have python web hosting, you need to create something called a “micro“. This is almost like a mini virtual server with 128mb of memory but will not be running all the time. They will wake up, execute your code, and then go back to sleep. Deta.sh is not designed for long running applications with heavy computations (use one of the public cloud providers for that!). Also, each micro has its own python online cloud private access.
To begin with, you can use the command deta new --python <micro name>. The <micro name> is the name to label the mini-virtual name.
The above command will create a directory called flask_test with a python script called main.py
The default code in the main.py is:
def app(event):
return "Hello, world!"
At the same time, this code will be uploaded to deta.sh. If you go to the dashboard page https://web.deta.sh/ you will see a sub-menu under the Micro menu. You may need to refresh your browser if you had it open.
You will notice that there’s also a URL for this deta micro which is the end point where your application output can be accessed. Think of this simply as the console output.
If you encountered any errors, in the command line, you can type deta logs to get an output of any errors from the logs.
To make a more useful application, we can create a flask application to show a more functional webpage. In order to do this, you will need to dell deta.sh to install the flask library. You cannot use pip install unfortunately, but instead you need to use the requirements.txt instead.
First, add flask into a requirements.txt file in your local directory. So your file should simply look like this:
#requirements.txt
flask
Then in your main.py code file, you add the following, again this is in your local directory
In order to now upload the changes to your micro, you will need to run the command deta deploy. This will upload the files requirements.txt and updates to main.py into your micro.
deta deploy
When executed, this should upload the code and install the libraries:
Managing Flask Forms On Free Python Hosting
Now that we have a simple static web page, we can create a more complex example where there’s a form that can be submitted. Using the weather API from openweathermap API, we can show the weather for a given location.
To get the weather data, we need to install two libraries pyowm and datetime. Hence, this will need to be added to requirements.txt.
#requirements.txt
flask
pyowm
datetime
Then for the code, the following can be updated in the main.py:
When the form is submitted from the / url, then the function def get_weather() is called to process the form. The variable that was passed, can be access through request.form['location'].
The above code works by first providing a form through the function def get_location() which generates a very simple form through HTML:
When the submit button is pressed, the form calls the /weather URL with the field location. Once called, then the python function def get_weather() is called upon which a call to OpenWeatherMap.org is made to get the weather data for the given location.
Conclusion
This is just a tip of the iceberg of what you can do with deta. You can also run scheduled jobs, run a NoSQL database, and have file storage as well. Contact us if you’d like us to cover these areas too.
The python await and async is one of the more advanced features to help run your programs faster by making sure the CPU is spending as little time as possible waiting and instead as much time as possible working. If ever you see a capable chef, you’ll know what I mean. The chef is not just following a recipe step by step (i.e. working synchronously), the chef is boiling water to cook the pasta , measuring the amount of pasta, chopping tomatoes for the pasta sauce until the water boils etc (i.e. the chef is working asynchronously). The chef is minimizing the time they are waiting idle and always working on a task. That’s the same idea with async and await.
For this tutorial, we will focus on python 3.7 as it has some of the more modern features of await and async. We will call out some of the differences for python 3.4 – 3.6.
What is async await in Python?
The async await keywords help to define in your program which parts need to run sequentially, and which parts may take sometime but other parts of the program can execute while this step completes. A modern example of this is that if you’re downloading a web page it may take a few seconds, while the download is happening you can execute other parts of your program.
How does async await work in Python?
Sometimes the best way to explain something is to show how you would achieve the same thing without the feature.
Continuing with the restaurant theme, suppose you are running a hamburger stall (you’re the waiter and the chef) and it is almost instant to collect payment for a customer and serve the final hamburger, but the most time consuming task is to cooking the beef patty which takes 2 seconds (one could only wish!).
See the below diagram:
Figure 1: Sequentially serving customers at a hamburger stall
In the above diagram:
Step 1: you would first get the order and collect the money from Customer 1
Step 2: you would then put a beef patty on the cook top and then wait for 2 seconds for the beef patty to cook. At the same time, Customer 1 is also waiting for 2 seconds.
Step 3: when the beef patty is cooked, you can then plate this onto a hamburger bun
Step 4: pass the final hamburger to Customer 1
Step 5: You would then start to serve Customer 2 (who has already been waiting 2 seconds for you to serve Customer 1). You can then repeat steps 2-4
With the above approach, Customer 1 would have their burger in about 2 seconds, Customer 2 approx 4 seconds, and then Customer 3 approx 6 seconds.
