For any program to be useful, you need to be able to take data in. There are many ways of doing that, and you need to decide which way works best for you in a given situation. Data can be obtained from various sources such as user inputs, files such as csv, text, excel files, images, etc.
Python3 is a very flexible programming language that has the support of numerous libraries and its functions that offers us many ways using which we can get the data. In this post, we are going to read about multiple ways using which we can get the data input in Python 3.
Method 1: Getting data from user input using input() function
To get input from the user, Python 3 offers us a built-in function named as the input() function. This function is an updated version of raw_input() that was used earlier in Python 2. input() function helps us to read data from the user input via the keyboard. When the input() keyword is encountered in the program upon execution, the program flow halts automatically asking the user to enter some values using the keyboard.
As soon as the user passes the data and hits the enter key, the data gets saved to the program at some memory location. One interesting feature of Python 3 is that it automatically interprets the type of data that the user passes inside the input() function as ‘string’ type unlike other programming languages like C, C++, Java, where we have to specifically mention the data type for the data which we want to read in our system.
A sample Python3 code to get data from a user using the input() function
name = input ("Enter your name : ")
print("Name entered by the user is: ", name)
# printing data type of input value
print ("Data type of name variable is: ", type(name))
Output:
taking user input using input() function
Working of above code:
In the above-given code snippet, the user is asked to enter his name using the input() function, when the program runs, the executed program halts upon reaching the input() function and asks for name, when the user puts his name and hits ENTER key, the program starts to run again and the value is stored inside name variable. Later we print the value stored inside the name variable and its data type. As discussed earlier, data types comes out to be as string.
Method 2: Taking data input using the command line
In our previous example, if we observe we have taken input from the user when the program was in execution. In this section, we will be having a look at another data input method where we will take input from the command line before our code gets executed. For achieving this, we will be using the command line arguments and the sys module to take data inputs and will be displaying the sum of two numbers. Let’s have a look at the code snippet:
import sys
# printing the list of all the arguments passed on command line
List_args = sys.argv
print(List_args)
# printing the type of the arguments
print (type(sys.argv[0]))
print (type(sys.argv[1]))
# first number
a = sys.argv[1]
# second number
b = sys.argv[2]
print("The sum of both the numbers is: ", int(a) + int(b))
Output:
Working of above code:
In the above written code, we have written a code inside a file named a.py . Inside the file, we import the sys module and use the sys.argv atrribute to print the list of arguments passed on the command line. As can be observed, the first argument will always be the name of the file itself and later the data we want to pass as the arguments. You can use the argparse module to do validation on the inputs.
Also, the data passed is always read in form of string so to add these two numbers in form of string we need to typecast them into integers and then display their sum. You can also have a look at the article about the Click module to see an alternative approach to include command line interfaces.
Method 3: Taking data input using stdin
We can even use the stdin attribute present in the sys module to take data inputs directly from the command line. stdin stands for standard input and it is a standard file-like object using which we can read data inputs. One point to always keep in mind is that it adds up a new line character when we hit the enter button to execute at the end of each sentence. So, we can use the rstrip() function to remove the new line character (‘\n’) from the end. Let’s see a code snippet:
# importing the sys module
import sys
for i in sys.stdin:
print("data entered by user is: ", i.rstrip())
if i.rstrip() == 'q':
break
print ("Program ended successfully")
Output:
taking data input using sys.stdin
Working of above code:
Using sys, stdin, we can read data from user input indefinitely until user stops the execution, so to avoid that we’ve use a conditional expression saying when the user presses ‘q’ button the program will terminate successfully otherwise user can enter data as many times they want.
Method 4: Taking data input using fileinput module
Like we used sys.stdin in the previous section, we can also use the fileinput module to get data from users. As fileinput.input() acts as a stream and it can be used to read data inputs from multiple files as well using a loop. A simple use-case to read data input provided by user can be written as:
# importing the fileinput module
import fileinput
for i in fileinput.input():
print("data entered by user is: ", i.rstrip())
if i.rstrip() == 'q':
break
print ("Program terminated successfully")
Output:
taking data input using fileinput module
Method 5: Taking data input from files
Another common way to get user data is to read it from a file. It is really a convenient way to read a large amount of data in a quick time. The file can be available in various formats like .csv files, .txt files, .json files, .xls files, etc. Python offers us the support of different libraries that helps us to parse data from these files efficiently. In this section, we will see a code to read data from a file.txt file using file handling principles of Python.