The equivalent code would be as follows:
import time, datetime, timeit
customer_queue = [ "C1", "C2", "C3" ]
def get_next_customer():
return customer_queue.pop(0) #Get the first customer from list
def cook_hamburger(customer):
start_customer_timer = timeit.default_timer()
print( f"[{customer}]: Start cooking hamberger for customer")
time.sleep(2) # It takes 2 seconds to cook the hamburger
end_customer_timer = timeit.default_timer()
print( f"[{customer}]: Finish cooking hamberger for customer. Total {end_customer_timer-start_customer_timer} seconds\n")
def run_shop():
while customer_queue:
curr_customer = get_next_customer()
cook_hamburger(curr_customer)
def main():
print('Hamburger Shop')
start = timeit.default_timer()
run_shop()
stop = timeit.default_timer()
print(f"** Total runtime: {stop-start} seconds ***")
if __name__ == '__main__':
main()
The code above is fairly straightforward. We have a list of customers that are queuing in the list customer_queue which are being looped under the def run_shop(). For each customer (get_next_customer()), we call cook_hamburger() to cook the hamburger for 2 seconds and wait for it to complete.
Running this code you would get the following output:
As expected, the total runtime for 3 customers is 6 seconds since each customer is served sequentially.
Cooking Hamburgers Asynchronously and coding the event loop manually
Instead of serving the customer and cooking the hamburger for each customer, you can obviously do some of the tasks asynchronously, meaning you can start the task but you don’t have to sit and wait, you can do something else. See the following diagram where the chef/waiter is serving multiple customers and cooking at the same time. It’s not explicitly shown here, but the chef/waiter is constantly checking on the status of the next task and if a task doesn’t require his/her attention they’ll move on to the next task. This process of always looking for something to do is the equivalent of the “event loop”. The Event Loop is a programming construct where the logic is to always look for a task to execute and if there’s a task which will take some time it can release control to the next task in the loop.
Figure 2: Example of how the event loop works in a real life example – the chef/waiter is always busy!
In the above example, the following is happening:
Step 1: you would first get the order and collect the money from Customer 1
Step 2: you would then put a beef patty on the cook top and then let it cook, then immediately move on to the next customer while the patty is cooking.
Step 3: you would first get the order and collect the money from Customer 2. You would also check if the first beef patty has completed cooking yet.
Step 4: you would then put another beef patty on the cook top and then let it cook, then immediately move on to the next customer while the patty is cooking.
…
Step 5: When any of the beef patties are done, you would plate it
Step 6: Pass the plated hamburger to the respective customer. Note, in the above example we’ve assumed it to be Customer 1, but it could be any customer depending on which beef patty cooked fully first.
Step 7: When any of the beef patties are done, you would plate it, and server
This is the equivalent of the event loop. The chef/waiter is constantly checking if it needs to serve the customer or check on the hamburgers which are cooking. When there’s a hamburger is placed on the stove and we need to wait 2 seconds, the chef/waiter moves to the next task and does not wait for the 2 seconds to complete. When the hamburger is done, it is then served to the customer.
How can this be done programatically? Glad you asked:
import time ,datetime, timeit
customer_queue = [ "C1", "C2", "C3" ]
hamburger_queue = []
def get_next_customer():
if customer_queue: return customer_queue.pop(0) #Get the first customer from list
return None
def start_cooking_hamburger(customer):
print( f"[{customer}]: Start cooking hamberger for customer")
hamburger = { "customer":customer, "start_cooking_time": timeit.default_timer(), "cooked":False}
hamburger_queue.append( hamburger )
def check_hamburger_status():
curr_timer = timeit.default_timer()
#Check if it's cooking, but release control
for index, hamburger in enumerate(hamburger_queue):
elapsed_time = curr_timer-hamburger['start_cooking_time']
if elapsed_time > 2: #2 second has passed for hamrburger to cook
print( f"[{hamburger['customer']}]: Finish cooking hamberger for customer. Total {elapsed_time} seconds\n")
del hamburger_queue[ index]. #delete from list to mark as done
def run_shop():
while customer_queue or hamburger_queue: #Event loop
curr_customer = get_next_customer()
if curr_customer: start_cooking_hamburger(curr_customer)
check_hamburger_status()
def main():
print('Hamburger Shop')
start = timeit.default_timer()
run_shop()
stop = timeit.default_timer()
print(f"** Total runtime: {stop-start} seconds ***")
if __name__ == '__main__':
main()
The output of the code is as follows:
Output running asynchronously – notice the runtime of 2 seconds compared to the 6 seconds in the synchronsous method.