Content inside a sample file.txt file
with open("file.txt", "r") as f:
print(f.read())
Output:
reading the data input from the file
Working of code:
In the above-written code, we first wrote some content inside a sample .txt file, and then we read it using file handling concepts. We opened the file in read mode and read the content inside the file use the f.read() method. It can be verified after matching the content in the file and the output we get on the terminal.
Conclusion
We all understand the importance of taking data inputs and thus in this blog post, we saw some of the common methods using which we can read data inputs from the user in Python3.
Someone gave you a bunch of data in a spreadsheet, and you want to analyze it programmatically. If setting up a database for this seems like a daunting task to you, then don’t worry. In this article, we’ll learn how you can directly access data from your Google Sheets and use it as your database using Python.
To use Google Sheets as our database, we need three things – a Google Sheet where our data is stored, a Python script to read the data, and an API service to connect our Python script with the Google Sheet. Using the API service, we can access all the worksheets in the workbook, get all the data, insert new data, update, and delete the existing data, all in real-time. We will cover all the things you need to work with data in detail.
With just a few configurations and built-in functions, we can achieve the power of a database. We don’t need to learn database and SQL queries separately. So, let’s dive in and learn how it works.
Part 1: Creating the API Service
Step 1: The first thing we need to do is to go to the Google Developers Console. We will see a page like the following.
Step 2: Next, click on the My First Project dropdown at the top left. A pop-up will appear. Click on New Project. Now, give your project a name, like google-sheets-tutorial. Then, click on create.
Step 3: After creating a project, you will be redirected to the homepage, and you will see a notification. Click on Select Project for the project you have just created. In the dashboard, you will see a message that you have no APIs to use yet. We need to enable two APIs – one for Google Drive and another for Google Sheets to access Google Sheets from our Python script. So, click on the API Library.
On the Library page, search for Google Drive API. Click on it and then enable it.
Step 4: Repeat the same for Google Sheets API. Next, we need to add credentials. From the homepage sidebar, click on Credentials. Click on Create Credentials and select Service account.
Enter the details for your service account. Provide a name and description. The email will be generated based on the name. We will need the email later on.
Step 5: Next, grant access to the project. For the role, select Project and then select Editor. Finally, click on Done.
Step 6: Now, we will see there are still no API keys. To add that, click on Manage service accounts.
Now, click the three dots under Actions and click on the Create key option.
Select JSON and click create. This will download a JSON file to your computer. Rename this file as credentials.json. With this, we are done with creating the API service.
Part 2: Creating the Google Sheet and making it accessible
Step 1: Create a Google Sheet like the following. I have named it User Details and added two Sheets: Sheet 1 and Sheet2. Sheet1 has information about the User Name, Age, and Address.
Similarly, Sheet2 has information about the User Name and Occupation.
Step 2: Next, share this Google Sheet to make it accessible from Python script. Open the credentials.json file we downloaded earlier and copy the value of client_email from the file. Now on Google Sheets, click on the Share button and paste the email. Make sure that it is given Editor access, and then send. Now, we are ready to access this Google Sheet from our Python script.
Part 3: Creating the Python Script
Step 1: Make sure that you are using Python 3. If you are using Python 2, the syntax may vary. Now, to access the Google Sheet, first, we need a Python library called gspread. If it is not already installed, go to your command line (or terminal if you are in a Unix system) and type the following.
pip install gspread
Step 2: Once gspread is installed, create a folder in the directory of your choice and name it python-tutorial (or anything you like). Move the credentials.json file into this folder and create a main.py inside it. We will now write our Python script in this file.
The first thing to do here is import gspread and connect to the Google Sheet. Use the following snippet of code to do so.
The credentials.json has all the details related to our service account. Using this and gspread, we connect to our service account and store it in the variable gc. Now we can pass the name of our Google Worksheet User Details to gc.open to access it.
We have two worksheets. To access the first worksheet, we can do the following.
worksheet = workbook.sheet1
Part 3a: How to Read Data From Google Spreadsheets
To access the records, we can write the following.
print(worksheet.get_all_records())
Run main.py, and we get the result back as a list of dictionaries.
We can write the following to get the result back as a list of lists.
print(worksheet.get_all_values())
To read the first row of the Google Sheet, we can write the following.
print(worksheet.row_values(1))
Notice that the row index starts at 1 instead of the traditional indexing of 0 in programming. If 0 is provided as an argument to the row_values function, it will throw an error. We can do the same thing with worksheet.col_values to get the column values of our choice.
To access the value of a particular cell, we can use the get method with the cell name as the argument.
print(worksheet.get('A2'))
This will print the content of the A2 cell as a list of lists.
We can also get contents from a cell range. For instance, to get the details for the first user, we can write the following.
print(worksheet.get('A2:C2'))
Part 3b: How to Add Rows to Google Spreadsheets
We can insert new data at a row of our choice using the insert_row method. Here we need to pass the user details and the row number as an argument.
Part 3c: How to Update Existing Rows on Google Spreadsheets
We added the age of Sadio age as 60. Suppose we need to update this to be 65. We can use the update_cell method to do this. We need to pass the row number, column number, and the updated value as an argument. The age of Sadio is in row 9 and column 2. So we write the following code.
worksheet.update_cell(9,2,65)
Check back in the Google Sheet, and you will see that the age has been updated to 65.
Part 3d: How to Delete Data on Google Spreadsheets
Now, suppose we want to remove the record for Sadio. We use the delete_rows method and pass the row number as an argument.
worksheet.delete_rows(9)
The record at row 9 will now have been deleted.
Part 3e: How to Access Data From All Google Worksheets
We created two worksheets in our Google Sheet. We have learned the basics of accessing data from a single worksheet. Let us now look at how we can deal with multiple worksheets. The following code snippet will loop through all the worksheets and then fetch data from all the rows in each of the worksheets.
import gspread
gc = gspread.service_account(filename='credentials.json')
workbook = gc.open('User Details')
def format(data):
for i in range(len(data)):
print(data[i] + '\t' + '|', end=" ")
print('\n')
def get_worksheet_details(worksheet):
records = worksheet.get_all_values()
print('\n--------------------------------')
format(records[0])
print('\n--------------------------------')
for record in records[1:]:
format(record)
for i in range(len(workbook.worksheets())):
print('Worksheet ' + str(i+1))
worksheet = workbook.get_worksheet(i)
get_worksheet_details(worksheet)
print('\n\n')
len(workbook.worksheets()) will get the total number of worksheets, and then we loop through each of the worksheets. Previously, we used workbook.sheet1 to access the first sheet. Now, we achieve the same using workbook.get_worksheet(i). This will help us get the worksheet number dynamically. The two functions are used just for formatting purposes. The result of this program will be the following.
And there you go, you can now have a complete database in your Google Sheets without the hassle of setting it up and learning all the SQL queries.
Further Notes
We accessed the Google Sheet using the name of our sheet. We can also do the same by using a unique key for our sheet. To learn about how to do that, please check out this awesome video.
To learn in even more depth about what gspread can do, you can read the documentation.
Managing lists (or arrays as known in other languages) in python is a common task where you often need to take a section from the list – e.g. a slice of the list. This is where slice() can be used to take a section of the list. There are several ways to do this, read on to find out more.
In this article you will start with the basics of the slice() function. You will learn about the data types supported by slice() function and the parameters required by slice() function. Further you will learn with example how to extract sub-strings from a string, how to extract a sub-list or sub-tuple from a list or a tuple. You will also learn about an alternative to slice to extract sub-strings.
Slicing in Python
After you have gone through the fundamentals and practised the example with confidence, there are many real world problems where you can use slice().