So there’s a few things happening here:
There’s a new list called hamburger_queue[] which is keeping track of each hamburger that is being cooked
The event loop is the while customer_queue or hamburger_queue within the run_shop() function
We have a new function called start_cooking_hamburger() which helps to keep track of the task to cooking starting. Why is this needed? Well in the past we would simply wait for a given task. Now, since we are doing something else while we wait, we need to remember a few things to come back to the task
We also have a new function called check_hamburger_status() which checks the status of each hamburger being cooked (i.e. item in hamburger_queue[]), and if it is cooked (i.e. 2 seconds have passed), then it is considered complete
You may notice in the output that Customer 3 was in fact served before Customer 2. This is because that the execution order is not guarantee.
In the previous section we created an asynchronous version manually. Here’s the same outcome but written with the async await syntax. As you’ll notice it is very similar to the original synchronous version:
import time, datetime, time
import asyncio
import time, datetime, timeit
customer_queue = [ "C1", "C2", "C3" ]
def get_next_customer():
return customer_queue.pop(0) #Get the first customer from list
async def cook_hamburger(customer):
start_customer_timer = timeit.default_timer()
print( f"[{customer}]: Start cooking hamberger for customer")
await asyncio.sleep(2) # Sleep but release control
end_customer_timer = timeit.default_timer()
print( f"[{customer}]: Finish cooking hamberger for customer. Total {end_customer_timer-start_customer_timer} seconds\n")
async def run_shop():
cooking_queue = []
while customer_queue:
curr_customer = get_next_customer()
cooking_queue.append( cook_hamburger(curr_customer) ) #this returns a task only
#cooking_queue[] has all the async tasks
await asyncio.gather( *cooking_queue ) #Run all in parallel
def main():
print('Hamburger Shop')
start = timeit.default_timer()
asyncio.run( run_shop() ) #Start the event loop
stop = timeit.default_timer()
print(f"** Total runtime: {stop-start} seconds ***")
if __name__ == '__main__':
main()
Output as follows:
Let’s walk through the code:
Firstly, the async await is available from the library asyncio hence the import asyncio
There’s funny set of async keywords which precede the def run_shop() and the def cook_hamburger(customer) functions. In addition the run_shop() is no longer called directly, instead it is called with a asyncio.run( run_shop() ) function call. So here’s what is happening:
The asyncio.run() function is the trigger for the so-called event loop. It continues to run forever until all the tasks given to it are completed. You must pass it a function with the async def... prefix hence why run_shop() has the async prefix
In the async def run_shop() function call, the code iterates while there are customers in the queue to process, and then there’s a call to cook_hamburger(curr_customer) for each customer. A direct call to the customer does not actually call the function but instead creates a task to execute this. That is what the async tells the compiler – that when called directly, return a task.
At the end of the function code in def run_shop() there’s a call to function await asyncio.gather( *cooking_queue). There’s a few things going on here:
The await keywords indicates that you need wait for the work to complete but python can do something else in the meantime
The call to gather() actually executes all the tasks given to it as a parameter collectively as a group and then returns the results sequentially (please note that the order of the tasks being executed may be random)
The *customer_queue simply expands the list into a list of parameter items. So for example if customer_queue[] == [ '1', '2', '3'] then the gather( *customer_queue) would be the same as gather( '1', '2', '3').
When the await asyncio.gather( *customer_queue ) is called, the await keyword releases control to any activities that are pending and one of them would be to the calls to function cook_hamburger() which was added to the customer_queue list. Hence calls to cook_hamburger() would be triggered.
Within cook_hamburger() there is also an await asyncio.sleep(2). This simply waits for 2 seconds, however, it does not force the program to wait for the 2 seconds to complete, instead the await keyword releases python to do something else in the meantime. This is similar to step 3 in Figure 2 where the chef/waiter puts the hamburger on the grill, but then doesn’t wait for the 2 second but instead does something else (i.e. serve the next customer)
The asyncio.run() are new keywords as part of python 3.7. In older versions of python you may see the following but it is the same as simply running asyncio.run( run_shop() ) :
loop = asyncio.get_event_loop()
loop.run_until_complete(run_shop())
loop.close()
As you will notice, this is very similar to the synchronous code that covers Figure 1 above. This is the beauty of async/await
So remember, whenever there’s an await then that means python pauses at that point for that task to complete but then also releases python to do something else. That’s how the performance improvement occurs. In this example, the runtime of this is 2 seconds instead of the sequential 6 seconds!
Async Asynchronous Calling Another Async Function Code Example
Suppose you want t also call another async function once your first async function is completed – how do you go about this? Remember the rule, if you want to run something asynchronously, you have to use the await keyword, and that the function you’re calling has to be defined with async def ...
To continue with the restaurant theme, suppose that after the hamburger is cooked you ask an assistant to put the hamburger into a takeaway bag which takes 1 second. This is also another task that you need not ‘block’ and wait for it to complete. Hence, this action can be put into a function which is defined as an async. Here’s what the code can look like:
import time, datetime, time
import asyncio
customer_queue = [ "C1", "C2", "C3" ]
def get_next_customer():
return customer_queue.pop(0) #Get the first customer from list
async def cook_hamburger(customer):
start_customer_timer = timeit.default_timer()
print( f"[{customer}]: Start cooking hamberger for customer")
await asyncio.sleep(2) # Sleep but release control
end_customer_timer = timeit.default_timer()
print( f"[{customer}]: Finish cooking hamberger for customer. Total {end_customer_timer-start_customer_timer} seconds")
await put_hamburger_in_takeaway_bag( customer )
async def put_hamburger_in_takeaway_bag( customer):
start_customer_timer = timeit.default_timer()
print( f"[{customer}]: Start packing hamberger")
await asyncio.sleep(1) # It takes 2 seconds to cook the hamburger
end_customer_timer = timeit.default_timer()
print( f"[{customer}]: Finish packing hamberger. Total {end_customer_timer-start_customer_timer} seconds\n")
async def run_shop():
cooking_queue = []
while customer_queue:
curr_customer = get_next_customer()
cooking_queue.append( cook_hamburger(curr_customer) ) #Get each of the event loops
await asyncio.gather( *cooking_queue ) #Run all in parallel
def main():
print('Hamburger Shop')
start = timeit.default_timer()
asyncio.run( run_shop() ) #Start the event loop
stop = timeit.default_timer()
print(f"** Total runtime: {stop-start} seconds ***")
if __name__ == '__main__':
main()
The output would be:
See how once the hamburger is cooked (e.g. [C1]: Finish cooking hamburger for customer. Total 2.000924572115764 seconds), then immediately afterwards you have the [C1]: Start packing hamburger step but also gets called asynchronously.
Async Await Real World Example With Web Crawler in Python
One difficulty in learning Async / Await is that many examples provided simply provide the asyncio.sleep() as an example which is helpful to understand the concept, but not very helpful when you want to make something more useful. Let’s try a more complex example where you want to get some stock data from finance.yahoo.com and then, for that same stock, you also get the first 3 newspaper articles from news.google.com in the last 24 hours.
Now one thing you will realise is that await only works with functions that are defined as async. So you cannot call any function with await. Why? Well recall that when you call await you are expecting a function to return a task and not actually call the function, hence that function needs to be defined as async in order to tell python that it returns a task to be executed at the next available time.