Getting started with slice()
slice() function
If you take the idea of a loaf of bread, you never eat the whole loaf in one go, you would either cut it into individual slices or take a portion of the bread. slice() function in python exactly does the same. It is a built-in function that returns a section of the object. Slice may be used to extract sub-string, sub-lists, or sub-tuples from a given string, lists, or tuples.
Data Types supported by slice()
Data types which are sequence of objects are supported by slice(). Such data types are string, list, tuple, range, and bytes. Along with data types following the sequence protocol, objects that uses dunder methods like _ _getitem_ _() and _ _len_ _() can also be sliced using slice().
NOTE: Dunder methods is a core python feature, rare in other programing languages. It is used to emulate the functionality of built-in types to a user-defined object. The name comes from double underscores used in suffix and prefix of the methods. It is also called “magic method”.
Parameters required by slice()
The parameters that are required by slice() function are generally called slice notation. They are start, stop, and step.
start: An integer index value which represents from where the slicing of the object starts. It is an optional parameter.
stop: An integer index value which represents from where the slicing of the object ends. The element at this index is excluded from the slice. It is mandatory parameter.
step: An integer value indicating the number of steps(indices) skip while traversing from start index to stop index. It is also an optional parameter.
NOTE: Optional parameters like start and step are defaulted to when those value are not provided.
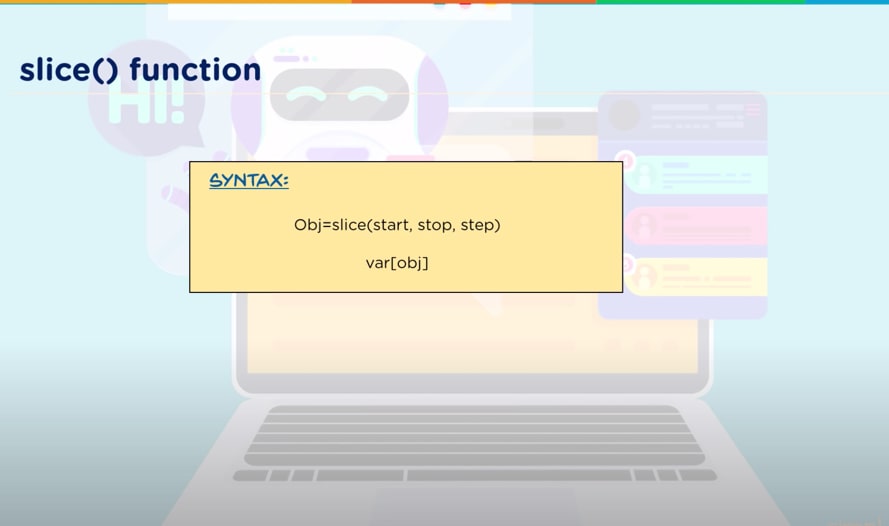
SYNTAX
slice(stop)
slice(start, stop, step)
Executing the above syntaxes returns a sliced object which is in the range of the parameters provided. Let us learn this with an example.
Example 1: Creating the slice object
# [Insert to example1.py file]
# Providing only stop as the argument
object1 = slice(4)
print(object1)
print(type(object1))
# Providing values to all slice notations.
object2 = slice(1, 6, 2)
print(object2)
print(type(object2))
OUTPUT
Creating slice object
From the output you can see that object1 and object2 are objects of slice class, or simply slice objects.
From the above example you might have been able to create a slice object. Further you will learn how to use the slice object to extract sub-strings, sub-list, or sub-tuple from given string, list, or tuple.
Example 2: Using slice object to extract substring
String is the most common data type used in Python. It is used to store characters. Each character in a string data type is indexed. As such, each characters can be individually accesses using its index value.
Indexing of a string
In the above figure you can view a word ‘BANANA’. In Python it can be assigned to a variable, making it a string type variable. When used len() function the result for this string will be 6. Simply, the total number of characters or letters present in the word ‘BANANA’. len() function is used to calculate the length of a string or the number of characters in a string. Empty space is also considered as a character.