Let’s see the synchronous version of the code:
import asyncio, requests, timeit
from bs4 import BeautifulSoup
from pygooglenews import GoogleNews
stock_list = [ "TSLA", "AAPL"]
def get_stock_price_data(stock):
print(f"-- getting stock data for {stock}")
data = {"stock":stock, "price_open":0, "price_close":0 }
stock_page = requests.get( 'https://finance.yahoo.com/quote/' + stock, headers={'Cache-Control': 'no-cache', "Pragma": "no-cache"})
soup = BeautifulSoup(stock_page.text, 'html.parser')
#<fin-streamer active="" class="Fw(b) Fz(36px) Mb(-4px) D(ib)" data-field="regularMarketPrice" data-pricehint="2" data-symbol="TSLA" data-test="qsp-price" data-trend="none" value="759.63">759.63</fin-streamer>
data['price_close'] = soup.find('fin-streamer', attrs={"data-symbol":stock, "data-field":"regularMarketPrice"} ).text
#<td class="Ta(end) Fw(600) Lh(14px)" data-test="OPEN-value">723.25</td>
data['price_open'] = soup.find( attrs={"data-test":"OPEN-value"}).text
return data
def get_recent_news(stock):
print(f"-- getting news data for {stock}")
gn = GoogleNews()
search = gn.search(f"stocks {stock}", when = '24h')
news = search['entries'][0:3]
return news
def print_stock_update(stock, data, news):
print(f"Stock:{ stock }")
price_change = 0
if int(float(data['price_open'])) != 0: price_change = round( 100 * ( float( data['price_close'])/float(data['price_open'])-1), 2)
print(f"Open Price:{data['price_open']} Close Price:{data['price_close']} Change:{price_change}% ")
print("Latest News:")
for news_item in news:
print( f"{news_item.published}:{news_item.source.title} - {news_item.title}" )
print("\n")
def process_stocks():
for stock in stock_list:
data = get_stock_price_data( stock )
news=[]
news = get_recent_news( stock )
print_stock_update(stock, data, news)
if __name__ == '__main__':
start_timer = timeit.default_timer()
process_stocks()
end_timer = timeit.default_timer()
print(f"** Total runtime: {end_timer-start_timer} seconds ***")
Output as follows:
So what’s happening here. Well, you are looping through two stocks TSLA and AAPL, and for each stock the following happens sequentially:
A call to data = get_stock_price_data( stock ) occurs in order to make a call to requests.get( 'https://finance.yahoo.com/quote/' + stock) to get the HTML page for the TSLA stock. Effectively, this page: https://finance.yahoo.com/quote/TSLA
Next we use BeautifulSoup() in order to find the HTML snippet that contains the stock price data for the opening price and the closing price:
After the call to yahoo is complete, then there’s a call to news = get_recent_news( stock ) which uses the module pygooglenews to get the latest google news. In fact we have used this function in our previous Twitter Botarticle.
Once this is all done, that output is printed out with the call to print_stock_update(stock, data, news)
Clearly this could be called asynchronously as we are looping each time for each stock, and then also the call to get the stock data is independent to getting the news data. However, one thing has to happen sequentially is the print_stock_update(stock, data, news) which has to wait for both the async calls to complete.
One wait to try is to simply call the website download with:
The reason is, as you may have guessed, is that the requests.get() is not created with the async def... construct and hence cannot be called asynchronously.
What you can do however is to use another ‘get’ web page module called httpx. This function is defined with async def... and can be called similar to requests. That same line would be re-written as:
Ok, that works well. However, but what about the GoogleNews() code. There is no such async version of this function, so how can this be called asynchronously? Well for this, you can actually wrap it around a new thread. A ‘thread’ is way to run a piece of code under the same CPU process but in a parallel. It warrants a whole separate article but for now you can think of it as finding a separate space to execute this independent of the current execution path. However, to execute this in a separate thread, there’s a bit more involved.
The code looks like the following:
### Original Version
def get_recent_news(stock):
print(f"-- stock news:getting stock data for {stock}")
gn = GoogleNews()
search = gn.search(f"stocks {stock}", '24h') #Slow code to run asynchronously
news = search['entries'][0:3]
print(f"-- stock news:done {stock}")
return news
### Asynchronous Version
async def get_recent_news(stock):
print(f"-- stock news:getting stock data for {stock}")
gn = GoogleNews()
search = await asyncio.get_event_loop().run_in_executor( None, gn.search, f"stocks {stock}", '24h')
news = search['entries'][0:3]
print(f"-- stock news:done {stock}")
return news
Here what’s happening is that firstly we are using the await keyword to call the gn.search() function which is now being called through this asyncio.get_event_loop().run_in_executor( .. ) function call. What’s happening here is that we are asking the asyncio module to get access to the event loop (that piece of code that continuously checks for tasks to be done) and then to run in a separate thread. The way it is called is that the parameters must be passed in separate to the function call and hence why the parameters are to be passed in after the function name itself. You will also notice that the whole function can now be defined as async def get_recent_news(stock)
How To Mix Asynchronous And Synchronous Code With Await Async in Python
Now the final problem to be solved is how do we call the two functions of get_stock_price_data( stock ) and get_recent_news(stock) to be run asynchronously, but then wait for both to finish, and THEN run the print. This is where these steps should all be grouped under one function. This is the trick to mix asynchronous and synchronous code.