Index is simply an address in the memory location. Whenever a variable is created a memory is allocated in the working memory of a device. Using the indexes you can access each characters. For example if the word ‘BANANA’ is stored in a variable named Fruit, then Fruit[1] will result in ‘A’.
Negative indexing
Indexing in python goes both ways either positive or negative. You can access characters even using the negative indexes as the figure above. Negative indexing is useful when you aren’t known about the total length of the character and want to quickly access the last character.
# [Insert to example2.py file]
# Extract substring from a given string
website = 'pythonhowtoprogram.com'
# stop = -4
# Using negative index
slice_object = slice(-4)
print(website[slice_object])
# start = 1, stop = 6, step = 2
# Using positive index
slice_object = slice(1, 6, 2)
print(website[slice_object])
OUTPUT
Sub-string using slice object
Example 3: Using slice object to extract sub-list
List is collection type data-type. It allows you to place multiple values or item in a single variable. Such values that are inserted in a list are called list constants. A list is surrounded by square brackets and list elements or list constants are separated by commas. List is a mutable data-type. It means that elements within the list can be changed. Each element of list has individual indexes, similar to the string indexes mentioned above. You can access the elements using the indexes.
Elements in the list are ordered. When new element is added in a list, it is added to the end of the list.
# [Insert to example3.py file]
list1 = ['P', 'y', 't', 'h', 'o', 'n','h','o','w']
# Using Positive index
# stop = 3
slice_object = slice(3)
print(list1[slice_object])
There is also a more straightforward way to use slices which avoids creating or using the slice object which is to use the square bracket notation. However, you cannot uses steps in this form. This should still help in most of your scenarios.
The idea is to use [<start>:<end>] notation. The start and end number can be either positive or negative – much like slice. Here are several teamples
a = [22, 44, 55, 66, 77, 88]
print( a[0:4] ) #Print the first 5 items
print( a[:4] ) #Print the first 5 items - 0 is default
print( a[1:] ) #Print all skipping item 1
print( a[-1:] ) #Print just the last element
print( a[-2:] ) #Print the last 2 elements
print( a[:-1] ) #Print all items excluding last item
Airtable has proven to be a one-stop solution to automate and manage business processes. It provides the usability of a database in a much simpler spreadsheet familiar operations. Airtable has a compelling and intuitive GUI interface to perform the CRUD operations in your data table. But for you power users, it has also exposed its API. This how-to guide will focus on how you can set up your Airtable account, access the API keys, and perform basic CRUD operations over the API using Python3 scripts.
Getting Started with Airtable
The core functionality provided by Airtable is the spreadsheet-like table, which stores multiple formats of data. Each column in the table is termed field, and each row in the table is termed record. Records are all the data that are associated with a particular field. To know more about Airtable, do follow this step by step guide.
On the top right corner of the homepage, click the “Sign Up” button.
Airtable homepage
On the sign-up page, you have two options to create your account. You can either click on the “Sign up with Google” button to create the account using your existing Google credentials or fill the sign-up form. In the sign-up form, enter your first name, last name, email address, and password in their respective fields. Next, click the “Sign up for free” button.
Airtable Sign up form
Click on “Continue” on the Welcome page.
On the “Tell us a bit about yourself” pop-up window, select your options based on your preference, requirement, experience, and intend for using Airtable.
On the “Let’s set up your workspace” pop-up window, enter a workspace name. You can also invite your teammates from this window to collaborate in the workspace. Alternatively, you can skip this process by clicking on the “Skip” button.
Follow along with the walkthrough video to explore the product, or you can skip it.
Congratulations!! You have successfully created your Airtable account. Now you can explore the Airtable interface for your intended purpose.
Airtable starting interface
The tables where you store data and perform operations are termed “Base”. Airtable provides you with some default base templates for getting you started quickly on your task. Based on your requirement and business need, you can select among the listed default base templates: Expense Tracking, Nonprofit program management, Inventory Tracking, Simple application tracker, and Business Development CRM. You can also create your custom table base by clicking on “Add a base”.
Step 2: Accessing your Airtable API key
Airtable has exposed its API to perform system functionalities beyond the product GUI. You can use the Airtable API to perform the four significant actions:
To retrieve records from your Airtable base.
Add new rows (records) to your table fields.
Edit the existing rows (records) in your table fields.
Delete rows (records) from your table fields.
Airtable APIs complies with the Representational State Transfer (REST) semantics. It supports JSON with UTF-8 encoding. The APIs can be used using any REST client browser or cURL tool. For developing custom applications or scripts on top of the Airtable, programming language HTTP libraries can be used. For example, in Python, ‘requests’ can be used to work with the APIs.
NOTE: Airtable API has a request limit of 5 requests per second, per base.
The Airtable APIs use token-based authentication to authenticate and authorize you to perform the API actions. You can generate an API key that identifies and validates you as an authentic and authorized user. You will have the same privilege and authority as to your account. Follow these steps to access the API key:
On the top right corner of your main Airtable interface, click on your account avatar icon.
From the drop-down, click on “Account”.
User account drop-down
From the “Account Overview” page, click on the “Generate API key” button.
Generating the API Key
A secret-key will be generated. Click on the secret-key box to view your API key. Secure the API key and use it while accessing the Airtable API. You can also delete and regenerate the API key.
Generated API Key
Step 3: Accessing your Base ID
Base ID is another mandatory parameter that is required while working with the Airtable APIs. Base ID is a unique identifier for your base. The API actions available for each base are unique. Thus Base ID determines the actions that are available when using the Airtable APIs. Follow these steps to access the Base ID for your base.
Click on your desired base. For this example, we will be using the default base template “Expense Tracking”.
Opening the default base template
Your default base template window opens. The table consists of dummy fields and records. You can customize these tables and views as per your preference. Click the “HELP” button at the top-right corner of this window. From the drop-down, select “API documentation”.
Selecting API documentation
An interactive API documentation window opens. This API documentation is unique for each base. In the introduction section of this document, the Base ID is present in a green text color formatting.
Accessing the Base ID from the API documentation
Using the Airtable Python Wrapper
A prevalent concept in object-oriented programming is “DRY”, short for “Don’t Repeat Yourself”. As such, python incorporates decorators, also known as wrappers, that provide additional functionality and processing capability to an existing function. Following the principle of “Not reinventing the wheel”, we will be using a wrapper called Airtable Python Wrapper. It was released under the MIT license by Gui Talarico.
Step 1: Installing the Airtable Python Wrapper
Create a new folder named “Airtable” as your main working directory. Create a file named main.py. Open the Terminal (Linux / Mac), Command Prompt (Windows), or Integrated Shell in any Integrated Development Environment (IDE).
We will be using PIP (Package Installer for Python) to install this wrapper.
NOTE: Make sure you already have installed Python 3 in your system.
Insert the following code in your Terminal (Linux / Mac), Command Prompt (Windows), or Integrated Shell in any Integrated Development Environment (IDE).
[Shell]
pip3 install airtable-python-wrapper
OUTPUT
Installing the airtable-python-wrapper from CLI
You need to install the ‘requests’ module of python. So install the request using PIP by inserting the following code in your command line terminal.
[Shell]
pip3 install requests
Step 2: Using Airtable Python Wrapper
Open your main.py file using an IDE. Insert the following code.
#[insert to main.py]
import os
from pprint import pprint
from airtable import Airtable
base_key = 'Base_Key' # Insert the Base ID of your working base
table_name = 'Table_Name' #Insert the name of the table in your working base
api_key = 'API_Key' #Insert your API Key
airtable = Airtable(base_key, table_name, api_key)
print(airtable)
NOTE: In the above code, base_key, table_name, and api_key are the Base ID, the table’s name in your base, and your API key, respectively. All these arguments are string so needs to be enclosed in single or double inverted commas.
[Shell]
python3 main.py #Execute the main.py python file
OUTPUT
A successful response from the API
Step 3: Viewing the records
In our example base, there are eight fields (columns) with three records (rows). Using the following code, we will be receiving the first two records (rows) from the base. Here “pprint” has been used to print the JSON data in a structured order.