In order to run a group of tasks in parallel as a group you use asyncio.gather(). However, if you want to execute a synchronous function when ALL tasks that were given to asyncio.gather() is complete, then you should wrap it in another asyncio.gather()
What is encouraging with this code, is that even though the call to get_web_data_A() and get_web_data_B() both sleep for 1 second, since they were doing that asynchronously, then the total runtime is still just a little over 1 second. This can be shown by the Calculate [0]... output. However, the problem is that the code still iterates each index sequentially, meaning, that index 0 is processed completely first, and once that’s done, then index 1 is processed. What we want instead is to run all the slow get_web_data_A() and get_web_data_B() first, and then run the code to calculate afterwards. This is where you need to first create the tasks for ALL the iterations, and then call gather() on all the tasks. See the following code:
Here, in the function async def run_all_2() when we loop, we do not call the blocking code await asyncio.gather... inside the for loop. Instead, we are adding all the tasks to call process(..) into a list called task_queue[], and then at the end of the for loop we are calling await asyncio.gather( *task_queue ) on all tasks in one go. Hence, the output is as follows:
You’ll notice that ALL the get_web_data_A() and get_web_data_B() are being called asynchronously, and then the calculate function is called on all the available data. Hence, the elapsed time for all the iterations is only 1 second, compared to the previous 2 seconds.
So what does this mean for our real world example for getting stock data from Yahoo and then calling Google News asynchronously, and then only printing the data once both are done? Well, the same principle applies. The code is as follows:
The key bit of code is in the async def process_stocks() which now iterates over each of the stocks, creates tasks, and then calls await asyncio.gather( *run_stock_list ) on all the stocks in one go, and then in the function process_stock_batch(stock) we have the asynchronous call to (data, news) = await asyncio.gather( get_stock_price_data( stock ), and then the synchronous call to print_stock_update(stock, data, news) once both web data is complete.
Conclusion
The await and async function is an incredibly useful feature of python which takes a bit of getting used to in order to understand the concept, but once you’ve got the hang of it, it can be incredibly useful to get an improve of the performance of your code by leveraging idle time where you are waiting for a task to complete. Remember to be sure about the sequencing and being mindful of whether you care to have a follow-up activity once that task is completed, or you can simply continue to execute.
This not easy to grasp as a beginner, but follow the example code above, and if you get stuck feel free to reach out through our email list below.
Twitter Bots can be super useful to help automate some of the interactions on social media in order to build and grow engagement but also automate some tasks. There has been many changes on the twitter developer account and sometimes it’s uncertain how to even create a tweet bot. This article will walk through step bey step on how to create a twitter bot with the latest Twitter API v2 and also provide some code you can copy and paste in your next project. We also end with how to create a more useful bot that can post some articles about python automatically.
In a nutshell, how a twitter bot works is that you will need to run your code for a twitter bot in your own compute that can be triggered from a Twitter webhook (not covered) which is called by twitter based on a given event, or by having your program run periodically to read and send tweets (covered in this article). Either way, there are some commonalities and in this article we will walk through how to read tweets, and then to send tweets which are from google news related to python!
Step 1: Sign up for Developer program
If you haven’t already you will need to either sign in or sign up for a twitter account through twitter.com. Make sure your twitter account has an email address allocated to it (if you’re not aware, you can create a twitter account with just your mobile phone number)
Next go to developer.twitter.com and sign up for the developer program (yes, you need to sign up for a second time). This enables you to create applications.
First you’ll need to answer some questions on purpose of the developer account. You can chose “Make a Bot”
Next you will need to agree to the terms and conditions, and then a verification email will be sent to your email address from your twitter account.
When you click on the email to verify your account, you can then enter your app name. This is an internal name and something that will make it easy for you to reference.
Once you click on keys, you will then be given a set of security token keys like below. Please copy them in a safe place as your python code will need to use them to access your specific bot. If you do lose your keys, or someone gets access to them for some reason, you can generate new keys from your developer.twitter.com console.