[insert to main.py]
pages = airtable.get_iter(maxRecords=2)
for page in pages:
for record in page:
pprint(record) #pprints short for pretty print, prints the data in a structured format
[Shell]
python3 main.py #Execute the main.py python file
OUTPUT
Response JSON data including two records
Besides each field’s records, the received JSON response also consists of the date and time-stamp when the data was inserted in the table.
Step 4: Searching for records
The most frequent operation that we perform on any data records is the search. A ‘search’ function is defined in the wrapper, which takes parameters to search fields for any specific record. In this example, we will be first searching in the Category field for any record consisting of “Health & Personal Care”. When the search is complete and if the query matches with any record, it displays all the fields and records associated only with the “Health & Personal Care” category. If no record is found, an empty list is printed.
#[Insert to main.py]
records = airtable.search('Category', "Health & Personal Care")
pprint([r['fields'] for r in records])
[Shell]
python3 main.py #Execute the main.py python file
OUTPUT
Displaying records according to the search query
Step 5: Sorting the records
With tables consisting of large numbers of rows, it is vital to change the rows’ order. In the default base template, the dummy data has Maritza records followed by two records of Quinns. In this example, we will sort the data in the reverse order.
#[Insert to main.py]
records = airtable.get_all(maxRecords=3, sort=[("Who Paid?", 'desc')])
pprint(records)
[Shell]
python3 main.py #Execute the main.py python file
OUTPUT
Sorting the records
Step 6: Deleting the records
Data are volatile and are constantly changing. There is a constant need for updating data. There are multiple circumstances in which rows need to be removed from the table. Here in our example, we have three records. Using the API, we will be removing the top entry in the base.
The initial status of the base
#[Insert in main.py]
rec = airtable.get_all()[0]
airtable.batch_delete([rec['id']])
[Shell]
python3 main.py #Execute the main.py python file
OUTPUT
Topmost record deleted
Step 6: Inserting new records
As mentioned earlier, data are in a continually changing state. It is more important to keep a record for new data on a priority scale than deleting an out-dated one. In this example, we will insert a new record to the base.
#[Insert in main.py]
airtable.insert(
{'Category': 'Interior Decor',
'Date & Time': '2015-11-06T14:22:00.000Z',
'Notes': 'A cute blue cactus with golden spines, will go great in '
'the dining room.',
'Short Description': 'Cactus',
'Total': 11.5,
'Who Paid?': 'Maritza'})
[Shell]
python3 main.py #Execute the main.py python file
OUTPUT
A new record included
In a real-case scenario, it is less likely that you will be inserting only a single record at the time. There will be a need to add multiple records in a single batch. In the next example, you will learn how to insert multiple records.
#[Insert in main.py]
airtable.batch_insert([{'Category': 'Interior Decor',
'Date & Time': '2019-11-06T14:22:00.000Z',
'Notes': 'A wall painting for the hall.',
'Short Description': 'Wall painting',
'Total': 20.5,
'Who Paid?': 'John'},
{'Category': 'Kitchen Appliances',
'Date & Time': '2018-01-06T14:22:00.000Z',
'Notes': 'A five in one mixer and jucier set.',
'Short Description': 'Multi-purpose mixture',
'Total': 30.5,
'Who Paid?': 'Bob'},
{'Category': 'Electronics',
'Date & Time': '2019-01-06T14:22:00.000Z',
'Notes': 'A philips Smart LED TV',
'Short Description': 'Smart LED TV',
'Total': 100.5,
'Who Paid?': 'Martha'}])
[Shell]
python3 main.py #Execute the main.py python file
OUTPUT
Three new records added
Ending Remarks
I hope you were able to follow along with this step-to-step How-to guide. By now, you might have got a much deeper understanding of the Airtable as a product and the various operations you can perform upon. After confidently working with these CRUD operations using the Airtable API, you can excel deeper. Initially, try on your own by changing the parameters and variables from the above example. Subsequently, excel through the Airtable API documentation, Airtable Python Wrapper documentation, and other resources to build your expertise over Airtable.





























 when those value are not provided.
when those value are not provided.