There are two keys which you will need to use:
API Key (think of this like a username)
API Key Secret (think of this like a password)
Bearer Token (used for read queries such as getting latest tweets)
There is also a third key, a Bearer Token, but this you can ignore. It is for certain types of requests
At the bottom of the screen you’ll see a “Skip to Dashboard”, when you click on that you’ll then see the overview of your API metrics.
Within this screen you can see the limits of the number of calls per month for example and how much you have already consumed.
Next, click on the project and we have to generate the access tokens. Currently with the previous keys you can only read tweets, you cannot create ones as yet.
After clicking on the project, chose the “keys and tokens” tab and at the bottom you can generate the “Access Tokens”. In this screen you can also re-generate the API Keys and Bearer Token you just created before in case your keys were compromised or you forgot them.
Just like before, generate the keys and copy them.
By now, you have 5 security toknes:
API Key – also known as the Consumer Key (think of this like a username)
API Key Secret – also known as the Consumer Secret (think of this like a password)
Bearer Token (used for read queries such as getting latest tweets)
Access Token (‘username’ to allow you to create tweets)
Access Token Secret (‘password’ to allow you to create tweets)
Step 2: Test your twitter API query
Now that you have the API keys, you can do some tests. If you are using a linux based machine you can use the curl command to do a query. Otherwise, you can use a site such as https://reqbin.com/curl to do an online curl request.
Here’s a simple example to get the most recent tweets. It uses the API https://api.twitter.com/2/tweets/search/recent which must include the query keyword which includes a range of parameter options (find out the list in the twitter query documentation).
curl --request GET 'https://api.twitter.com/2/tweets/search/recent?query=from:pythonhowtocode' --header 'Authorization: Bearer <your bearer token from step 1>'
The output is as follows:
{
"data": [{
"id": "1523251860110405633",
"text": "See our latest article on THE complete beginner guide on creating a #discord #bot in #python \n\nEasily add this to your #100DaysOfCode #100daysofcodechallenge #100daysofpython \n\nhttps://t.co/4WKvDVh1g9"
}],
"meta": {
"newest_id": "1523251860110405633",
"oldest_id": "1523251860110405633",
"result_count": 1
}
}
Here’s a much more complex example. This includes the following parameters:
%23 – which is the escape characters for # and searches for hashtags. Below example is hashtag #python (case insensitive)
%20 – this is an escape character for a space and separates different filters with an AND operation
-is:retweet – this excludes retweets. The ‘-‘ sign preceding the is negates the actual filter
-is:reply – this excludes replies. The ‘-‘ sign preceding the is negates the actual filter
max_results=20 – an integer that defines the maximum number of return results and in this case 20 results
expansions=author_id – this makes sure to include the username internal twitter id and also the actual username under an includes section at the bottom of the returned JSON
tweet.fields=public_metrics,created_at – returns the interaction metrics such as number of likes, number of retweets, etc as well as the time (in GMT timezone) when the tweet was created
user.fields=created_at,location – this returns when the user account was created and the user self-reported location in their profile.
curl --request GET 'https://api.twitter.com/2/tweets/search/recent?query=%23python%20-is:retweet%20-is:reply&max_results=20&expansions=author_id&tweet.fields=public_metrics,created_at&user.fields=created_at,location' --header 'Authorization: Bearer <Your Bearer Token from Step 1>'
Result of this looks like the following – notice that the username details is in the includes section below where you can link the tweet with the username with the author_id field.
Building on top of the tests conducted on Step 2, it is a simple extra step in order to convert this to python code using the requests module which we’ll show first and after show a simpler way with the library tweepy. You can simply use the library to convert the curl command into a bit of python code. Here’s a structured version of this code where the logic is encapsulated in a class.
import requests, json
from urllib.parse import quote
from pprint import pprint
class TwitterBot():
URL_SEARCH_RECENT = 'https://api.twitter.com/2/tweets/search/recent'
def __init__(self, bearer_key):
self.bearer_key = bearer_key
def search_recent(self, query, include_retweets=False, include_replies=False):
url = self.URL_SEARCH_RECENT + "?query=" + quote(query)
if not include_retweets: url += quote(' ')+'-is:retweet'
if not include_replies: url += quote(' ')+'-is:reply'
url += '&max_results=20&expansions=author_id&tweet.fields=public_metrics,created_at&user.fields=created_at,location'
headers = {'Authorization': 'Bearer ' + self.bearer_key }
r = requests.get(url, headers = headers)
r.encoding = r.apparent_encoding. #Ensure to use UTF-8 if unicode characters
return json.loads(r.text)
#create an instance and pass in your Bearer Token
t = TwitterBot('<Insert your Bearer Token from Step 1>')
pprint( t.search_recent( '#python') )
The above code is fairly straightforward and does the following:
TwitterBot class – this class encapsulates the logic to send the API requests
TwitterBot.search_recent – this method takes in the query string, then escapes any special characters, then calls the requests.get() to call the https://api.twitter.com/2/tweets/search/recent API call
pprint() – this simply prints the output in a more readable format
This is the output:
However, there is a simpler way which is to use tweepy.
pip install tweepy
Next you can use the tweepy module to search recent tweets:
import tweepy
client = tweepy.Client(bearer_token='<insert your token here from previous step>')
query = '#python -is:retweet -is:reply' #exclude retweets and replies with '-'
tweets = client.search_recent_tweets( query=query,
tweet_fields=['public_metrics', 'context_annotations', 'created_at'],
user_fields=['username','created_at','location'],
expansions=['entities.mentions.username','author_id'],
max_results=10)
#The details of the users is in the 'includes' list
user_data = {}
for raw_user in tweets.includes['users']:
user_data[ raw_user.id ] = raw_user
for index, tweet in enumerate(tweets.data):
print(f"[{index}]::@{user_data[tweet.author_id]['username']}::{tweet.created_at}::{tweet.text.strip()}\n")
print("------------------------------------------------------------------------------")
Output as follows:
Please note, that after calling the API a few times your number of tweets consumed will have increased and may have hit the limit. You can always visit the dashboard at https://developer.twitter.com/en/portal/dashboard to see how many requests have been consumed. Notice, that this does not count the number of actual API calls but the actual number of tweets. So it can get consumed pretty quickly.
Step 4: Sending out a tweet
So far we’ve only been reading tweets. In order to send a tweet you can use the create_tweet() function of tweepy.
client = tweepy.Client( consumer_key= "<API key from above - see step 1>",
consumer_secret= "<API Key secret - see step 1>",
access_token= "<Access Token - see step 1>",
access_token_secret= "<Access Token Secret - see step 1>")
# Replace the text with whatever you want to Tweet about
response = client.create_tweet(text='A little girl walks into a pet shop and asks for a bunny. The worker says” the fluffy white one or the fluffy brown one”? The girl then says, I don’t think my python really cares.')
print(response)
Output from Console:
Output from Twitter:
How to Send Automated Tweets About the Latest News
To make this a bit more of a useful bot rather than simply tweet out static text, we’ll make it tweet about the latest things happened in the news about python.
In order to search for news information, you can use the python library pygooglenews
pip install pygooglenews
The library searches Google news RSS feed and was developed by Artem Bugara. You can see the full article of he developed the Google News library. You can put in a keyword and also time horizon to make it work. Here’s an example to find the latest python articles in last 24 hours.
from pygooglenews import GoogleNews
gn = GoogleNews()
search = gn.search('python programming', when = '12h')
for article in search['entries']:
print(article.title)
print(article.published)
print(article.source.title)
print('-'*80) #string multiplier - show '-' 80 times
Here’s the output:
So, the idea would be to show a random article on the twitter bot which is related to python programming. The gn.search() functions returns a list of all the articles under the entries dictionary item which has a list of those articles. We will simply pick a random one and construct the tweet with the article title and the link to the article.
import tweepy
from pygooglenews import GoogleNews
from random import randint
client = tweepy.Client( consumer_key= "<your consumer/API key - see step 1>",
consumer_secret= "<your consumer/API secret - see step 1>",
access_token= "<your access token key - see step 1>",
access_token_secret= "<your access token secret - see step 1>")
gn = GoogleNews()
search = gn.search('python programming', when = '24h')
#Find random article in last 24 hours using randint between index 0 and the last index
article = search['entries'][ randint( 0, len( search['entries'])-1 ) ]
#construct the tweet text
tweet_text = f"In python news: {article.title}. See full article: {article.link}. #python #pythonprogramming"
#Fire off the tweet!
response = client.create_tweet( tweet_text )
print(response)
Output from the console on the return result:
And, most importantly, here’s the tweet from our @pythonhowtocode! Twitter automatically pulled the article image
This has currently been scheduled as a daily background job!